
Finding the most similar sentence(s) to a given sentence in a text in less than 40 lines of code 🙂
In this Python code of 40 lines we share with you a simple machine learning task using linear algebra.
In Machine Learning we often apply some linear algebra methods to process texts, incl. comparing texts. Suppose we have a text and we want to find the most close, similar passages to a certain one. It turns out to be simple. Let’s look first into the theory and then to practice.
Cosine distance
The measure of closeness [between 2 vectors] is the cosines distance or similarity. Each text sentence we will present as a vector. In Machine Learning we might encode each sentence as the vector of words or words frequencies.
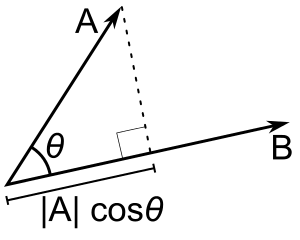
See the visual meaning of the cosine distance. The closer, the more similar the vectors are, the less the angle θ is and therefore the cos(θ) is closer to 1. The bigger the [cosine] similarity, the cosine distance [between vectors] will be tending to minimal.
Given
We are given the set of 22 sentences and we need to find the minimal cosine distance of each of them to the first one of them.
Start
Load a given file and split it into a list of sentences d:
file_obj = open('sentences.txt', 'r')
d=[] // list of all sentences
for line in file_obj:
d.append(line.strip().lower())
We split each sentence into words and save each one as a list of words. All of them (lists of words) we put into a tuple lines. Besides, we store all words of all sentences into a list _dict.
lines = () # tuple of all lines/sentences
_dict = [] # list of all words
for line in d:
// iterate over sentences
// get words filtering out empty ones
words = list(filter(None, re.split('[^a-z]', line)))
lines += (words ,)
for w in words:
_dict.append( w )
Matrix (table) with rows as words in sentences
Get the unique values of all the words in all sentences, unique_list, and form a matrix N x M where N – number of sentences M – number of all the unique words in all sentences
unique_list = list(set(_dict))
import numpy as np
matrix = np.zeros((len(lines), len(unique_list)))
print("Table shape:", matrix.shape, '\n')table shape: (22, 254)
We got the table/matrix consisting of 22 rows (all the text sentences) multiple 254 columns (all the words in all these sentences).
We fill the matrix with the number of occurrences of words presented in each of the sentences. That is, an element with index (i, j) in this matrix is equal to the number of occurrences of the j-th word in the i-th sentence.
i=0
for line in lines:
j=0
for w in unique_list:
matrix[i][j] = line.count(w)
j+=1
i+=1
// output the first matrix row
print(matrix[0, :])['in', 'comparison', 'to', 'dogs', 'cats', 'have', 'not', 'undergone', 'major', 'changes', 'during', 'the', 'domestication', 'process']
Using the scipy package we find cosine distances from each (vector) sentence to the first sentence and find a minimum one. That corresponds to a sentence most close to the first sentence.
import scipy.spatial.distance
distances = {}
i=0
first_row = matrix[0,:]
for row in matrix:
distances[i]= scipy.spatial.distance.cosine(first_row, row)
i+=1We get the minimal distance and the corresponding row index thru sorting.
import operator
dc_sort = sorted(distanses.items(), key = operator.itemgetter(1), reverse = False)
print ('Row index and the minimal distance:', dc_sort[1])Row index and the minimal distance: (6, 0.7327387580875756)
The cosine distance of first row to itself should be equal to zero:
print (dc_sort[0])(0, 0.0 )
Now we see that 7-th sentence (index 6) is the closest one to the first one among all the 21 sentences.
We’ve performed a simple text analysis. It does not take into account the forms of words. For example cat and cats are considered to be different words, although in fact they mean the same thing. It also does not remove articles and other stop-words, unnecessary words from texts.
Conclusion
The modern algebra methods are available and of easy usage for the AI tasks. The task of finding texts similarities might well be done using numpy and scipy modules.
The whole code
file_obj = open('sentences.txt', 'r')
d=[]
for line in file_obj:
d.append(line.strip().lower())
lines = () # tuple of all lines
_dict = [] # list of all words
import re
for line in d:
words = list(filter(None, re.split('[^a-z]', line)))
lines += (words ,)
for w in words:
_dict.append(w)
list_unique = list(set(dict1))
print('Tuple lines length:', len(lines))
print('List list_unique length:', len(list_unique))
import numpy as np
matrix = np.zeros((len(lines),len(list_unique)))
print("\nTable shape:", matrix.shape, '\n')
#print(lines[0]) # list of
first sentence
i=0
for line in lines:
j=0
for w in list_unique:
matrix[i][j] = line.count(w)
j+=1
i+=1
#print(matrix[0, :])
import scipy.spatial.distance
diststanses = {}
i=0
row_zero = matrix[0, :]
for row in matrix:
diststanses[i]= scipy.spatial.distance.cosine(row_zero, row)
i+=1
# we sort in order to get lowest cosine distance and get the index of that row/sentence
import operator
diststanses_sorted = sorted(diststanses.items(), key = operator.itemgetter(1),reverse = False)
print ('\nMinimal distance:', diststanses_sorted[1])
print ('\nAll other distances:', diststanses_sorted[2:])