Recently I was asked to help with the job of scraping company information from the Yellow Pages website using the ScreenScraper Chrome Extension. After working with this simple scraper, I decided to create a tutorial on how to use this Google Chrome Extension for scraping pages similar to this one. Hopefully, it will be useful to many of you.
1. Install the Chrome Extension
You can get the extension here. After installation you should see a small monitor icon in the top right corner of your Chrome browser.
2. Open the source page
Let’s open the page from which you want to scrape the company information: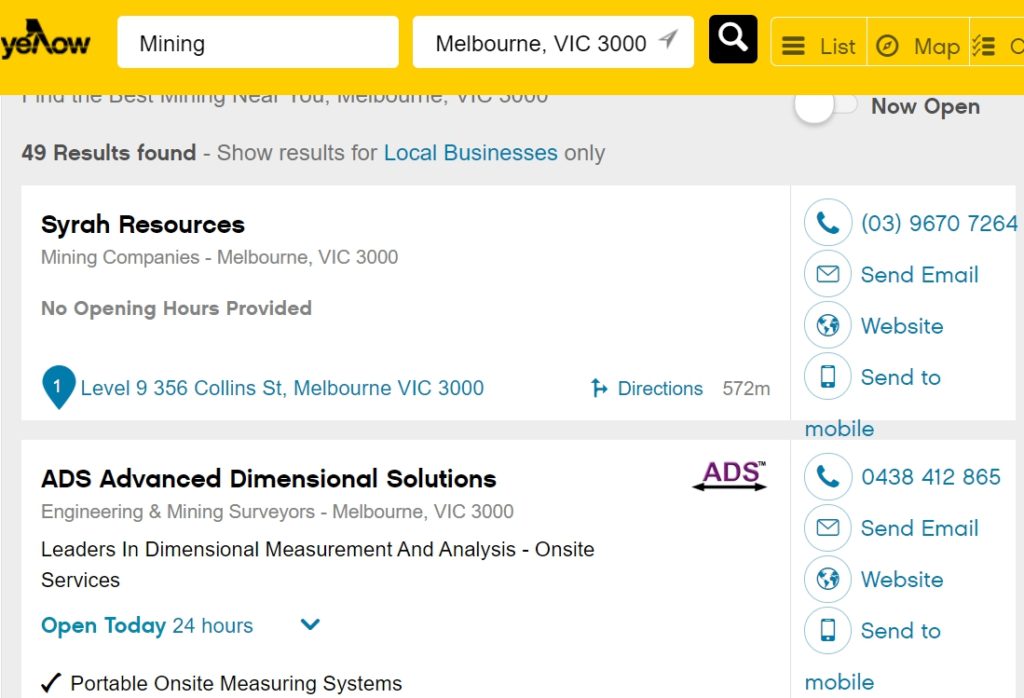
3. Determine the parent element (row)
The first thing you need to do for the scraping is to determine which HTML element will be the parent element. A parent element is the smallest HTML element that contains all the information items you need to scrape (in our case they are Company Name, Company Address and Contact Phone). To some extent a parent element defines a data row in the resulting table.
To determine it, open Google Chrome Developer Tools (by pressing F12 or Ctrl+Shift+I), click the magnifying class (at the bottom of the window) and select the parent element on the page. I selected this one: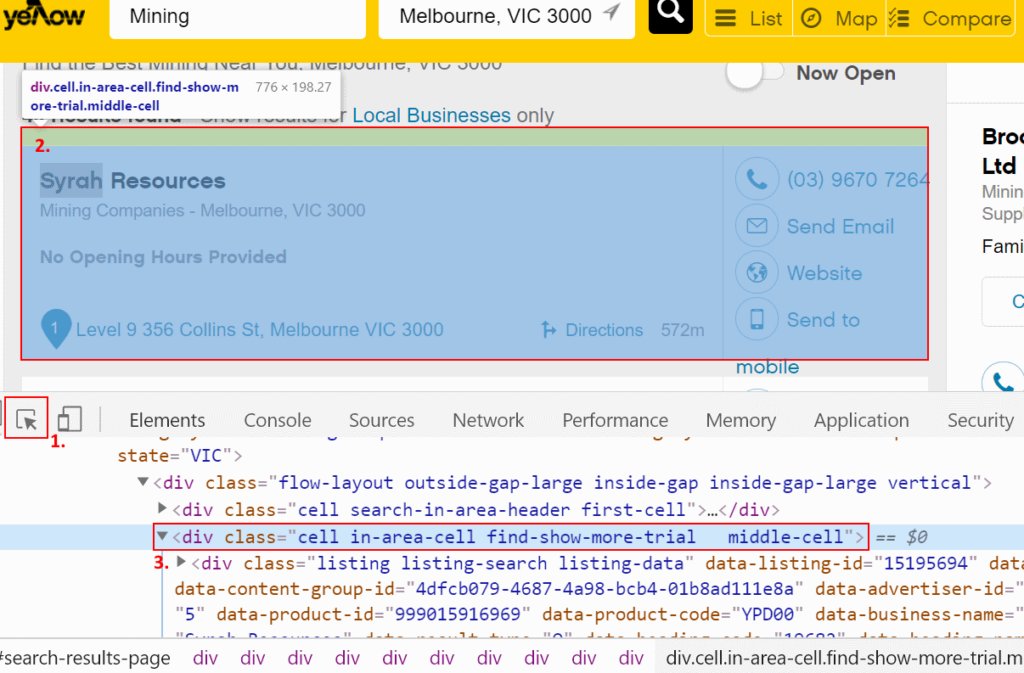
As soon as you have selected it, look into the developer tools window and you will see the HTML code related to this element.
