 The anti scrape bot service test has been my focus for some time now. How well can the Distil service protect the real website from scrape? The only answer comes from an actual active scrape. Here I will share the log results and conclusion of the test. In the previous post we briefly reviewed the service’s features, and now I will do the live test-drive analysis.
The anti scrape bot service test has been my focus for some time now. How well can the Distil service protect the real website from scrape? The only answer comes from an actual active scrape. Here I will share the log results and conclusion of the test. In the previous post we briefly reviewed the service’s features, and now I will do the live test-drive analysis.
Stage 1: Soft scrape
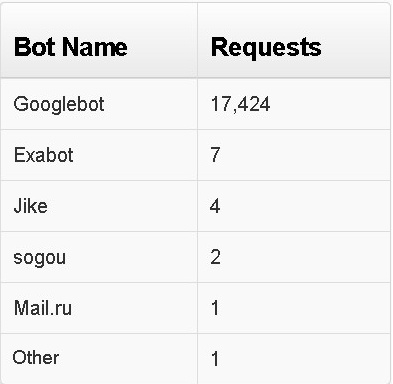
I wrote a simple PHP scraper that requested the site with 1 Pages Per Minute for 10 min, a kind of a soft scrape. For protection I placed the website under Distil guard with only monitoring settings. The guard found 4 bad bots and some more human views.
Trap Statistics Breakdown:
JavaScripts Check failed, 5
JavaScript Not Loaded, 5
Besides this, Distil recognized the violating IP, with 10 violations. This is the exact IP where our linux php engine resides.
Stage 2: Mask under Googlebot
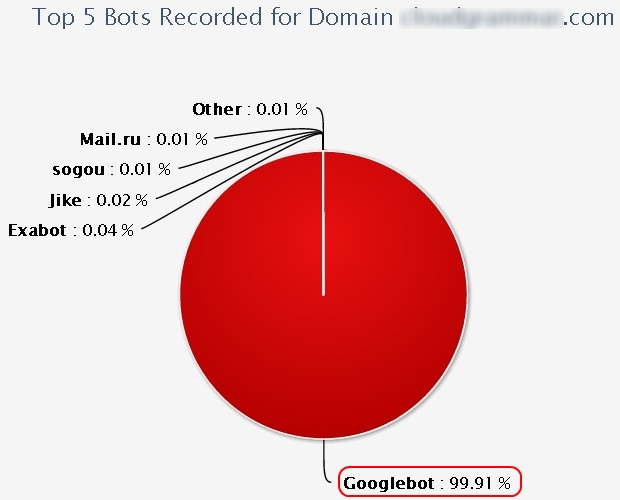
 Fake user agent.
Fake user agent.
Why not do a disguise as the crawl engine for scrape? The site’s PageRank equals 2, giving ground for quite frequent crawl engine visits. Then I used another trick for page access. I fully disguised the scraper program as a Googlebot using fake headers and a fake user agent (the php code, see in a section of ‘Ron‘).
In Distil, for monitoring, I set up a 19 pages per minute threshold to monitor, and for scrape I set 20 or more pages per minute.
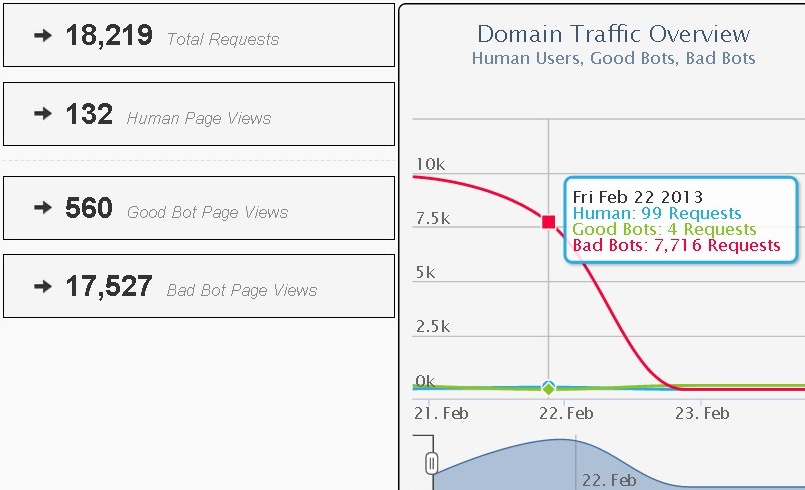
I started 180 masked requests to the target site. The anti-scrape-bot service recognized the Googlebot as a bad bot, yet it did not stop access (only monitoring). Result was: 180 Bad Bot Page Views. Distil recognized the malicious attempt with this kind of Googlebot masked scrape. Later I set the scraper for more jobs, so the protection and recognition results are shown in the above figures.
Stage 3: Scrape thru proxy
How about accessing the site through other IP proxying? I turned to ScraperWiki as the simplest tool for hiding/changing the IP.
