
Handy Web ExtractorHandy Web Extractor is a simple tool for everyday web content monitoring. It will periodically download the web page, extract the necessary content and display it in the window on your desktop. One may consider it as the data extraction software, taking its own nitch in the scraping software and plugins.
It’s totally free and available for download.
What is it for?
Have you ever needed to track some web site changes without visiting it again and again? If so, you may find this program useful. The idea is simple: it periodically downloads the specified web page, extracts the part you need and displays it for you in a small window. You can easily move, resize, hide or show this window according to your needs.
It s totally free.
How does it work?
After installing the program you will see the following window:
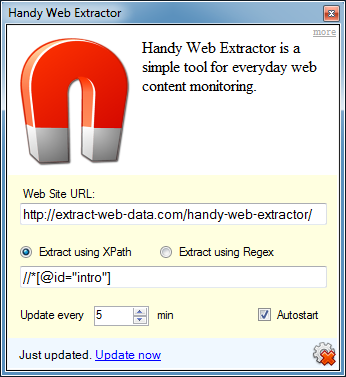
At the top of the window (on white background) you may see the extracted web page itself (in this case it s a header of this article) followed by program settings (on light yellow background). If you don t see the program settings click on the gear icon (if you want to hide them click it again).
Settings available:
- Web Site URL type the URL of the target web-page you want to scrape
- Extract using XPath use this option if you want to specify the portion of the web-page using XPath expression
- Extract using Regex use this option if you want to specify the portion of the web-page using Regex expression
- Update every N min to specify how often the program will scrape the target website
- Autostart check this box if you want the program to start automatically when Windows starts
After you change either the web site URL or XPath/Regex expression click the Update now link at the bottom to rescrape the web site.
You may always access this window via the magnet icon in the system tray. Click the icon to show/hide the window and right-click it to display an additional menu.
That s it. The only thing I d like to mention here is that the program remembers all your settings right away (including window position and size) and you don t need to save them manually.
Usage Examples
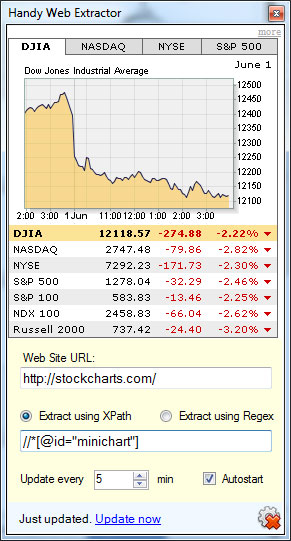
Stocks
You can use Handy Web Extractor as a stock tracker:
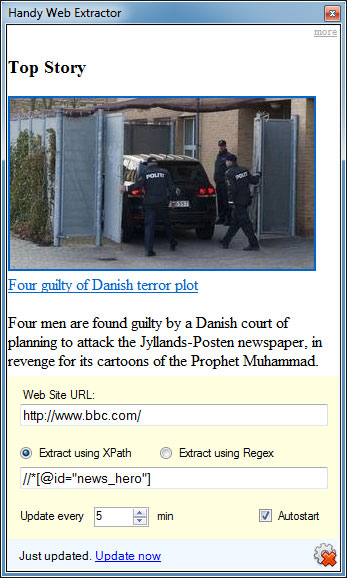
Hot news
Here is an example of how to monitor hot news using Handy Web Extractor:
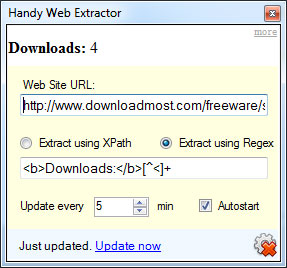
Number Tracker
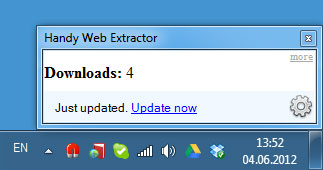
With Handy Web Extractor you can easily extract a single number using Regex expressions. Here is an example of how to track your program downloads:
Here is how it may look on your desktop:
Picture of the day
You may even use Handy Web Extractor to display a picture of the day from any web site 🙂 :
20 replies on “Handy Web Extractor”
Can I add more than 1 url to be scraped….example: 10 different url home pages looking for a common search word (s) and/or phrases ?
No, not in this version.
