In the post we share some basics of classification and clustering in Machine learning. We also review some of the cluster analysis methods and algorithms.
Classification
Classification is the process of ordering a fset of objects that have similar classification features (one or more properties), the properties being selected to determine the similarity or difference between these objects.
A classification task is often called predicting of a categorical dependent variable (i.e., a dependent variable that is a category) based on a sample of continuous and/or categorical variables.
Clustering
Clustering is designed to divide a collection of objects into homogeneous groups (clusters or classes). If the sample data is represented as points in the feature space, then the clustering problem is reduced to the definition of “cluster points”.
The goal of clustering is to search for existing [data] structures.
Clustering is a descriptive procedure, it does not draw any statistical conclusions, but provides an opportunity to conduct exploratory analysis and study the “data structure”.
Comparison of classification and clustering
| Feature | Classification | Clustering |
|---|---|---|
| Controllability of training | Supervised learning | Unsupervised learning |
| Strategy | Learning with a teacher | Teaching without a teacher |
| Whether the class label is present | The training set is accompanied by a label indicating the class to which the observation belongs | Training set class labels are unknown |
| The basis for the classification | New data is classified based on the training set | A set of data is given in order to establish the existence of classes or clusters of data |
Figure 1 shows the classification and clustering tasks schematically.
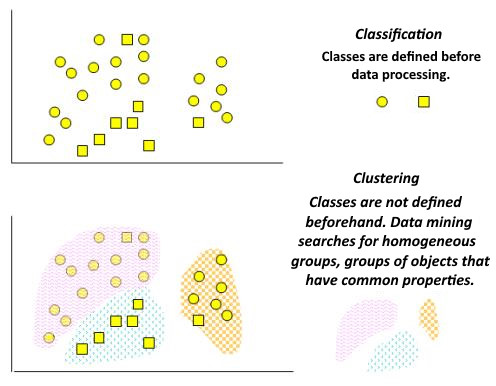
Clusters can be non-overlapping, or exclusive, and overlapping. A schematic representation of non-overlapping (left) and overlapping clusters is given in Figure 2.

Cluster analysis
It should be noted that as a result of applying various methods of cluster analysis, clusters of different shapes can be obtained. For example, clusters of the “chain” type are possible, when clusters are represented by long “chains”, clusters of elongated shape, etc., and some methods can create clusters of arbitrary shape.
Different methods may seek to create clusters of certain sizes (for example, small or large), or assume that the data set contains clusters of different sizes.
Some cluster analysis methods are particularly sensitive to noise or outliers, while others are less so.
As a result of using different clustering methods, different results can be obtained, this is normal and is a feature of the operation of a particular algorithm.
These features should be taken into account when choosing the clustering method.
To date, more than a hundred different clustering algorithms have been developed.
Clustering algorithms and methods
- Algorithms based on data partitioning (Partitioning algorithms), including iterative ones:
- splitting objects into k clusters;
- iterative reallocation of objects to improve clustering.
- Hierarchical algorithms:
- agglomeration: each object is initially a cluster, the clusters, connecting to each other, form a larger cluster, etc.
- Density – based methods:
- are based on the ability to connect objects;
- ignores noise, finding clusters of arbitrary shape.
- Grid – based methods:
- quantization of objects into grid structures.
- Model-based methods:
- using the model to find the clusters that best match the data.
The same post in Russian (private).