 Power of Big Data: capabilities and perspectives
Power of Big Data: capabilities and perspectives
As everyone knows, technological development is evolving flash like. At the same time software requirements, approaches and algorithms are growing with equal speed. In particular, relatively recently, developers have faced the problem of huge data volume processing – making it necessary to create a new, effective approach, a new paradigm of data storage. The solution was not long in coming – in 2011 huge companies all over the world started using the Big Data concept. In this article we will talk about this engaging approach.
What is Big Data?
While surfing the internet you can meet a lot of Big Data definitions. Some think that Big Data is data volume which is bigger than 500 Gb, some insist that Big Data is data that can’t be processed on one computer. There is even the suggestion that Big Data doesn’t exist and the term was created by marketing specialists.
Yes, first of all, Big Data is voluminous data sets that can’t be processed in traditional and ordinary ways, but that’s only about the data amount. The Big Data concept includes in itself a set of effective approaches, instruments and methods which are used for processing all kinds of huge data volumes in order to convert them into human-friendly results or statistics. The examples of data kinds that need to be processed by effective Big Data methods are:
- Transactions of all the clients of a bank having a distributed network over the world
- Search Engine requests
- Books in The Library of Congress
- GPS-signals from cars [for some transport companies]
The story in a nutshell: Big Data is not only about information. It has applications in very different projects. After an introductory glimpse, we can go deeper and talk more about methods of processing data.
Basic principles
To characterize Big Data, scientists emphasize its 3 main principles. They are the following:
- Linear scalability. Every system using Big Data should be scalable. Data volume enlarged more than 2 times? Not a problem! A cluster (a group of computers) should be optimized for this volume
- Data locality. It’s a very useful principle in working with huge amounts of data storage. Data locality means that defined data parts should be processed and stored on the same computer.
- Fail-operational capability. It can be compared with “an error limit in physics”. If you are responsible for the cluster, your system should take into account that some computers can get broken down, so the overall processing capability should not be hindered if that happens.
To understand these principles in practice, let’s take a look at the technology needed to implement them.
MapReduce
MapReduce is the most popular method used for processing and generating Big Data sets with a parallel, distributed algorithm on a single cluster. MapReduce was introduced by Google in the year 2004. This concept was implemented in such big projects as MongoDB, and MySpace Qizmt (a MapReduce framework). By the way, MapReduce is based on the revolutionary DB’s NoSQL concept. Below you can see how MapReduce works.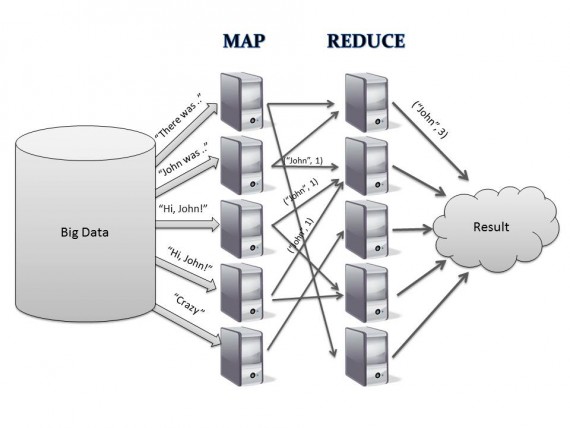 First, the algorithm takes in 3 parameters: source collection, map function and reduce function.
First, the algorithm takes in 3 parameters: source collection, map function and reduce function.
Collection MapReduce(Collection source, Function map, Function reduce)
Then, its work is divided into three main stages:
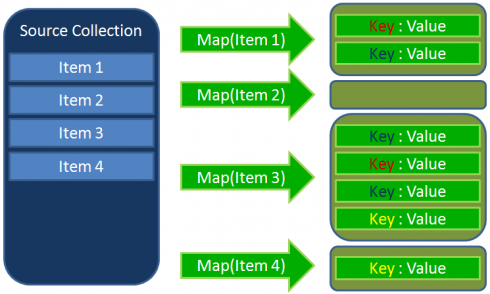
- “Map” stage. By using the map() function the algorithm processes user input. As a result it returns a variety of key-value pairs or nulls.
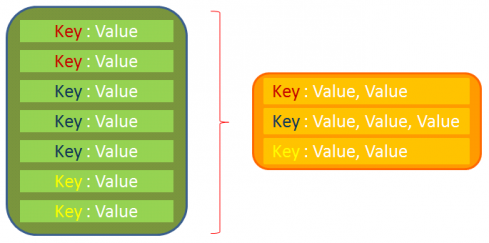
- “Shuffle” stage. In this stage data are processed without user help. The algorithm groups all values by keys.
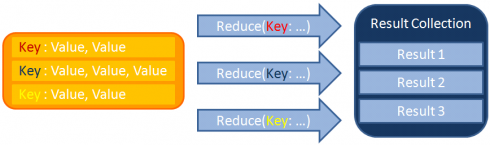
- “Reduce” stage. Each key group is processed by the reduce() method, which is defined by user. Based on the logic of the reduce() method it returns the final result.
map(), shuffle() and reduce() can be launched many times and work in parallel. Note, MapReduce doesn’t create indexes while processing data – as a result, it works slowly.
So, how is MapReduce practically realized? Hadoop is the answer!
Hadoop
At the start of the MapReduce paradigm, the concept didn’t have a realization. The problem was solved by Yahoo developers, who created Hadoop – a powerful instrument for working out the MapReduce algorithm.
The main components (core elements) of Hadoop are:
- HDFS (Hadoop Distributed File System) –a file system, which can store unlimited volumes of data.
- Hadoop YARN –the framework, which helps to work with cluster resources.
