The JS loading page is usually scraped by Selenium or another browser emulator. Yet, for a certain shopping website we’ve
found a way to perform a pure Python requests scrape.
The website performs simple GET XHR (Ajax) requests to upload more of its data onto a page as a user scrolls down. The data are supplied as JSON, which greatly simplifies the parsing process:
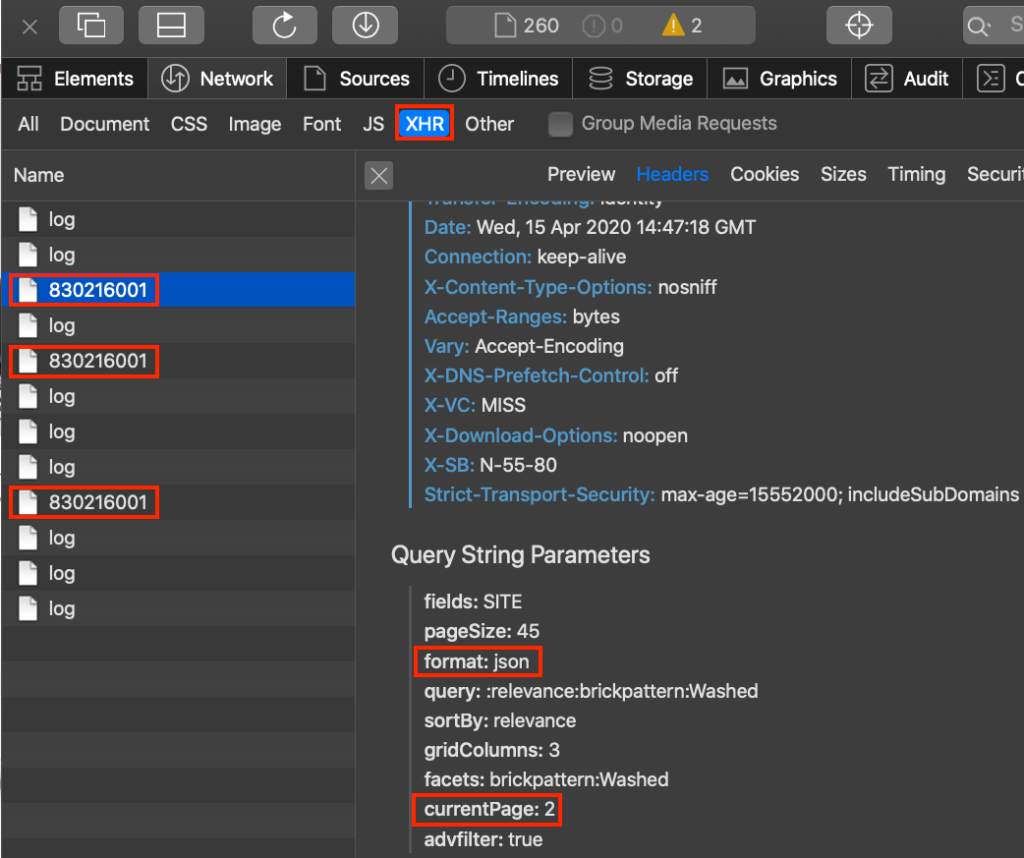
Here is the code:
import requests
def get_source(page_num = 1):
url = 'https://www.ajio.com/api/category/830216001?fields=SITE¤tPage={}&pageSize=45&format=json&query=%3Arelevance%3Abrickpattern%3AWashed&sortBy=relevance&gridColumns=3&facets=brickpattern%3AWashed&advfilter=true'
res = requests.get(url.format(1),headers={'User-Agent': 'Mozilla/5.0'})
if res.status_code == 200 :
return res.json()
# data = get_source(page_num = 1)
# total_pages = data['pagination']['totalPages'] # total pages are 111
prodpage = []
for i in range(1,112):
print(f'Getting page {i}')
data = get_source(page_num = i)['products']
for item in data:
prodpage.append('https://www.ajio.com{}'.format(item['url']))
if i == 3: break
print(len(prodpage)) # output 135 for 3 pages The code was provided by Ahmed Soliman.
You might want to read a post of how to scrape dynamic website thru regular [Python Scrapy] requests to its API.
One reply on “Scrape a JS Lazy load page by Python requests”
[…] If the Same Origin Policy is not imposed, you might try to emulate “load more btn.” with regular scraping library. See an example. […]