Recently we discovered a highly protected site — govets.com. Since the number of target brand items of the site was not big (under 3K), I decided to get target data using the handy tools for a fast manual scrape.
Test for anti-bot techniques
First of all we tested the site for the antibot techniques at a Discord server. The result was successful. The following anti-bots measures were detected:
1. Cloudflare
- Headers:
cf-chl-gen,cf-ray,cf-mitigated - Server header:
cloudflare
Detected on 116 urls …
2. Recaptcha
- Script loaded:
recaptcha/api.js - JavaScript Properties:
window.grecaptcha,window.recaptcha
Tools for manual scrape

- Browser Edge or Chrome. All the scrape is done using browser extentions. Note: Chrome extensions work perfectly at Edge.
- Bulk URL Opener addon for Chrome or Edge
- Free VPN — Microsoft Edge Addon — a browser VPN for surfing with USA IP.
- Easy Scraper — Free Web Scraping extention

- Notepad++ — a free editing enviroment.
- Windows command line. Hit
cmdin the Windows Search Box and it’ll be on [for joining a pull of scraped files into one]. - Online JSON to CSV converter.
1. Turn on VPN addon
Turn on VPN browser addon to US IP to be able to surf the US-restricted site. This enabled us to open govets.com site. Note: if you are using Chrome browser then choose any free VPN addon alternative from a list.
2. Identify URLs pool
First we do an initial on-site search and get a number of results (2674). We scroll down a search result page and set the maximum Results per Page value. Besides, by hovering to a pagination link, eg. 2 , we find out the basic URL structure. See the figure below:

Now the URLs pool (27 items) is the following:
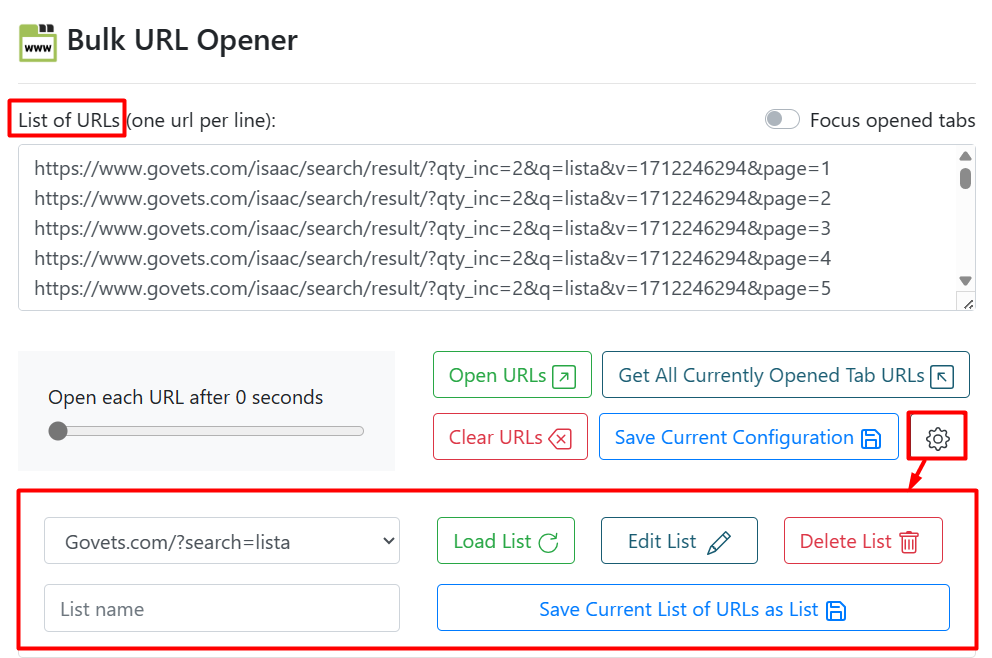
3. Open URls set in bulk
We open in browser the Bulk URL Opener ext. and load 27 target urls into it:
4. Scrape each page with “Easy Scraper” addon
As we switch to each tab (with results) we run “Easy Scraper” addon by a button click: 
Now the extention is on and it automatically identifies and gathers data of 100 items present:
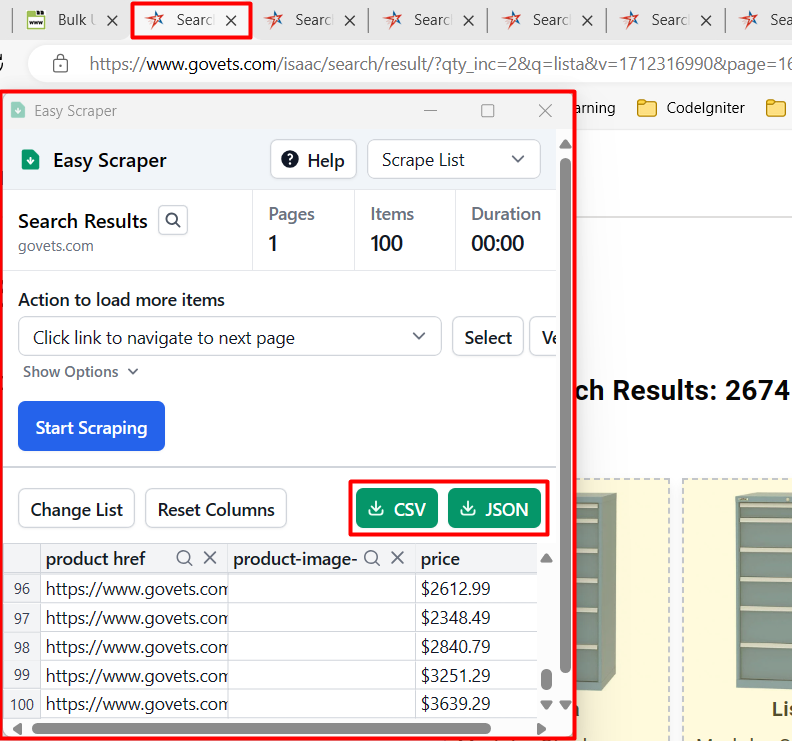

