
In the modern web 2.0 the sites that have valuable data (eg. business directories, data aggregators, social networks and more) implement aggressive blocking measures, which can cause major extraction difficulties. How can modern scraping tools (eg. Sequentum Cloud) still be able to fetch data of actively protected sites?
Sequentum is a closed source point and click scraping platform that integrates everything we need to bypass anti-bot services, including management of browsers, device fingerprints, TSL fingerprints, IP rotation, user agents, and more. Sequentum has had its own custom scraping browser for more than a decade, and as one of the most mature solutions on the market, they are able to support atomic level customization for each request and workflow step. As such, Sequentum Cloud is an out-of-the-box advanced scraping platform with no upfront requirement to stand up infrastructure, software, or proxies. It also has a very responsive support team, which can be useful in coming up to speed on one’s approach and is quite unique in the scraping industry. In this test, we were able to configure a site with very aggressive blocking and, with some refinement of error detection and retry logic, were able to get some of the most protected data consistently over time.
For this test, we pointed their tool at a major brand on Zoro.com, a site with aggressive blocking. Initial attempts yielded 32K records which was 94% of the estimated 34K entries. We worked with support to understand the ways to customize the advanced error detection and retry logic included in the Sequentum platform to the behavior of the Zoro.com site and was able to get 100% of the data. In this article we are sharing what we have learned.
The overall test results of Sequentum Cloud and Oxylabs API (shared in a post) might be summarized in the following comparison table.
| Success rate | Avg. seconds per page | Estimated cost | Rating | |
|---|---|---|---|---|
| Sequentum Cloud Agent | 100% | 0,4 (provided 10 browsers) | $12 ($3.75 per 1GB traffic of res. proxy) |  |
| Oxylabs' API | 90% | 11 | ~$60 ($2 per 1000 requests) |  |
The preconfigured API [of Oxylabs] is already built [and maintained] for an end user. Sequentum Cloud Platform is rather an open tool, and agents can be customized in a myriad of ways. Hence it can take longer to build a working agent [compared to a ready-API] but for the most part a custom agent is the better way to apply in an industrial scale for one’s custom use case.
Error handling with retries
Error handling with retries means that a scraper requests the same page over and over again (with the limit of Max retries set in an Agent settings) until it gets a previously inaccessible page.
With the help of support, we have an updated agent that handles the blocking issues mainly by retrying URLs.
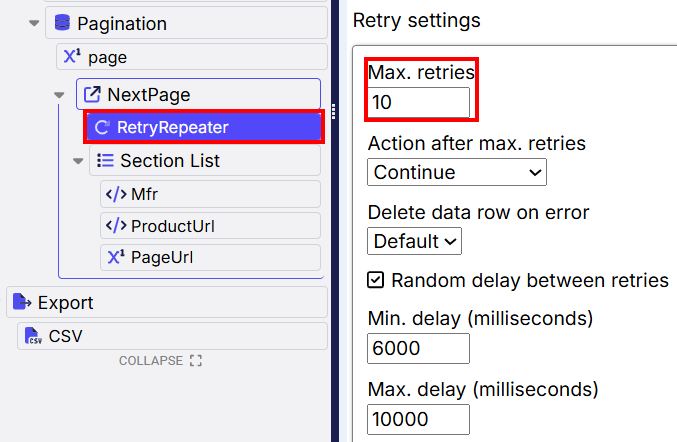
URL retry settings
Here’s how one can implement URL retry in an agent:
- Open an Agent.
- Select the “URL” command.
- Click the “Options” tab.
