Recently we’ve got a tricky website of dynamic content to scrape. The data are loaded thru XHRs into each part of the DOM (HTML markup). So, the task was to develop an effective scraper that does async while using reasonable CPU recourses.
Given
- Over 160K parcel IDs for quering government data website
https://loraincountyauditor.com/gis/report/Report.aspx?pin=0400014105002(use US proxies to view it).
What to get
- Tax info from Taxes dynamic area for each input parcel:
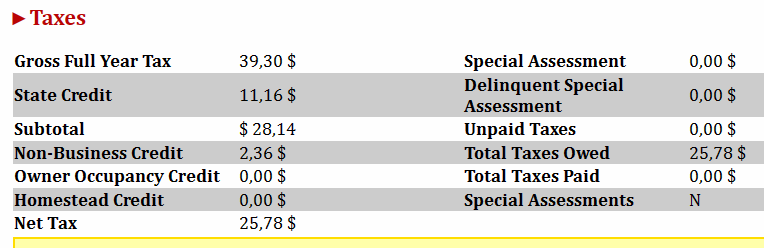
RAM & CPU challenge in browser automation
The website is a dynamic one requiring browser automation for its scrape. Yet, often the challenge is how to handle CPU and RAM in order to have a successful scrape. So, as you launch the code, monitor the CPU and RAM usage usign Task Manager, see below:
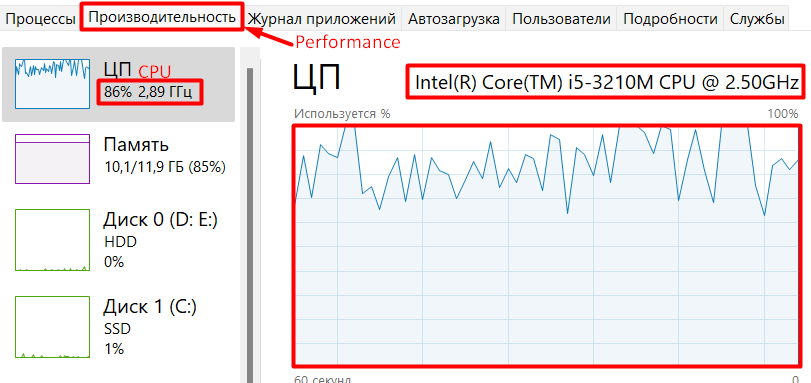
The script is designed to run manually (by 2-nd launch parameter, see it in next section). We regulate the number of browsers to scrape the website.
The launch parameters and service file & dir
node browsers-async.js 0 2 20000The script launch/run is straightforward. We just mention the parameters:
- 0 – headless browser {any other than 0} – headfull browser, one that works out full sized browser GUI.
- 2 – number of browsers for asynchronious work.
- 20000 – timeout value, max waiting time to find an HTML table data selector.
Note, the input data, parcels ids are taken from an input file parsels.txt (a sample is attached below). For the output we’ll write result files into a separate directory named data, you needing to create that folder in the project root.
Error handling
The website uses dynamic HTML markup, so the main error cause is that data are absent. Even though we set timeout for waiting and the browser performs scroll down.

For the wait we set up $selector_wait_check variable holding the timeout. So, if the server still doesn’t provide any data, we need to handle that error (Timeout error). $selector_timeout contains the number in milliseconds of max waiting time to grasp an HTML table data selector. One may set it thru the script console launch parameters.
const $selector_timeout = args.length > 2 ? args[2] : 20000; // default "selector wait" timeout
const tax_selector_check = "tbody[data-tableid=\"Taxes0\"] > tr[class=\"report-row\"] > td";
const tax_selector = "tbody[data-tableid=\"Taxes0\"]";
...
let $selector_wait;
await page.waitForSelector(tax_selector_check, {timeout: $selector_timeout} )
.then(() => { //console.log("Success with selector.");
}).catch((err)=> {
console.log("Failure to get tax info HTML element. ERR:", err);
failed_pool.push(chunk[i]);
dump(failed_pool);
$selector_wait = 0;
} );
if ($selector_wait===0){
continue;
}Proxying
Since the website is US IPs restricted, we use the ProtonVPN service to mimic US requests’ origin. The ProtonVPN application gets activated at the OS level (Windows in our case), so no code changes are inflicted.
Load timeout
The data load timeout makes the browser wait more or less till needed data for the tax info are loaded. It’s the third launch parameter, see above. So we’ve played around with that value to reach the best performance. Depending on the different load timeout value, we had a different scraper performance rate. See the table below:
| Dynamic data load timeout, seconds | Performance rate, success vs all request |
| 10 | 80% |
| 20 | 95% |
| 30 | 97% |
Data post-processing
Since we scrape each product into a separate [JSON] file, we need to concatenate the data. The easiest way is to use Windows utility.
Get-Content *.json | Set-Content result.jsonWe then append commas to the end of each line and bracket the whole content with [ ] using Notepadd++ for that. Thus we get a valid JSON:
[
{ "Full Year Tax":"145,26$"… },
{ "Full Year Tax":"139,00$"… },
{ "Full Year Tax":"100,00$"… }
]
The scraped data issues
Sometimes the website returns an empty data table like the following:
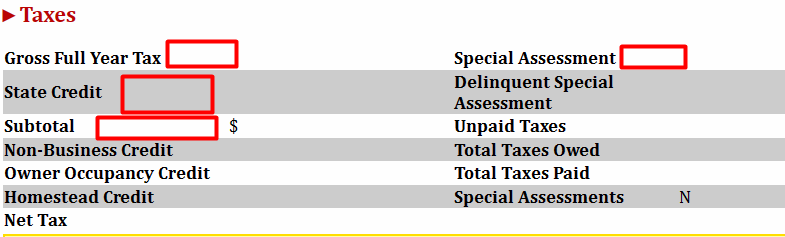
So the parcels with the missed data as well as Timeout error parcels we discard from output but save them into the failed-parcels.txt file.
Whole code
The code is in the public github repo, please clone or fork it to try.