 Question: What is Selenium web scraping?
Question: What is Selenium web scraping?
Answer: A picture is better than 1000 words: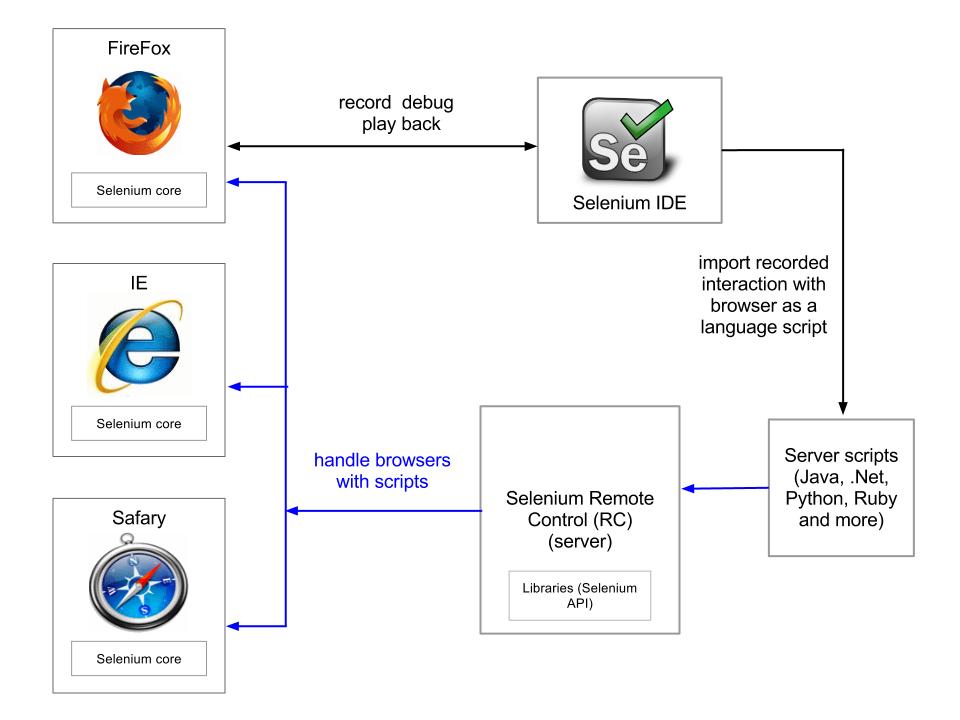
So, you make a program with Python, PHP, JAVA, Ruby and whatever language you use in order to browse(), select(), click(), submit(), save(), etc., target web pages.
2 main advantages
- The browsing is done by a real web browser (it might be headless, that is without a graphical user interface, GUI). Thus, all in-page JS is executed and a web page has all the DOM items that it should have.
- The web masters do not consider that scraping, as the scraping, hence robots, and scraping activity, are very much hidden, not detected.
2 main disadvantages
- Many resources (RAM, CPU) are needed to run a well-equipped browser. See a scrape speed comparison table:
Chromium headless instance by Selenium* HTTP requests Setup time, ms 45000 5 Log-in time, ms 105000 13 1 page load time, ms 6 10 *based on TripAdvisor scrape
Source. - Some advanced business directories’ sites (eg. Amazon, Linkedin, TripAdvisor) set up a Selenium-like browsing detection, thus preventing the web scraping.
Read more on Selenium web scraping.