- Under the “Browser” section, uncheck “Ignore error codes if content is
received”. This is important for proper error detection (as shown in screenshot below):
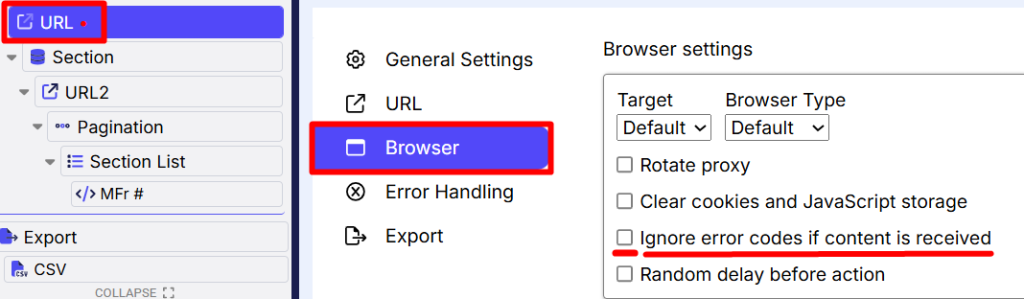
- Click the “Error Handling” option.
- From the dropdown menu, select “Retry Command”. You can also refer to the Error Handling details from here Error Handling Overview.
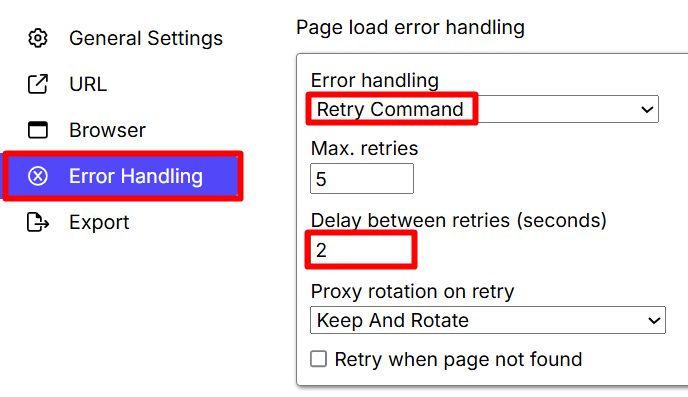
- Set the “Delay between retries” to a suitable value. This determines the
pause between retry attempts (as shown in the screenshot above). - Do not forget to “Save options”.
By implementing these steps, the agent will automatically retry URLs if it
encounters errors, significantly reducing the impact of blocking. One can
adjust the number of retries and the delay between them as needed, depending on the specific website’s behavior.
Smart categories URLs setup to be able to catch all [hidden] data
The issue of retrieving only a fraction of the total data on the highly protected data aggregators (eg. Zoro.com) is due to limits that a data aggregator usually sets to the data exposure. See the example of Xing limiting data exposure with 10K+ companies per a search request.
Eg. zoro.com/b/3M/ brand has over 34.5K items and the data aggregator might not show them all. But we may set up the scraper to request subcategories, having found those URLs. See some of them are the following:https://zoro.com/b/3M/?fqc:category=1
https://zoro.com/b/3M/?fqc:category=z1
https://zoro.com/b/3M/?fqc:category=23
https://zoro.com/b/3M/?fqc:category=z10
https://zoro.com/b/3M/?fqc:category=z9
Cookie including script
