
Agree, it’s hard to overestimate the importance of information – “Master of information, master of situation”. Nowadays, we have everything to become a “master of situation”. We have all needed tools like spiders and parsers that could scrape various data from websites. Today we will consider scraping the Amazon with a web spider equipped with proxy services.
Why should we use proxy?
A few words about proxy we will use, and about proxy in general. Proxy server is a middleware between you and the world-wide web – you connect to the proxy server, then via this server you surf the internet (in our case, scrape data from needed web-resources). This middleware allows receive compressed data in order to save web traffic. Secondly, it’s used for anonymization. IF we parse a lot of data requesting site IP might be banned for a while. Fortunately, by using such proxy servers, proxy’s IP will be banned, not yours.
In our test we will use 3 proxy providers:
- MarsProxies is a very reliable and secure proxy provider. The service offers Ultra Residential Proxies (used in the test), Datacenter Proxies, ISP Proxies & Sneaker proxies for sneaker hunters to aqcuire rare shoe items 😉 .
- IPRoyal proxy service. The proxy service is fast, secure and reliable. They provide excellen residential proxies as well as Sneaker proxies, Datacenter proxies and Mobile proxies.

- NetNut – very fast and highly-secured proxy network. The servers are located on major internet routes or at ISP network connectivity points that are completely controlled by NetNut.
Each proxy will be tested in tandem with Netpeak Spider. You might jump directly to the results.
Netpeak Spider at a first glance
Proxy servers play role of supportive software. The lead character is Netpeak Spider. This tool was developed for complex SEO analyze. Moreover, Netpeak Spider is a perfect scraper, we will see how it works little bit later.
We are going scrape data from amazon.com, specifically, books’ bestsellers – an author name and book’s title.
Basic configurations
Before we start scraping, let’s quickly configure our project in Netpeak Spider. Firstly, let’s connect proxy with the spider. After you get proxy service login data, go to Settings -> Proxy and enter needed data. And don’t forget to check the connection!
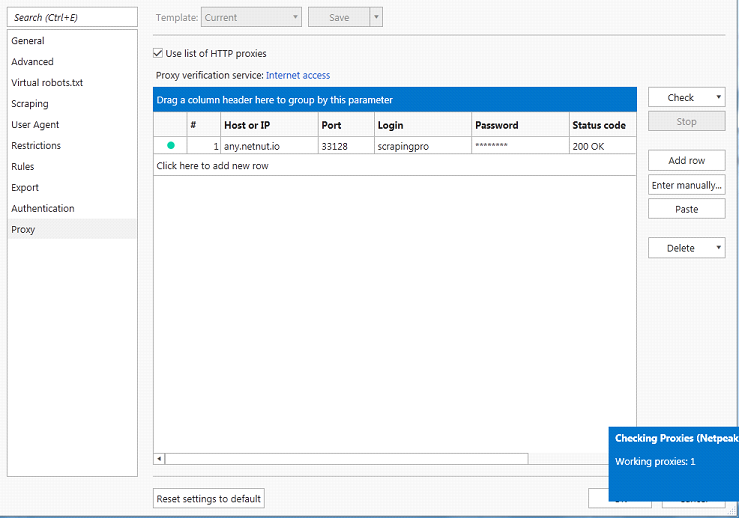
What else should we configure in Netpeak Spider?
- Number of active threads – it defines how fast crawler will work. The more the number of threads, the higher chance to be banned by Amazon. Let it be 10 threads.
- URL – we want a crawl information only about books, so we need to set an init url – https://www.amazon.com/gp/bestsellers/books
- Parameters – Netpeak Spider will return us a lot of information about parsed urls, such as response type, url depth, head tags and so on. For now, we don’t need it. In order to skip overloading them making the spider work faster, you can leave only a status code parameter in general parameters.
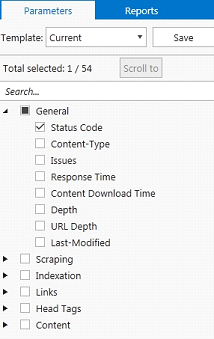
Spider Test
Now we test the spider by crawling about 50 thousand URLs! Spider will collect URLs that are related to the start point (above mentioned URL) and return us some information. Let’s check how fast spider will work with both NetNut and GeoSurf…
Even for spiders analyzing 50 thousand links is a hard task that will take a long time. We have armed ourself with patience and waited until spider finish work. If you haven’t much time for waiting, you can save & close project and continue spider’s work from the saved point – good feature, I think.