Can I add more than 1 url to be scraped….example: 10 different url home pages looking for a common search word (s) and/or phrases ?
No, not in this version.
How to download data and import in wordpress
How to download data and import in wordpress
Hello, I tried to run this but could not get it to work.
Web site URL: https://www.elance.com/r/jobs/
Extract using XPath: div id=”jobSearchResults”
Any help would be greatly appreciated.
Thank you.
Hi Alex,

First of all your xPath query should be //div[@id=”jobSearchResults”]. Better you get acquainted with xPath notation: here and here.
Second, I’ve checked the content of elance…/jobs/ – it has lots of malformation in HTML/XML.
Third, I’ve tried with the right xPath and have succeeded!!!
Dear Sir
I would like to add to my demand from yesterday that I tried with you example
Pop-Music DVD
K. A. Bred
2012
29.99
23.2
Gone with the wind
M. Mitchell
1936
19.05
15
that I putted to a HTML file on my server and the query you give
//price[@currency=”EUR” and text()]/text()
or
//price[@currency=’USD’]
and received ONE (1) answer
In the same occasion I permitt me to ask a seconde demand. I’ve 4 *.zip files on my site (all in the same directory. And I search to know the number of download (like your example) but due to my difficulty in programming, I did’nt succed. If you could help me I would be very thankfull
the link is http://www.christian-roux.ch/excelgestion/*.zip
Thanks
CR
Not clear what’s your particular difficulty: I search to know the number of download ? The xPath is to be applied to the XML/HTML files, not zipped ones. You first need to unzip them. Then you may apply xPath. Got it?
Thank you for responding. It’s the same like in your example “Number Tracker”, but I’ve 4 files zip to track (toghether in one (1) value)
http://www.christian-roux.ch/excelgestion/excelgestion3.zip
http://www.christian-roux.ch/excelgestion/excelgestion4.zip
http://www.christian-roux.ch/excelgestion/excelgestion4e.zip
http://www.christian-roux.ch/excelgestion/xlgm3.zip
You did with regex: “[^>]+”
Probably “Web site URL”: http://www.christian-roux.ch/
and ask what should I do?
Many thanks, regards
CR
Not fully clear. You just track the download url with [^>]+?\.zip regex. This will issue to you one result. But for hrefs you might find many regexes online. Google over ‘regex for href’.
Dear Sir
I would like to add to my demand from yesterday that I tried with you example
Pop-Music DVD
K. A. Bred
2012
29.99
23.2
Gone with the wind
M. Mitchell
1936
19.05
15
that I putted to a HTML file on my server and the query you give
//price[@currency=”EUR” and text()]/text()
or
//price[@currency=’USD’]
and received ONE (1) answer
In the same occasion I permitt me to ask a seconde demand. I’ve 4 *.zip files on my site (all in the same directory. And I search to know the number of download (like your example) but due to my difficulty in programming, I did’nt succed. If you could help me I would be very thankfull
the link is http://www.christian-roux.ch/excelgestion/*.zip
Thanks
CR
Not clear what’s your particular difficulty: I search to know the number of download ? The xPath is to be applied to the XML/HTML files, not zipped ones. You first need to unzip them. Then you may apply xPath. Got it?
Thank you for responding. It’s the same like in your example “Number Tracker”, but I’ve 4 files zip to track (toghether in one (1) value)
http://www.christian-roux.ch/excelgestion/excelgestion3.zip
http://www.christian-roux.ch/excelgestion/excelgestion4.zip
http://www.christian-roux.ch/excelgestion/excelgestion4e.zip
http://www.christian-roux.ch/excelgestion/xlgm3.zip
You did with regex: “[^>]+”
Probably “Web site URL”: http://www.christian-roux.ch/
and ask what should I do?
Many thanks, regards
CR
Not fully clear. You just track the download url with [^>]+?\.zip regex. This will issue to you one result. But for hrefs you might find many regexes online. Google over ‘regex for href’.
Hi
Can I use this tool to get business data when I open 411.ca or similar website.
I am looking to collect business information to put into my business directory
Thanks
Hi Inam,
the Handy Web Extractor is not designed for mass data extraction and storing data into DB. Its goal is to show off a particular web page item or value into desktop tray. If you are interesting in collect[ing] business information to put into my business directory you’d better turn to professional tools.
One more useful post.