Online marketplaces In the marketplaces people offer their products for sale. Similar to garage sales, but online. (eg. eCrater, www.1188.no). Easy to scrape since they are usually free and do not tend to protect their data.
Business directories The usually huge online directories targeted at the general audience. (eg. Yellow Pages). They do protect their data to avoid duplication and loss of audience. See some posts on this.
Support us by purchasing the book (under $5) on this topic.
In today’s web 2.0 many business websites utilize JavaScript to protect their content from web scraping or any other undesired bot visits. In this article we share with you the theory and practical fulfillment of how to scrape js-dependent/js-protected websites.
Most of the answers to the question in internet forums are given by services that automatically solve captchas. They provide services to solve CAPTCHA rather than to fully skip it.
Recently I received this question: What are the best online resources to acquire data from?
The top sites for data scrape are data aggregators. Why are they top in data extraction? They are top because they provide the fullest, most comprehensive data [sets]. The data in them are highly categorized. Therefore you do not need to crawl and fetch other resources and then combine multiple-resource data.
Those sites fall into 2 categories:
Goods and services aggregators. Eg. AliExpress, Amazon, Craiglist.
Personal data and companies data aggregators. Eg. Linkedin, Xing, YellowPages. For such aggregators another name is business directories.
The first category of sites and services is quite wide-spread. These sites and services promote their goods with the goal of being well-known online, to have as many backlinks as possible to them.
The second category, the business directories, does not tend to reveal its data to the public. These directories rather promote their brand and give scraping bots minimum opportunity for data acquiring*.
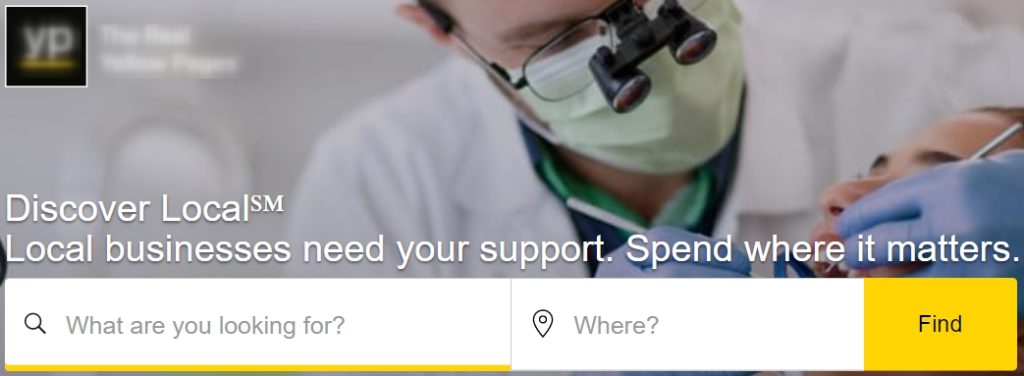
Consider the following picture where a company’s data aggregator gives to the user only 2 input fields: what and where.
You can find more of how to scrape data aggregators in this post.
————– *You have to adhere to the ToS of each particular website/web service when you perform its data scraping.
In this post I’d like to share my experience with scraping data aggregator/business directory using the residential proxy of the Bright Data proxy provider in conjuction with its proxy manager.
We’ve already introduced you to the theory behind the newNO CAPTCHA reCAPTCHA v2, but now we come to the practical integration part. Here we’ll share how to insert and configure “NO CAPTCHA reCAPTCHA” into a web page.
 My goal was to retrieve data from a web business directory.
My goal was to retrieve data from a web business directory.


 Question: Is there any way to include captcha on the site and at the same time prevent services like
Question: Is there any way to include captcha on the site and at the same time prevent services like