Lately I needed to scrape some data that are dynamically loaded by “Load more” button. A website JavaScript invokes XHR (or Ajax request) to fetch a next data portion. So, the need was to re-run those XHR with some POST parameters as variables.
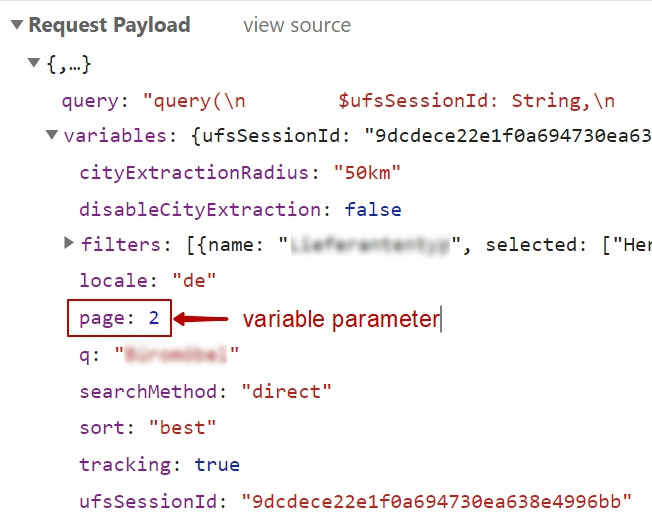
So, how to make it in Node.js?
