As we have touched on some basics on Clusters in Data Mining, we want to consider the computation techniques applied for clusters. Those techniques stand in line with the data mining for web traffic analysis.
Parallel computing for cluster description
Using parallelism and distribution are quite fitting in the computation of clusters. Why not use MapReduce strategy and huge modern data vaults for a large collection of input elements? It is most appropriate for calculating cluster descriptions such as centroids and distances to the clustroids from single points:
- The sum of the distances to the other points in the cluster.
- The maximum distance to another point in the cluster.
- The sum of the squares of the distances to the other points in the cluster.
The best approach is to use a MapReduce functionality, but this is not always applicable, so we might be limited to just a Reduce task. MapReduce, with its variations, is not the only technique for parallel computing, but for now we’ll stay with this strategy, as it is most fitting and getting more popular.
MapReduce strategy
The model is derived by the map and reduce functions from functional programming but now is widely spread in many programming languages. There is no direct match between programming functions and parallel computing MapReduce, but this example will clearly explain the strategy:
- Map task: a call
map square [1,2,3,4,5]will return[1,4,9,16,25]list, as ‘map’ will go through the list and apply the function ‘square’ to each element. - Reduce task might be to group the even and odd squares into clusters:
even [1,4,9,16,25]andodd [1,4,9,16,25]issue[4, 16]and[1, 9, 25]sets.
Example implementation in PHP (only Map task):
<?php// the closure
$square = function($a) {
return $a * $a;};
// The range of numbers [1-5]
$numbers = range(1, 5);
// We use the closure as a callback function
// here to square each element in our range
$new_numbers = array_map($square, $numbers);
print implode(' ', $new_numbers);
?>Briefly, the MapReduce implementation can be described in this way.
Map (k1,v1) → list(k2,v2)
Reduce(k2, list (v2)) → list(v3)
Map functionality works on input key/value pairs {[0]=>1, [1]=>2, [2]=>3, [3]=>4, [4]=>5} to generate a set of intermediate key/value pairs {[0]=>1, [1]=>4, [2]=>9, [3]=>16, [4]=>25}, and a Reduce functionality merges all intermediate values associated with the intermediate key {[0]=>{1, 9, 25}, [1]=>{4, 16} }.
The best thing about MapReduce is that it fits well into distributed computing thus allowing processing large datasets timewise. When applying this technique, besides distributed computation also input/output issues and processes and subprocess latency issues must be under close consideration.
MapReduce implementation by Google
Google parallel computing has been using MapReduce algorithms since 2003. The library works in a distributed file system and in commodity servers to spread and thus speed up computing effectiveness. Some of the applications of the system are web indexing, ranking of web pages, document clustering. The slides on Google’s applying MapReduce are quite helpful in explaining how this technique is being progressively applied in deployment. Some details, statistics and implementation challenge breakthroughs are well bulleted in those slides.
This picture of MapReduce is the best illustration; I found it in Google:
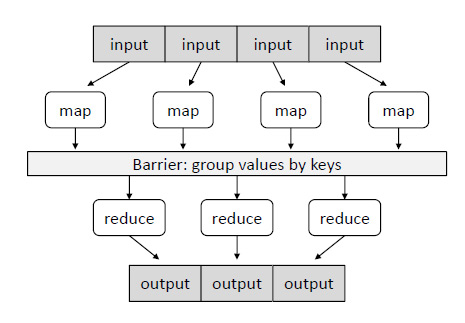
The best thing is that this strategy, put into the library, deals with messy details, thus emancipating users from implementation problems. Then users can focus solely on the case problem.
There were many search engines before Google but I believe it’s thru parallel computing implementation that Google has advanced that far in indexing and offering fast search query results.
MapReduce for clustering
We start by creating many Map tasks. Each task is assigned a subset of the points. The Map function’s job is to cluster the points it is given. The output is a set of key/value pairs with a fixed key = 1, and a value that is the description of one cluster (also for non-Euclidean space). This description can be any of the previously mentioned possibilities for the centroid. It also might be one of the suggested clustroid descriptions.
Key-value pairs have the same key, therefore there is only one Reduce task. This Reduce task collects descriptions of the clusters produced by each of the Map tasks and merges them appropriately. All the various strategies that we might use to produce the clustering are described in this paper in paragraph 7.6.4. I recommend this book on Data Mining as extensive and well-written treasury (by Anand Rajaraman and Jeff Ullman).
For parallelism in clustering using Map-Reduce, we divide the data into chunks and cluster each chunk in parallel, using a Map task. The results from each Map task can be further clustered in a single Reduce task.
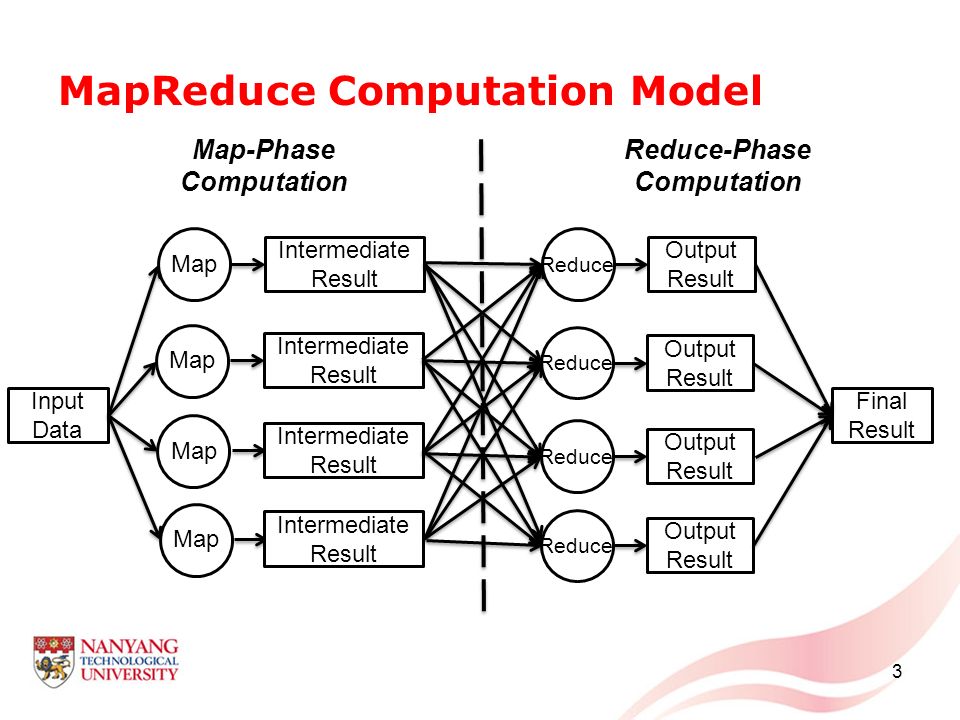
Summary
The MapReduce model is a technique for parallel computing; clustering computation is relatively easily done with it. One of the frameworks for distributed computing applications is Apache Hadoop, which incorporates the MapReduce strategy. Other ones we’ve briefly described in this post.