Recently I was given a bunch of sites to scrape, most of them being simple e-commerce. I decided to try Zyte AI powered spiders. To utilize it, I had to apply for a Zyte API subscription and access to Scrapy Cloud. Zyte AI proved to be a good choice for the fast data extraction & delivery thru spiders that are Scrapy Spiders. Below you can see my experience and the results.
I have done another “experience” post on the Zyte platform usage.
Really Quick Start
- First one needs to register. I had to plug in my bank card to my account at Zyte API.
- Creation of first crawler was relatively easy. Go to
https://app.zyte.com/p/xxxxxxx/create-spider . The Scrapy Cloud provides templates for spiders that extract product data from e-commerce websites. See docs. That’s where AI alchemy starts…
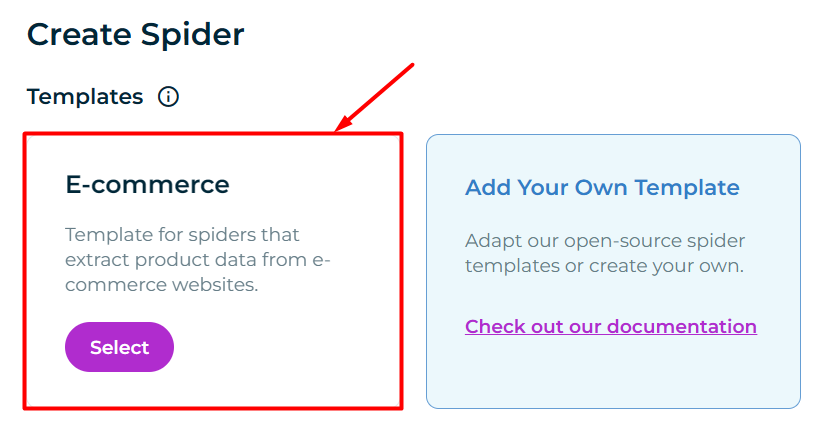
Setting up a template was relatively easy:
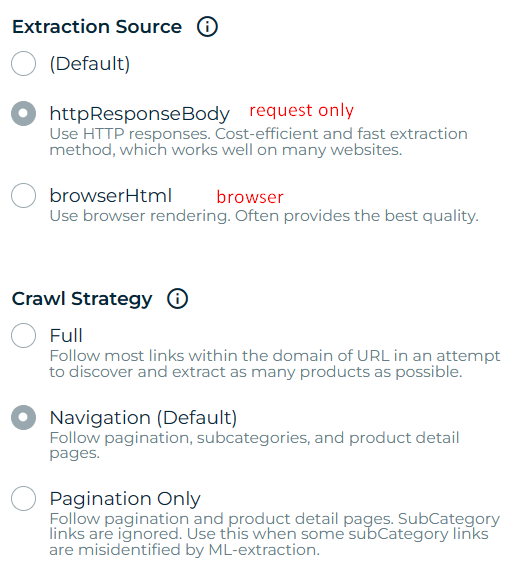
Now with “Save & Run” the spider started crawling. Initial results were poor as the spider got only a fraction of all the category items. I contacted support and in less than an hour they responded with practical tech help. The settings correction was done and the spider worked as intended.