As is seen from the highlighted HTML line, you can easily define a parent element by its class: find-show-more-trial.
5. Determine the information elements (columns)
After you have learned how to determine the parent element, it should be easy to specify the information elements that contain the information you want to scrape (they represent columns in the resultant table).
Just do this in the same way that you did it for the parent element – by selecting it on the page and looking at the highlighted HTML code below: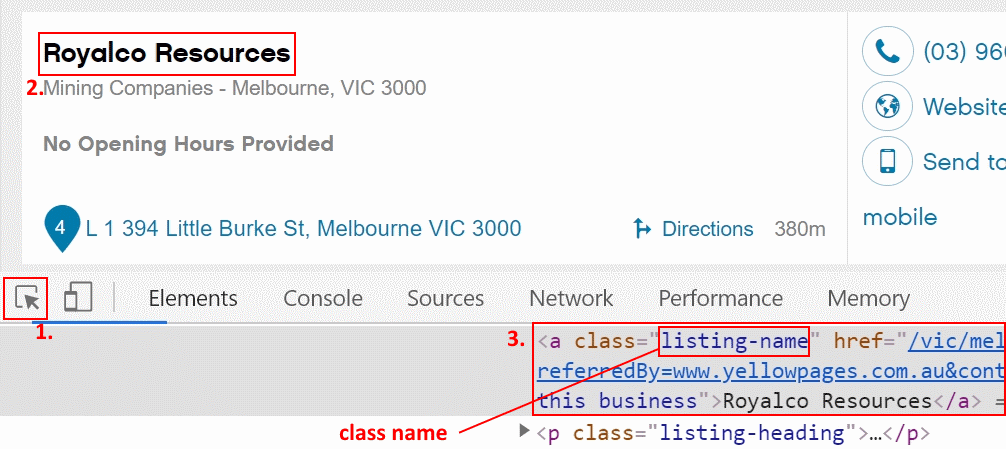 As you can see, the company name is defined by listing-name class.
As you can see, the company name is defined by listing-name class.
6. Tune the ScreenScraper itself
After all the data elements you want to scrape are found, open the ScreenScraper by clicking the small monitor icon in the top-right corner of your browser. Then do the following:
- Enter the parent element class name (find-show-more-trial in our case) into the Selector field, preceding it with a dot (*see below for why)
- Click the Add Column button
- Enter a field’s name (any) into the Field text box
- Enter the information item class (eg. listing-name) into the Selector text box, preceding it with a dot
- Repeat steps 2-4 for each information item element you want to be scraped
After you enter all these definitions you should see the preview of the scraped data at the bottom of the extension’s window: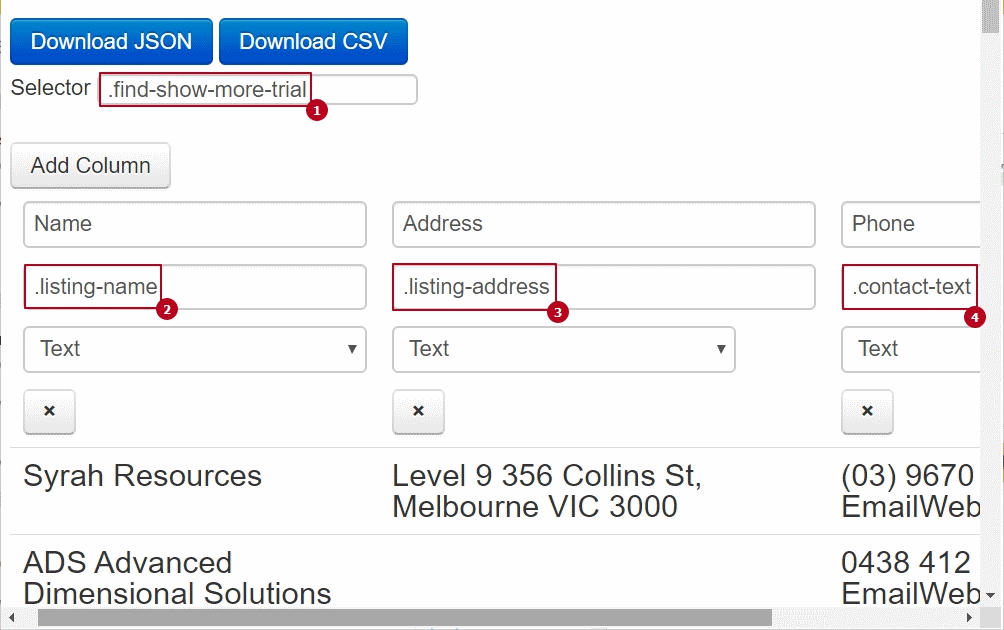 If the result is satisfactory you can download it in JSON or CSV format by pressing the corresponding button.