Also, 3rd party elements fill the Hadoop ecosystem. They are:
- Hive –An instrument which is used for building SQL-like queries for working with large volumes of data (gathering them from data storage)
- Cassandra – high-performance key-value database
- Hbase – non-relational Database; we will talk about it a bit later
- Mahout – Java-library for machines learning to work with Big Data
Now let’s take a look at the real-life task – “Word counter” program. It’s like a “Hello world” program in the Big Data context. The task is to count how many times every word is repeated in a huge number of documents. Our example will be written on Java. Here is the code to solve this problem:
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
The first step – map realization. We use the classes IntWritable and Text instead of Java’s String and int because the above-mentioned classes implement useful classes like Comparable, Writable and WritableComparable. Via the method map() we process all lines in the documents and create key-pair values by StringTokenizer.
If the two input sets are Hello world and Hello Hadoop, the result will be something like:
< Hello, 1> < World, 1> < Hello, 1> < Hadoop, 1>
The second step – processing groups. Here we sum up all values, which are the occurrence counts for each key.
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
And below is the main method, where we unite the above-mentioned functionality:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
Here we create a new task and define the parameters (name, mapper, reducer and paths to HDFS for results). How does it work?
For example, the algorithm processed the first line and got the map:
< Hello, 1> < Hadoop, 1> < Bye, 1> < Hadoop, 1>
Then a second line:
< Hello, 1> < World, 1> < Bye-Bye, 1> < World, 1>
Each map will be passed through the CombinerClass which is used for local aggregation.
The result for the first map:
< Bye, 1> < Hadoop, 2> < Hello, 1>
And for the second:
< Bye-Bye, 1> < Hello, 1> < World, 2>
And now is the time for the reduce() method. As we have mentioned above, it sums up the maps’ values which are repeated for each word.
< Bye, 1> < Bye-Bye, 1> < Hadoop, 2> < Hello, 2> < World, 2>
The art of the storage of Big Data
Finally, we deal with the database layer in the complicated system of Big Data. Each type of database suits specific needs. These types are:
- Hbase
- Key-value storages (Redis, memcached)
- Relational databases (MySQL, PostgreSQL)
There are a lot of articles about NoSQL and relational DB’s; it would be wise to talk more about the Hbase and Big Table concepts.
Big Table
Let’s start with Big Table. It’s a high-performance data storage system, which was created to handle very large amounts of structured data. Each table has its own RowKey (primary key). Each RowKey has attributes (columns) which are organized in groups of attributes. Each attribute can store versions that have its own timestamp. Please, look at the picture below to understand the concept.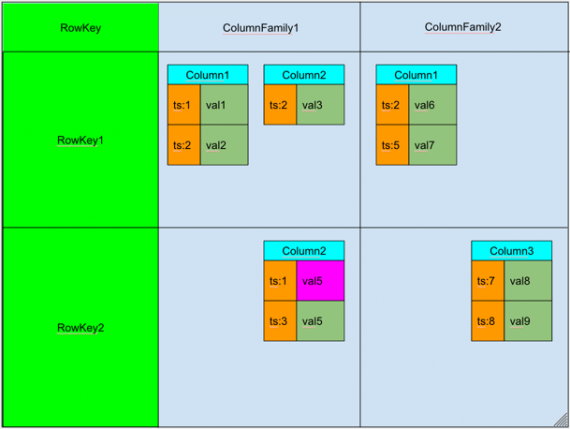
The four main operations in Big Table are similar to CRUD in relational DB’s, but Big Table also has its own unique commands:
- PUT – similar to “create” in relational databases, but here timestamp takes on the role of “id”. You can set a value by yourself, otherwise the timestamp value would be set by a program.
- GET – extract data by RowKey or Column Family.
- SCAN – reading versions. User can set the reading diapason or ColumnFamily, where data should be read.
- DELETE – delete chosen version. In fact, version is marked as deleted, but after the major compaction stage (for example in Hbase), the version is deleted terminally.
Hbase
Hbase is a very convenient DB that can work on hundreds of servers. Even if some servers break down, Hbase will work just as if nothing has happened. Such a reliable functionality is reached by a special architectural complexity which can’t be compared to the relational database architecture. If you have challenges similar to those listed below, you should immediately install the Hbase (along with Hadoop, of course):
- There is a lot of data, that can’t be contained on one machine
- System demands batch computing
- It needs to have random accessing
- Data is updated and deleted too often
After a determination of requirements, it would be useful to see how the Hbase exactly works. In fact, there are 2 main processes:
- Region Server – processed several versions’ diapasons called regions. Every Region has Persistent Storage (the place where region is stored in HFile format), MemStore (buffer for writing), BlockCache (cache for reading).
- Master Server – Main server in Hbase cluster which is controlling the region allocation. Master Server does a lot of useful work such as region structuring and controlling regular task launch.
More about Hbase architecture you can read here
Commands in Hbase are very simple. First we create a column family:
create ‘Books’
For example, if you need to add the version, you should enter:
put ‘Books’, ‘1000’, ‘The catcher in the Rye’, ‘Jerome David Salinger’
To get only one version:
get ‘Books’, ‘1000’
And to get all data in the table:
scan ‘Books’
nothing complex at all! To work with Hbase DB, you can use:
- Hbase Shell – the easiest way. It is installed with Hbase, and you can easily use the commands mentioned above.
- Native Api – for those who love Java. Well-described documentation will give you a thorough understanding of how to use it.
- REST and Thrift are APIs that allow one to work with Hbase in the developer’s favorite language.
To be continued
As you can see, the Big Data subject is too huge to cover in one article, but we expect this article will give you a good intro concept and lead off for new ideas.