Note, the govets.com search results provide quite good set of features for each product incl. image, SKU, price and discount price, see the image to the left. If the result product data are not enough, we should first gather product URLs and then use Easy Scraper addon in the “Scrape Details” mode. Otherwise we are to develop a code scraper to get data off each product page. See a figure below:

For each Easy Scraper example [that contains 100 results] we download them whether as CSV (US-type, comma separated) or JSON. Since my PC is set to semicolon as a field separator (Europe-mode) I preferred to load data as [multiple] JSON files for later joining:
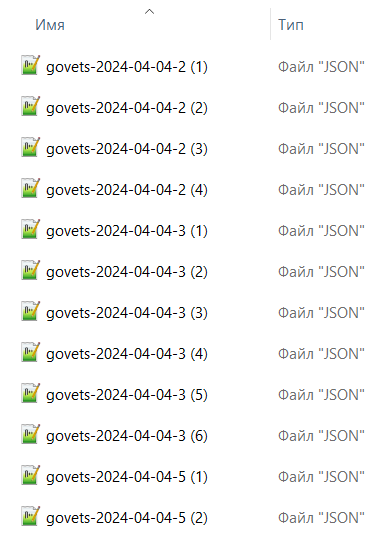
5. Join multiple [result] files into one
Is there one command that would join multiple files into one ?
Linux users would definitely answer positively, yet Win or Mac ones would not be so sure. Luckily we’ve done it before and even made a post about it: Merge files in Windows CMD & in Power Shell. The line below has easily made files to join:
cmd /c 'copy /y /b *.json govets-resuls.json'
But because of JSON structure the joined file had specific characters (brackets) that must be substituted with commas, see line 4 at the code below:
"product-item-link": "Partition 10-15/16 In x 36-1/8 In MPN:P300-54",