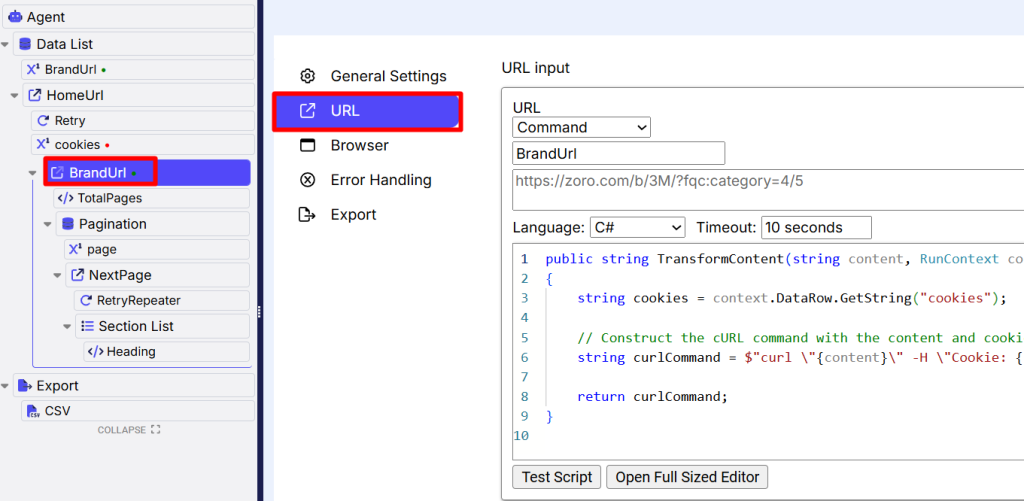
Sequentum support provided me with an advanced agent that facilitates adding a Cookie for some requests. The trick was to request a main page with a full-sized, authentic browser and thus get server/website cookies values. Then these cookie values are added into a lightweight Static browser for requesting Brand URLs. For the Brand URLs the C# transformation script is the following:
public string TransformContent(string content, RunContext context)
{
string cookies = context.DataRow.GetString("cookies");
// Construct the cURL command with the content and cookies passed as headers
string curlCommand = $"curl \"{content}\" -H \"Cookie: {cookies}\"";
return curlCommand;
}See the place where a cookie including script was applied:
Pagination challenge
Previously, the agent was using the action repeater command with element.click() in JS Action to interact with the pagination and move to the next page dynamically. However, we updated the pagination approach. Instead of clicking the pagination element, the Next btn-link, we navigate new pages by forming a request to a next page URL. The pages are iterated using the added datalist command.
For that we first save total pages figure into a TotalPages variable to later generate page indexes at Pagination command and List tab with help of Regex:
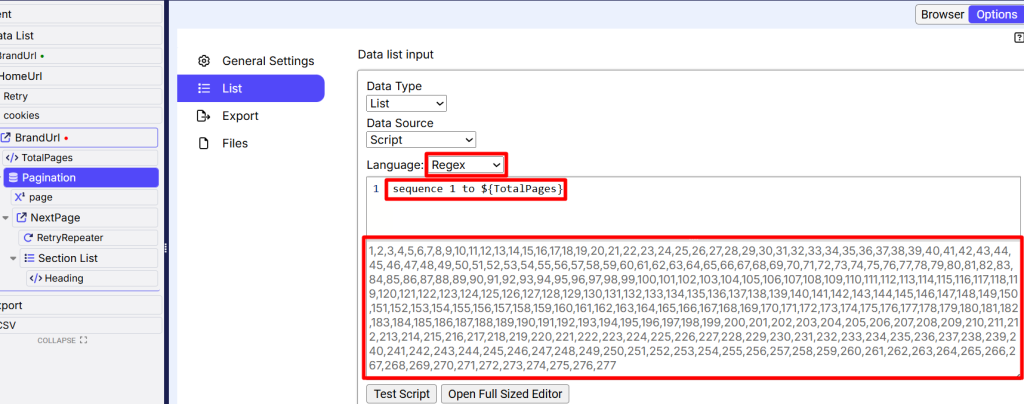
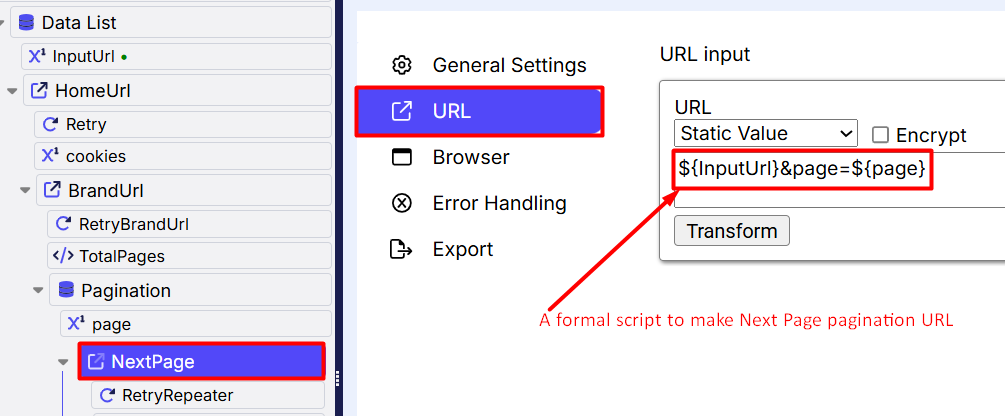
Now in the “NextPage” command, we are using the following script to make direct pagination URLs:${BrandUrl}?page=${page}
——————————————————-${BrandUrl} refers to the base URL of a brand page,${page} represents the page number.