I ran the scraper program on ScraperWiki, accessing the site with the same interval – 3 seconds (20 pages per minute). For some of the 180 requests the response time was over 3 sec (10 times more than usual, quite delayed). Several times the scraper exception was thrown with no data from the page being loaded:
Error curl ( URL = {$url} ) : Operation timed out after 10001...more Caught exception: Error to get page content on url = http://xxxxxx.com/?a=28 : Operation timed...more 03:47:21
Starting with the 25th request, the response time increased a lot, thus the scrape-bot protection was intercepting the scrape program requests. Distil was only monitoring: no captcha, no blocking, no dropped requests (since the settings were so configured). Besides the malicious agents (see images above), the service recognized the malicious IPs and threat countries. The following figure shows the precise monitoring results with good style recognition for good bots (crawl engine bots) and bad bots (malicious scraper programs):
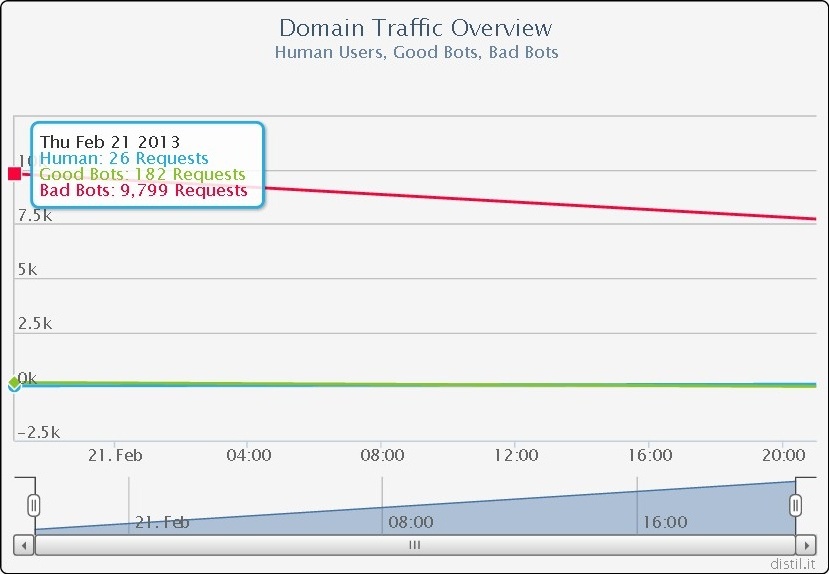
Stage 4: Go over the set limit
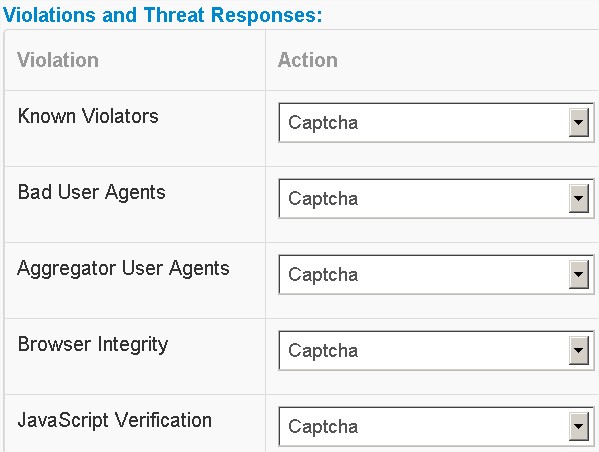
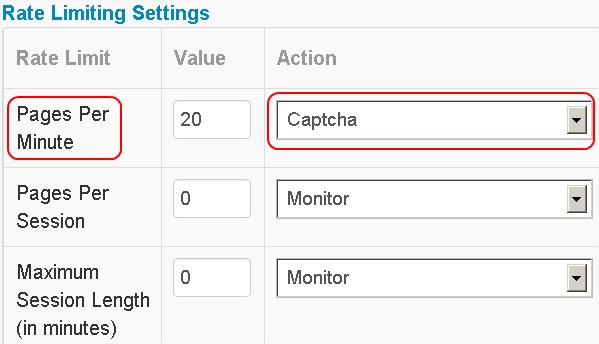 Next I decided to execute the scraper beyond the settings’ limits for the domain under protection. In the main window click on the domain name to see all the settings and threat analysis of the domain. Go to Configurations -> Content Protection settings to change settings. There I set the captcha popup for all of the Violations and Threat Responses. The 20 pages per minute (PPM) threshold has also been set with captcha action (see figure at right). I was curious to see if the service would really be able to guard against improper access through captcha. Initially captcha did not appear even when I manually hit over 60 times for a minute. But soon, as I continued to hit, Distil issued a captcha with a warning of suspicious behavior. The service passed this test.
Next I decided to execute the scraper beyond the settings’ limits for the domain under protection. In the main window click on the domain name to see all the settings and threat analysis of the domain. Go to Configurations -> Content Protection settings to change settings. There I set the captcha popup for all of the Violations and Threat Responses. The 20 pages per minute (PPM) threshold has also been set with captcha action (see figure at right). I was curious to see if the service would really be able to guard against improper access through captcha. Initially captcha did not appear even when I manually hit over 60 times for a minute. But soon, as I continued to hit, Distil issued a captcha with a warning of suspicious behavior. The service passed this test.
Performance issue in caching mode
The service claimed not to limit but rather enhance the performance of the site under the scrape-bot protection. Since for monitoring and blocking it takes active caching, I used a trace route service to measure the site’s load speed with these results:
- without caching, ping: 124 ms.
- with caching, ping: 125 ms.
According to the results, the performance did not suffer loss, but neither was it enhanced. The overall monitoring results are shown here.
Caching bug
I found a caching bug when in real time I changed all the pages on the site (one page was already cached in a browser). I reloaded the pages in the browser multiple times expecting to see the new, changed content. After some of the loads, that page’s content remained the same (old), and after other loads the new content appeared. The distributed content delivery network had not yet been optimized for this trick. For other (not previously loaded) pages, only new content was browsed.
Conclusion
Distil proved its ability as an anti-scrape-bot service. It does JavaScript embedding for bot recognition and threat analysis as well as captcha popups and blocking on demand. I was generally satisfied with Distil’s results. The website’s performance did not suffer because of the caching in the distributed content delivery system.