In this post I want to share on how one may scrape business directory data, real estate using Scrapy framework.
Tricky dynamic data
First the site of interest is a dynamic one, the HTML code does not have actual data records (houses or apartments) in it. The data are loaded thru Ajax/XHR. So, using browser developer tools and web sniffer we’ve detected it. The API categories URL is the following: https://www.sreality.cz/api/cs/v2/estates
The data as JSON are much easily to be parsed compared to HTML. Based on the filtering by the GET parameters (see below) we request all the info pertaining to needed categories. Parameters are the following:
- category_main_cb ( property type: house/appartment)
- category_type_cb ( ad type: sale or rent )
- locality_country_id
- per_page
- page (page index)
The categories API request returns the individual property API URLs.
The individual property API URL
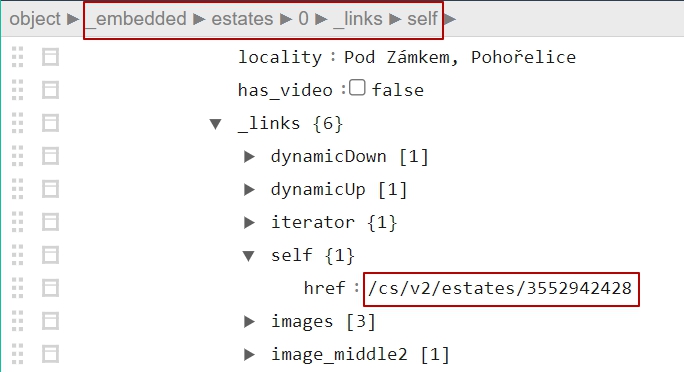
After examining JSON we find the estates links, individual property links. Eg. https://www.sreality.cz/api/cs/v2/estates/<ad_ID>
where <ad_ID> is an ad number, eg. 2103730524
Since the property ads number is a changing one, one may request the exact properties count thru corresponding URL: https://www.sreality.cz/api/cs/v2/estates/count
Now having both the categories API URL we may parse it.
The workflow
The scraper requests all the categories URLs (start_urls array) and parses them with the parse procedure. As it gets individual property URLs, it spawns new Scrapy requests to be parsed by the parse_detail_page procedure. Both methods deal with JSON data.
The code
Alternatively you might fork the code of the github.
import scrapy
import json
class MySpider(scrapy.Spider):
name = 'Real estate data of srealty.cz'
#max_pages = 2
per_page = 100
base_api_url = 'https://www.sreality.cz/api'
property_codes = { 1: 'apartment' , 2:'house' }
deal_codes = { 1: 'sell' , 2: 'rent' }
#count_URL = 'https://www.sreality.cz/api/cs/v2/estates/count'
houses_rent = ['https://www.sreality.cz/api/cs/v2/estates?category_main_cb=2&category_type_cb=2&locality_country_id=10001&per_page=' + str(100) + '&page='+str(x)+''for x in range(1, 10)]
houses_sell = ['https://www.sreality.cz/api/cs/v2/estates?category_main_cb=2&category_type_cb=1&locality_country_id=10001&per_page=' + str(100) + '&page='+str(x)+''for x in range(1, 110)]
apartments_rent = ['https://www.sreality.cz/api/cs/v2/estates?category_main_cb=1&category_type_cb=2&locality_country_id=10001&per_page=' + str(100) + '&page='+str(x)+''for x in range(1, 1100)]
apartments_sell = ['https://www.sreality.cz/api/cs/v2/estates?category_main_cb=1&category_type_cb=1&locality_country_id=10001&per_page=' + str(100) + '&page='+str(x)+''for x in range(1, 110)]
start_urls = houses_rent + houses_sell + apartments_rent + apartments_sell
def parse(self, response):
jsonresponse = response.json()
for item in jsonresponse["_embedded"]['estates']:
yield scrapy.Request( self.base_api_url + item['_links']['self']['href'] ,
callback=self.parse_detail_page)
def parse_detail_page(self, response):
jsonresponse = response.json()
item = {} # empty item as distionary
try:
# check if the property is an apartment (1) or a house (2)
if jsonresponse['seo']['category_main_cb'] and 1 <= jsonresponse['seo']['category_main_cb'] <= 2:
item['PROPERTY_CODE'] = self.property_codes[ jsonresponse['seo']['category_main_cb'] ]
item['DEAL_CODE'] = self.deal_codes[ jsonresponse['seo']['category_type_cb'] ]
# house - category_main_cb=2
# apartment - category_main_cb=1
# pronájmu - rent category_type_cb=2
# prodej - sell category_type_cb=1
else:
return
item['API_URL'] = response.url
item['ID'] = response.url.split('/estates/')[1]
item['meta'] = jsonresponse['meta_description']
item['TITLE'] = jsonresponse['name']['value']
item['DESCRIPTION'] = jsonresponse['text']['value']
if jsonresponse['price_czk']['value']:
item['PRICE'] = jsonresponse['price_czk']['value']
else:
item['PRICE'] = ''
item['LONGITUDE'] = jsonresponse['map']['lon']
item['LATITUDE'] = jsonresponse['map']['lat']
item["ADDRESS"] = jsonresponse['locality']['value']
# gather images
item['IMAGES'] = set()
for images in jsonresponse['_embedded']['images']:
if images['_links']['dynamicDown']:
item['IMAGES'].add( images['_links']['dynamicDown']['href'])
if images['_links']['gallery']:
item['IMAGES'].add(images['_links']['gallery']['href'])
if images['_links']['self']:
item['IMAGES'].add(images['_links']['self']['href'])
if images['_links']['dynamicUp']:
item['IMAGES'].add(images['_links']['dynamicUp']['href'])
if images['_links']['view']:
item['IMAGES'].add(images['_links']['view']['href'])
# miscellenious items
for i in jsonresponse['items']:
if isinstance(i['value'] , list):
item[i['name']]= ''
for j in i['value']:
item[i['name']] += j['value'] + ', '
item[i['name']] = item[i['name']][:-2]
else:
item[i['name']] = i['value']
except Exception as e:
print ('Error: ' , e, '. for url: ', response.url )
yield item