"price": "$58.49"
}
][
{
"product href": "https://www.govets.com/lista-310-16974073.html",
"product-image-photo src": "Notepad++ has done excellently to replace ][ with comma — , yielding a perfect JSON.
6. Turn JSON into CSV and remove duplicates
There are plenty of tools incl. online ones that convert JSON into CSV.
I used one (convertcsv.com) that facilitates the customize field separator to one of Europe style (semicolon).
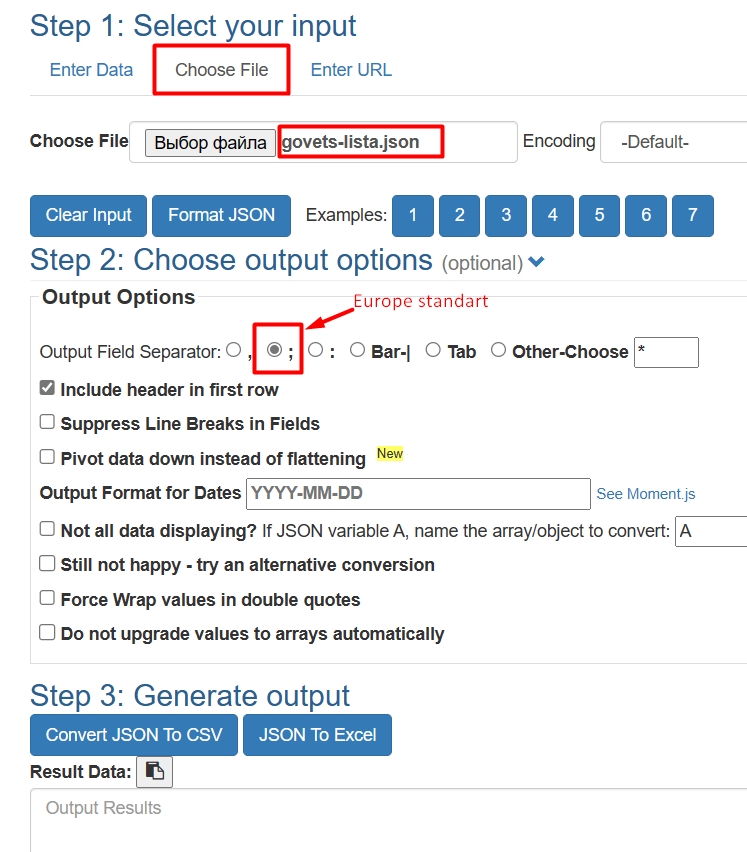
Since we have done an extensive scrape, we had better check for duplicates when the file is in Excel: Data —> Remove Duplicates. Voilà. Data are at hand.
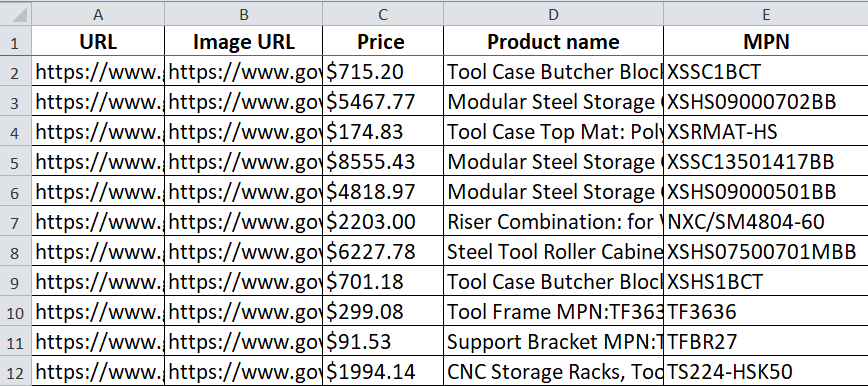
Note: There might be the need for some data modifications (eg. split, symbols removal, etc.) to be done inside of Excel.
Conclusion
The whole scrape process took me less than an hour and I was quite happy with the given results. With that in view I consider that this particular manual scrape case had a very good quality-price ratio:
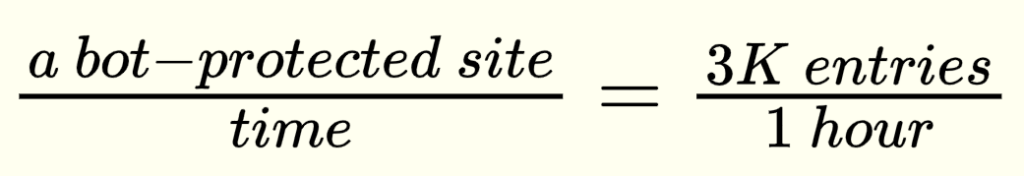
There might be some obstacles or nuances that only scrape/data experts are able to overcome. So feel free to contact me for help or consultaton: igor [dot] savinkin [at] gmail [dot] com
Теlеgrам: igorsavinkin