If the result is satisfactory you can download it in JSON or CSV format by pressing the corresponding button.
That’s it! I hope the tutorial is clear enough. But if not, feel free to write your comments below and I’ll give additional explanations.
Have a nice day!
13 replies on “How to scrape Yellow Pages with ScreenScraper Chrome Extension”
Hi, your tutorial is very helpful. However, I’m having a problem downloading the data in .csv form. Whenever I do so, the data appears empty in the Excel sheet. Any advice would be great. Thanks!
Hi Mia,
This means that the ScreenScraper can’t scrape anything with your selectors. Actually the internal structure of Yellow Pages website was changed, so you need to look for new selectors, not those I specified in this tutorial.
Thanks,
Mike
Nice tutorial.
Seems like this works using CSS selectors.
Do you know if this can scrape website URLs or not?
Thanks
Hi Stan, I’m not sure what do you mean, but you can extract all href attributes from tags with this plugin. Mike.
Watch our Excel based web scraper which can be configured for any website.
Here is a sample which I configured for YellowPages.com
https://www.youtube.com/watch?v=6HJzL4PqPRk
Write to me at Excel.Microk@gmail.com if you want to order this or for any help in Excel/word/outlook VBA.
Cheers!
Microk
xTremeExcel
http://www.extremeExcelSolutions.weebly.com
Great post! It’s been almost a year and this method still works like a charm.
If you are having trouble, keep playing with the selector parameters until you see a preview of the data that will be scrapped.
When the preview window show the correct data, download to csv.
The file output may not be recognized by your computer, open the file with Excel and format to your preference.
Hope this helps 🙂
Thanks for the great recommendation and tutorial!
I’m having a tiny problem here. I’m trying to use screenscraper on the US YellowPages, I can easily find the name and address, but for the life of me I can’t figure out how to scrape out the state or the zipcode!
All the other items seem to have a class – which I was able to use. But State and Zip code could not be scraped.
Also if you know how to scrape the website of each entry I’d appreciate it
Your help is appreciated,
Thanks!
Jake, seems to me this extention works only with elements containing classes. You might try another extention: Scraper.
I am trying to scrape a particular site where each record has multiple sub selectors. For example:
mn-listingcontent
mn-listing-main
mn-title
mn-address
mn-city
mn-listingside
mn-phone
Can I reference a nested selector? The problem is that the CSV data doesn’t import into Excel correctly. The title is on a line by itself and the rest of the data is in the same row.
Here is one record of data:
Business Name”,”Address”,”City”,”State”,”Zip”,”Phone”
Joes Body Shop LLC
“,”5145 E. Main St.”,”Penolope”,”TX”,”70027″,”(555) 555-5555″
BTW, the post eliminated the spaces before the business name and the address. Each line is indented about 12 spaces in the CSV file.
Also, it should look like this:
I didn’t realize all spaces at the beginning were stripped out. The structure of the selectors looks like this:
mn-listingcontent
—-mn-listing-main
——–mn-title
——–mn-address
——–mn-city
—-mn-listingside
——–mn-phone
The funny thing is that I would have thought mn-title would have been on the same line as the address, city and state. I would have thought that the phone would have been the one to give me problems being it was under a different child selector.
Hi,
Looks like it doesn’t work for this search:
https://www.yellowpages.com.au/search/listings?clue=Security+companies&eventType=pagination&locationClue=Australia&pageNumber=2&referredBy=www.yellowpages.com.au&refinedCategory=30740
I’m trying to get all the email addresses to excel (.csv).
Cheers,
Zoran
Zoran, this is not a simple action. Usially YP security service protects if an IP is compromized, any repetative unwanted activity is detected…