Here I’d like you to get familiar with an online scraping protection service called BotDefender. It’s interesting both to know how to use it (in case you want to protect your data) and to understand how it works in case you ever come across it while collecting data.
BotDefender
BotDefender is a service that protects online e-commerce stores from the automated retrieval of their items’ prices – so their competitors can’t use those prices to outprice them. This anti-scraping tool is crucial if you want to hide your inventory prices from e-store competitors. It’s also interesting to look at from a scraping point of view.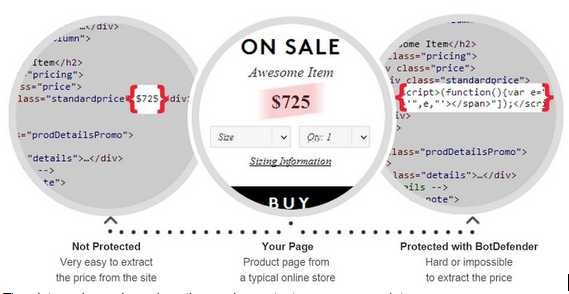
Usually the price value is displayed as a simple HTML tag value (left circle), but BotDefender transforms it into a JavaScript function (right circle). The latter then uses BotDefender’s service API to access the stored prices values, in order to display the price on the site (but not in the HTML).
The service leverages two techniques (for two plans correspondingly) for protecting e-commerce data prices:
Tar pitting technique (free plan)
This technique makes a JavaScript callback to retrieve the price from the BotDefender servers. It forces scrape bots as well as all the page visitors to request content from BotDefender servers. This should stop scrapers which can’t render JavaScript by default.
The server detects bots trying to scrape the information by monitoring IP addresses that request enormous amounts of prices very quickly from the BotDefender server. Once a bot is detected, Botdefender can block the IP address. The effect should work without disrupting the experience of the site’s regular visitors. Still, developers recommend to caching the page’s response for 24h to increase performance. You can read more on this anti-scraping technique here.
Obfuscation technique (paid plan)
This additional counter-scraping technique changes the values to be both HTML and JavaScript encoded, thus making it increasingly difficult for a bot to decipher. The decoding is made on the client side (browser code), thus there are no extra requests or time delays – which can occur using the tar pit technique.
Practicality to set up and use
As an engineer, my first question is always: “How easy is this really to install on my ecommerce site?”
It seems like a cool feature to protect e-commerce site from bots that harvest prices, but anytime you get a service like this there’s often a practicality catch.
Upon further investigation, it turned out that you need to connect your e-commerce data to Lokad through one of the third party inventory apps using it’s web API.
Here is the list of them:
- Brightpearl
- Linnworks
- TradeGecko
- Vend
- Quickbooks through Webgilit.
If your business isn’t already attached to any of those apps, you could try to use the BotDefender API to get your prices stored on and retrieved from BotDefender server. They do offer client-support if you get stuck.
Real case plugging in to BotDefenter:
My e-commerce system is not using any of those apps, so I decided to try connecting to BotDefender directly.
The only option I had was to send a file with all my inventory prices to the Lokad server, however, my inventory system (yii-driven) was in a massively different format than the one accepted by Lokad.
It would have taken me ages to convert the labels, generate and compose new fields and so on. So after a few initial trials, I decided to drop the idea of actually test-driving BotDefender.
“How would I bypass this kind of scrape protection?”
Suppose your competitor has successfully plugged into BotDefender’s server to protect his e-commerce site prices. What would be the ways to bypass these price stubs and extract them? From my own personal scraping experience and looking at BotDefender’s concept, the best solution would be to build a scraper that could behave like human. Otherwise it would get detected and slowed down.
This means you would need to:
- Scrape prices slowly, leaving a long time interval between pages
- Change site login credentials, to imitate different users (if site requires login)
- Change IP address frequently, by proxying
- Remove any items that might identify your scraper between pages
- Be able to evaluate JavaScript within your scraper’s logic
- Avoiding sending Bots from AWS can help.
For now, my best advice is to start extracting slowly (building up speed as you go), evaluate and render the JavaScript whenever possible and make your script read text encoded with JavaScript.
Another quick thing to mention, is that the HTML slugs that get generated (instead of real prices) are supposed to change pretty regularly, which will make it really difficult for your scraper to identify real price values changes. It just means you’ll need to manually check your data quality regularly!
Wrap Up
For the Ecommerce Site:
BotDefender is actually a pretty smart tool since it first identifies the bot and then deploys the anti-scraping measures, reducing the load on your servers. In fact, the extra calls to the service servers or on site decoding algorithm (for high-traffic sites) are claimed to create zero overhead for end-users.
The main holdup in using this service, is the requirement to plug your system’s inventory into Lokad. But if you’re already using one of the third party apps I mentioned earlier, that shouldn’t be too much of an issue.
For the Scraper:
Sites are increasingly looking for ways to protect their data, so each new piece of technology should be given its due.
This particular technology is still fairly basic and is likely easy enough to work around given the right knowledge and some time – though it will likely create some extra work for you!
As with any data project they key to avoiding trouble with this is to quality check your datasets to be sure you are getting the right data.
2 replies on “BotDefender Analysis”
Is interesting the concept of “prices as js function”… do you know any site where botdefender is enabled now? I’d like to see it working….
On the other side, the stuff related to traffic detection, ip blocking…. is not new. Probably is the most used strategy against bot and the most useless also. A good pool of proxies and a proper IP balance can deal with it.
To see the sites where BotDefender is enabled just visit its home page and check the ‘Customers’ upper menu tab.