NextPage command requests were still partially blocked. So, with support’s help we’ve got an updated agent that handles the blocking issues mainly by retrying URLs.
Results
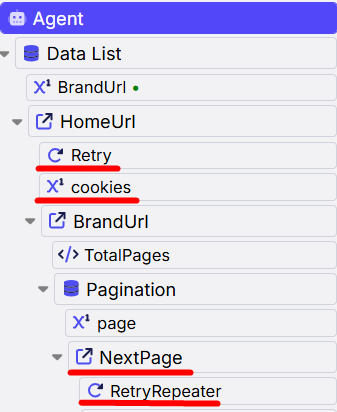
So, the error handling using retries works successfully. The support team provided me with a professional level Agent with retries, cookies handling, NextPage script and more. See the figure to the right. This proved that even the most protected sites, such as zoro.com, might be bypassed with Sequentum Cloud, a modern scraping suite
…even the most protected sites such as zoro.com might be bypassed with Sequentum Cloud, a modern scraping suite.
See the agent file attached below:
Numerical figures
The result of a major brand in the Zoro.com data directory issued in 32K records, being 94% of estimated 34K entries. Some URLs were not harvested even with 10 retries each.
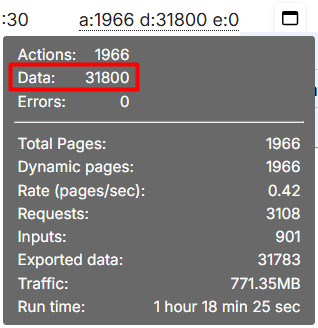
Retry Errors? Scrape 100%? YES
The 94% harvest results might not be quite right for some clients. So, we’ve turned to support if one is able to rescrape those missing [pagination] urls…
The response was surprised & overwhelming, highlighting a built-in Sequentum Cloud feature: Agent Retry Errors. We’ve made this topic a separate stand-out post, enjoy and let us know what you think.
Speed up by leveraging multiple Browsers in parallel
My initial thought was to increase the speed by multithreading, using max number of simultaneous browsers. The Max number of [simultaneous] browsers is a feature of Sequentum Cloud.
At first try an increase of browsers’ number did not result in speed improvement. The reason of initial failure was the (Zoro) website’s blocking on cookies. So, when numerous requests of a single session transpire, they all have the same cookies, the server blocks them. The running multiple sessions in parallel with each having their own cookies facilitates a non-blocking execution. However, the overall cost remains the same because one pays for server time and bandwidth for each session only. The way we ran them was a cheapest approach. If one runs multiple sessions, it might cost more because each session runs in its own mini container.
There is tremendous flexibility in how one configures agents on Sequentum’s platform. In the beginning it can appear a bit opaque/ unclear as to why there are errors though. As we have tested the agent with multiple browsers [sessions] the result appeared to be excellent. See figures below.