Here is result of work in one picture:
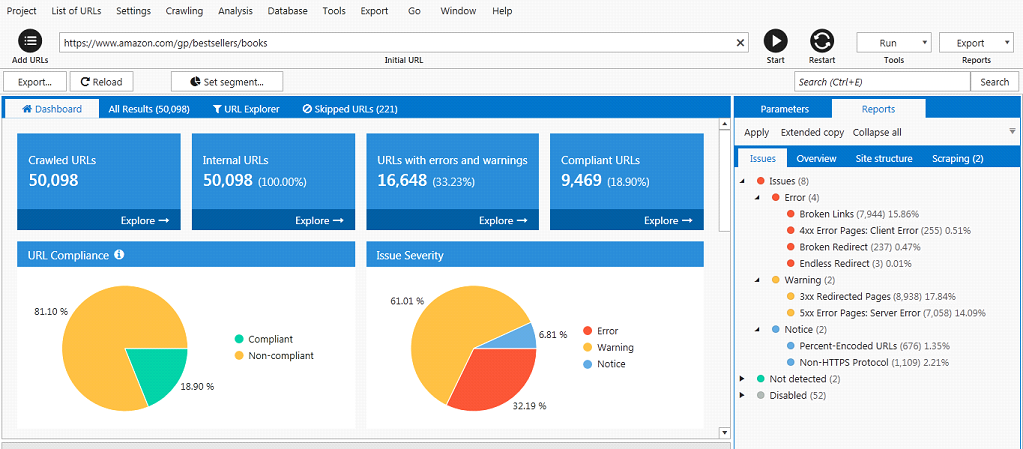
Here we can see detailed information about parsed URLs: how much there are broken links, links with 3xx and 5xx code, skipped and so on. At the All Results tab you can easily get needed data about every parsed link. For example, source code of the page or issues.
Test results
So, what’s about the results to scrape 50K URLs of the Amazon data aggregator?
| Provider | Time | Bandwidth |
|---|---|---|
| IPRoyal | 2 ½ hour | 5.9 Gb |
| MarsProxies | 3 ½ hour | 4.7 Gb |
| NetNut | 3 ¾ hour | 5.8 Gb |
The leaders are MarsProxies and IPRoyal. The former was the best on the bandwidth size (4.7GB) while the latter having done the job in shortest time (2½ hours).
If you consider that the extraction took too much time, 50 thousands urls is a complex task even for the best spiders. Fortunately, the spider has a very useful feature: one can pause site analyzing, close spider and continue its work in any time.
Scraping data
Settings
We got acquainted with the spider, now let’s make something more engaging. We will try to scrape data about every book. In particular, book’s title and author. Firstly, let’s consider the source code on the page with a bestseller and press F12.
To get book’s title and author’s name, we should find the needed information in source code. Of course, we won’t grab with the whole code, all we need is to click on the first icon in the toolbar (“Select an item…”) and click on the needed information. In our case, this is the book title
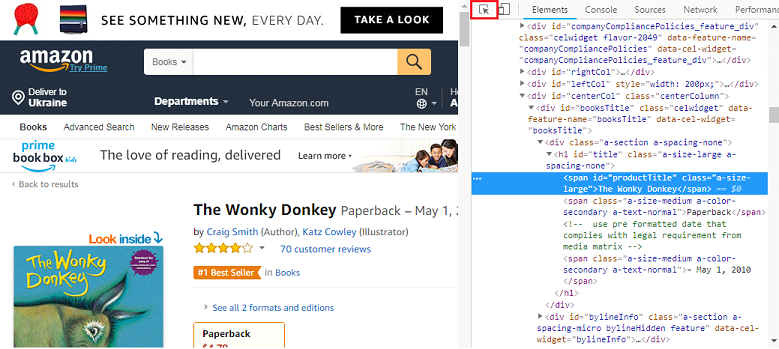
Now we need to copy element’s code for scraping. We will use XPath. Right click on the code -> Copy -> Copy XPath. The same thing works with author’s name.
