
Most scraping solutions fall into two categories: Visual scraping platforms targeted at non-programmers ( Content Grabber, Dexi.io, Import.io, etc.), and scraping code libraries like Scrapy or PhantomJS which require at least some knowledge of how to code.
Web Robots builds scraping IDE that fills the gap in between. Code is not hidden but instead made simple to create, run and debug.
Javascript scraping
Advance of HTML5 is changing web scraping. Websites are no longer just text with links but are instead advanced applications rivaling desktop applications.
Traditionally scraping by downloading HTML no longer works. Running JavaScript is necessary to get the content. Web Robots specialize in difficult to scrape websites and have created scraping tool chain that drives the latest version of Chrome browser. Therefore they can handle anything a modern browser can handle.
Here is the first look review of their tools.
Scraping IDE
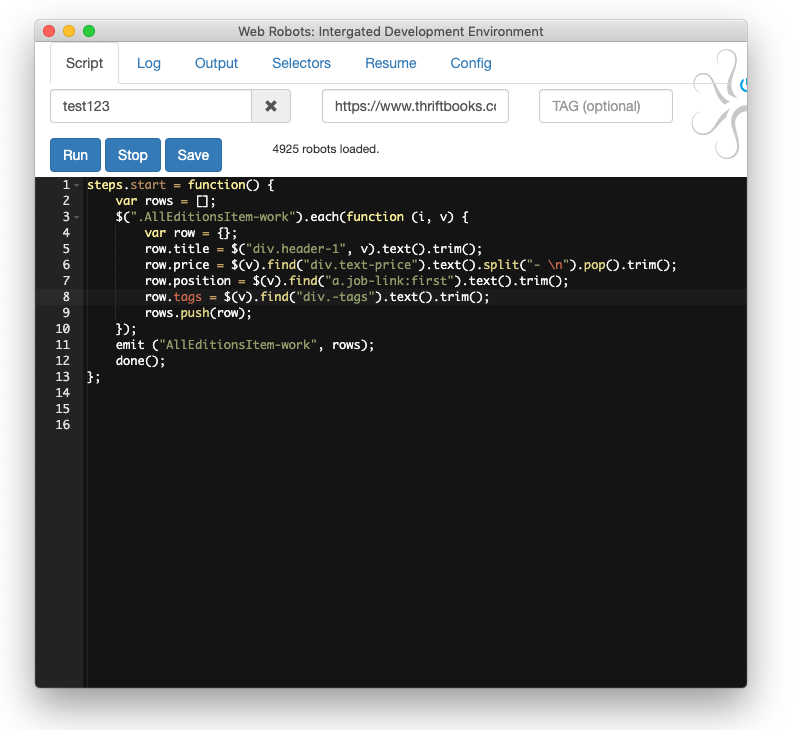
In a nutshell Web Robots scraping tool is a Chrome extension which drives Chrome browser.
Instead of building fully visual scraper builder Web Robots do not hide code from users. Visual scrapers are appealing in theory but often code writing is necessary for complex web scrapes.
Web Robots embraces that, and their tool is designed to make coding quick, easy and familiar. Code is written directly in the extension. It does syntax highlighting, code validation and linting. Users can write, run, view results and debug in one place.
Scraper robots are written inside the extension using familiar JavaScript and jQuery.
Compared to other tools there are many advantages:
- Easy development and debugging because robot’s code snippets can be tested in Chrome Developer Tools built into Chrome
- Doing test runs gives immediate visual feedback in browser
- Scraped data is visible in real time
- Chrome handles cookies and session management
- Browser fixes messy HTML and present valid DOM for scraping. So no need to worry about mismatched tags
- Scraping APIs is easy with jQuery AJAX calls
- No need to install anything on client
- No need to have a server
Feature comparison with full scraping frameworks:
server |
||||
software |
||||
JavaScript |
||||
runtime |
||||
on Cloud |
Feature comparison with Visual Web scrapers
| Ripper |
||||
software |
||||
based |
||||
JavaScript |
||||
Data portal
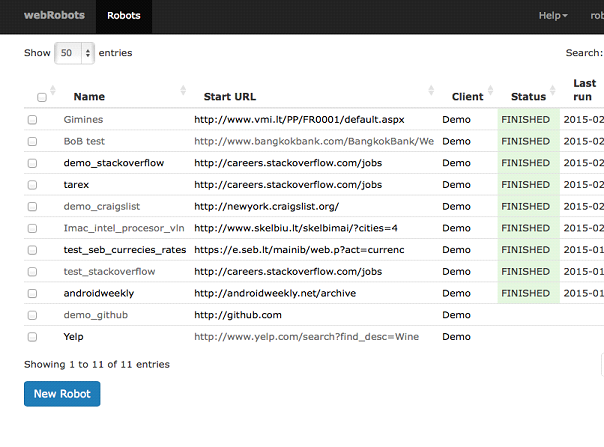
Scraping code and extracted data are saved to Web Robots portal. All data is archived in portal and it can be downloaded in CSV or JSON.
Once robots are tested and reliable users can run them from portal and cloud based machines will do the scraping.
Data validation
Data is only valuable if it can be trusted. Web Robots has a lot of checks to make sure scraped data is correct. Some checks are mandatory like:
- Price field must be present, more than zero, less than 1000
Some are warnings:
- Price is significantly different from historic average.
Extra Features
Web Robots provides services to B2B customers only. Demo accounts can be requested by contacting Web Robots at https://webrobots.io/contact-us/
Paid customers receive additional services and powerful features:
- Large scale crawling and fetching millions of pages using many parallel scrapers
- Data export directly to customer databases or cloud storage
- Data checking and validation with alerting
- Full debugging information from automated cloud runs (screenshots, HTML snapshots, errors)
- Scrape job automation with flexible scheduling
- Centralized proxy management with support for datacenter and residential proxies
- Full service script writing and testing
Conclusion
Web Robots offers a scraping tool that is a more advanced option than most visual web scrapers but simpler and easier to use than PhantomJS or Selenium. It can access dynamic websites that cannot be scraped using old school scraping libraries like Scrapy or Mechanize.
It requires some coding in JavaScript so it’s not for every user. But the reward is virtually unlimited scraping possibilities.
Tutorial: http://webrobots.io/support/