During the Agent Setup Run you tick up Split up inputs and process in parallel and choose a parallel operational browsers’ number (Total runs):
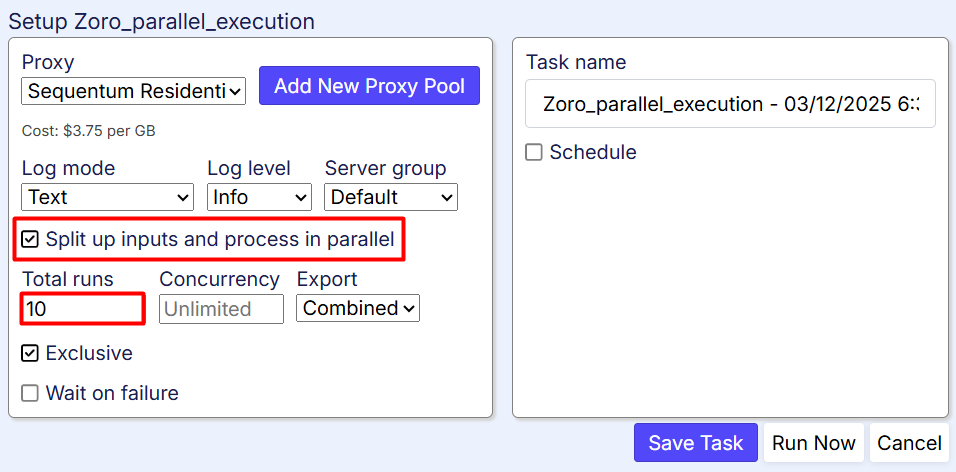
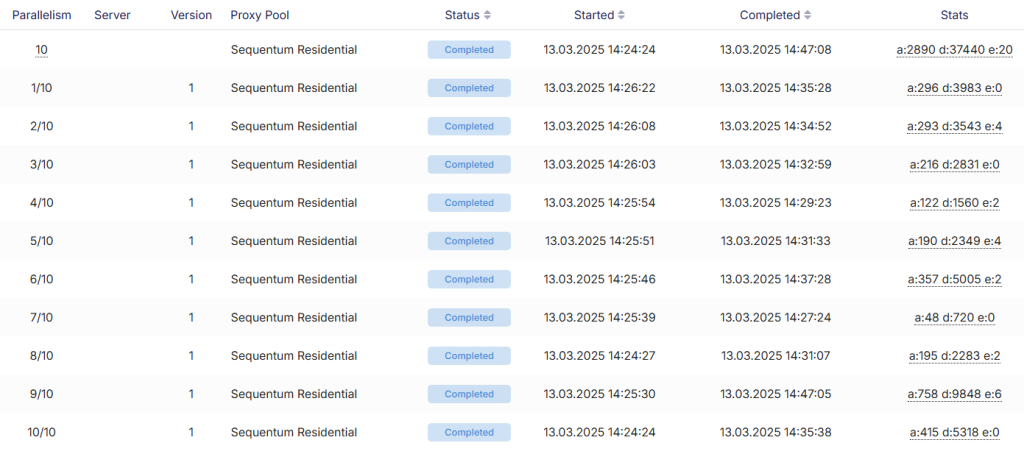
The execution result been excellent. The speed increase (compared to a single thread run) came to over 3x:
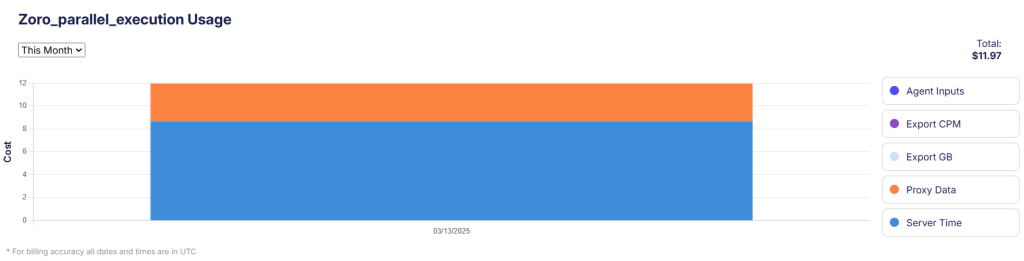
The usage stat shows the split of Server time & Proxy cost:
Read more on how to Configuring Multi-Session with Sequentum Cloud.
Conclusion

The new Sequentum Cloud platform proved itself to be an excellent scraping tool that deals with tough targets, particularly highly bot-protected ones. The trial has revealed excellent and much-needed features: multiple browsers parallel execution, lightweight Static browser (in addition to full-size Dynamic browsers), Cookie insertion, generating pages based on pagination max value, User-agent pools, own Residential proxies, Agent Error Retrying and more.
Some of these features are unique to the Sequentum Cloud. I highly recommend trying and using the Sequentum Cloud platform, especially for scraping highly bot-protected web targets. Good luck!