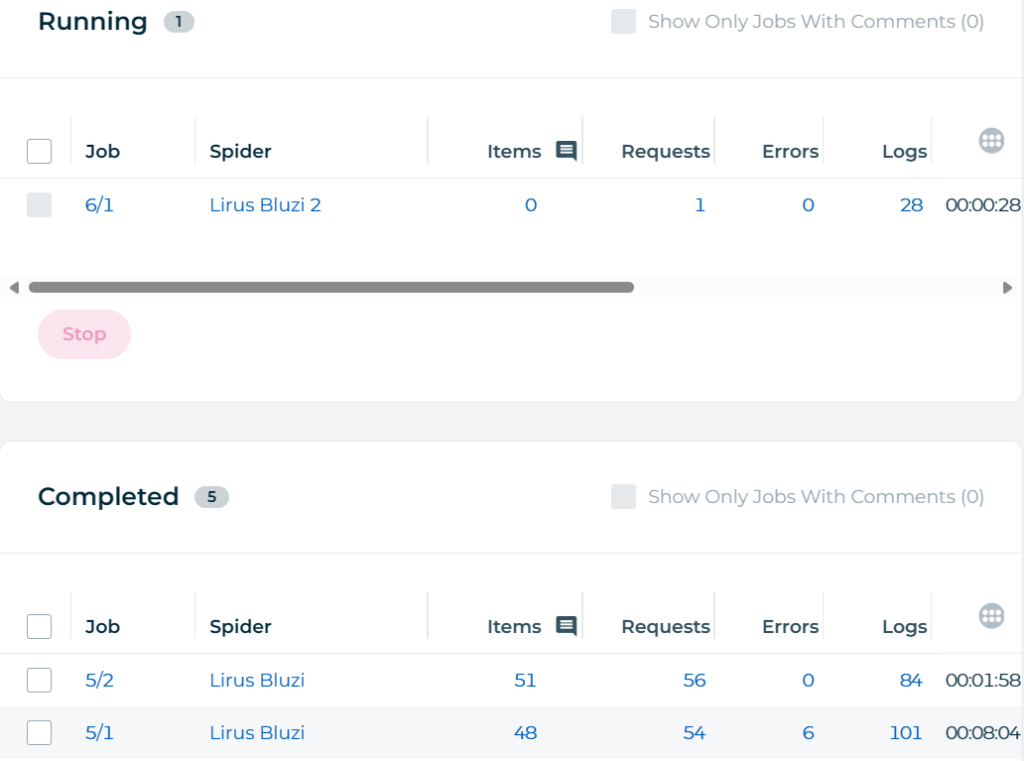
Jobs /executions
On the Jobs dashboard one may watch running jobs, completed jobs and much more.
Data mapping, collection & cost
Since Zyte spiders are AI powered, the data mapping is done without user intervention. As to the the comprehensiveness of data the result has been overwhelming. The spider collected most of the on-page data available, data having been correctly structured and nested. See a sample json data item.
For a total of around 300 entries collected with direct HTTP requests I was charged only $1.73 that is ~ $0.0058 per gathered product. I consider it being fair since there is no need to pay for spider development: spend time for spider fields mapping & selectors composition.
Basically the cost of requests differs per website, based on how hard the site is to unblock. So easy to access sites will be cheap, but hard-to-access sites will work cost-effectively too. The Zyte Cost Estimator is to your disposal as well, Zyte API -> Cost Estimator :
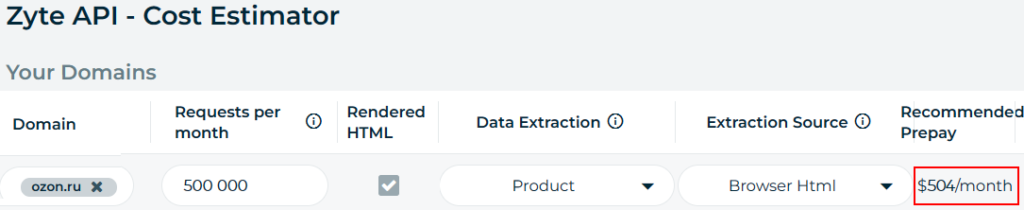
One needs to note that Zyte spiders almost seamlessly gathered data of the data aggregator protected with CloudFlare, the error rate being 4% only.
Cost constituents
Basically any spider [cloud] run consists of 2 parts:
- Zyte API plan. The environment facilitates ban’s avoiding, enabling browser automation, enabling automatic extraction, AI data mapping and more. The cost of requests is different per website, based on how hard the site is to unblock and the resources required.
- Scrapy Cloud Unit. It’s an engine/platform where spiders are hosted and run in cloud. Its Free Version is limited with an 1 hour [each] spider run. The Paid Version charges $9/month per [cloud] unit. More on pricing.
Data download and presentation issues
The data download is available in either format: CSV, JSON and XML.
Yet there was no support for semicolon field separator as to CSV. See a support thread about the lack of possibility of changing default denominator for CSV from comma to semicolon. This has forced me to download data as JSON and convert them into CSV with the semicolon field separator, a European style.
My attempts with JSON to CSV conversion initially resulted in misaligned results 🙁 , see a figure below. This was due to the result of JSON data being multilayer/nested ones:

Even though I was successful in the end, still the amount of additional conversion and files handling spoiled the seamless process of data crawling and delivery. I’d suggest to the developers to add a data download option for XLSX files that work as needed on both sides of Atlantic.
Conclusion
Zyte AI spider functionality reflects the modern AI application to web scraping, particularly to data mapping. The overall usability was excellent, yet the resulting data retrieval was limited with the US type CSV file.