After we’ve found needed elements, we should configure the spider for scraping. Go to Settings -> Scraping and tick “Use HTML scraping”. Now we can add fields that we will scrape. Choose XPath, assign name and paste the XPath code [that you’ve just acquired] for each field.
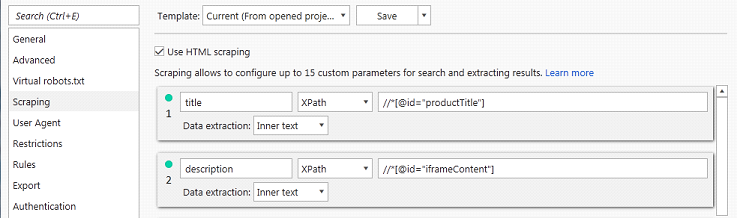
Then, in “Parameters” you will see a new checkbox called “Scraping”. Tick this checkbox. It will allow us to see book’s title and author on the next site analyzing.
Everything seems to be fine, but in fact we have some hardships. Let’s look at the links that we have parsed. In the right panel, open the tab “Site structure”.

After a little discovering, we’ve found out that not all pages that we’ve parsed are links to the bestsellers. Strange thing, bestselling books should be situated at address …/gp/bestsellers/books/book-name. Instead, books are situated at address …gp/product/book-name. Moreover, we want to parse only books, but we have parsed a lot of needless links. Why?
That’s caused by Amazon’s complex site structure. The site categories are not organized in a traditional way (sitename/category/subcategory/product-name) and as a result, it’s very hard to scrape such huge sites with complex site structure. If the structure is ordinary, the spider will go deeper from category to subcategory by default. Try Netpeak Spider on the little online stores, you will understand the difference.
Let’s look at our table with “book urls”. Find in site structure tab “product”.
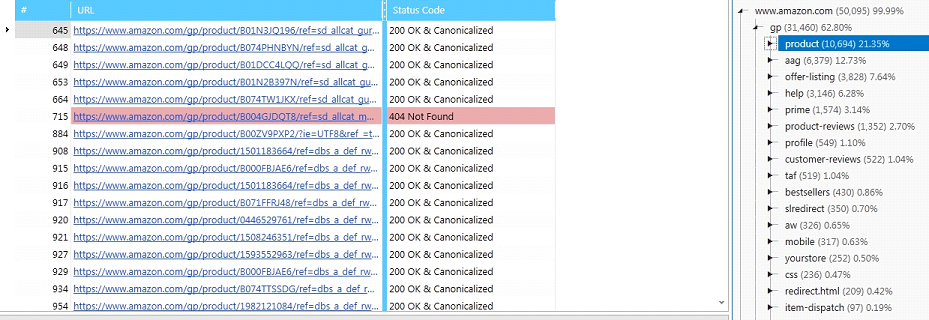
This list of urls we should parse. Fortunately, it’s very easy to do with Netpeak Spider. Right click on any url, current table ->scan table, profit!
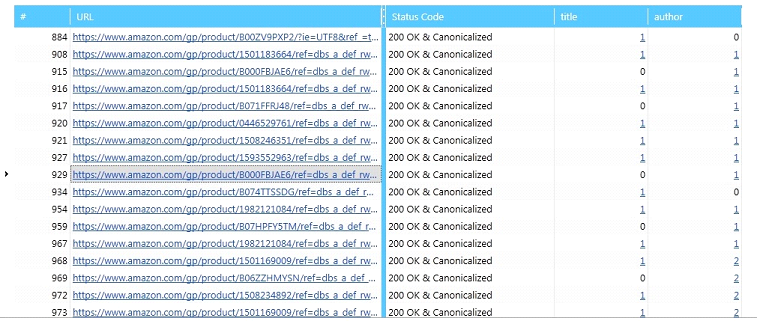
And here are our results! In some cases, there are even two results for the author. Click on the highlighted digit and you will see the actual result.
Conclusion
The test has shown us Netpeak Spider having a decent speed for 50K entries to scrape with minimum of our efforts. As one can see, spiders make scraping much easier and faster. Additionally, proxy servers provide more reliable (ban-proof) scraping process. Now it’s your turn – try to use spider for your own needs: change configurations, try to scrape data from different sites, configure the result output and export them in file. And don’t forget about proxy!