Scraper is a Google Chrome extension. Scraper is a handy scraping tool, perfect for capturing data from web pages and putting it into Google spreadsheets. This tool stands in line with the other scraping software, services and plugins.
Get Started
Let’s start with installation of this Chrome extension. You may get it here. After installation and activation, go to Londonstockexchange indexes and right-click on any link in the left index list and select ‘Scrape similar’:
Scraper Dashboard
A new window will open and you should see something similar to the one below. Scraper has two options for identifying the parts of the page you want to extract, XPath selector or JQuery selector. Those identify multiple elements (e.g., a table or a list), rather than a single HTML element. XPath provides a way to identify parts of the XML/HTML structure to extract content. To become more familiar with XPath, just visit “About XPath” or take a look at w3schools.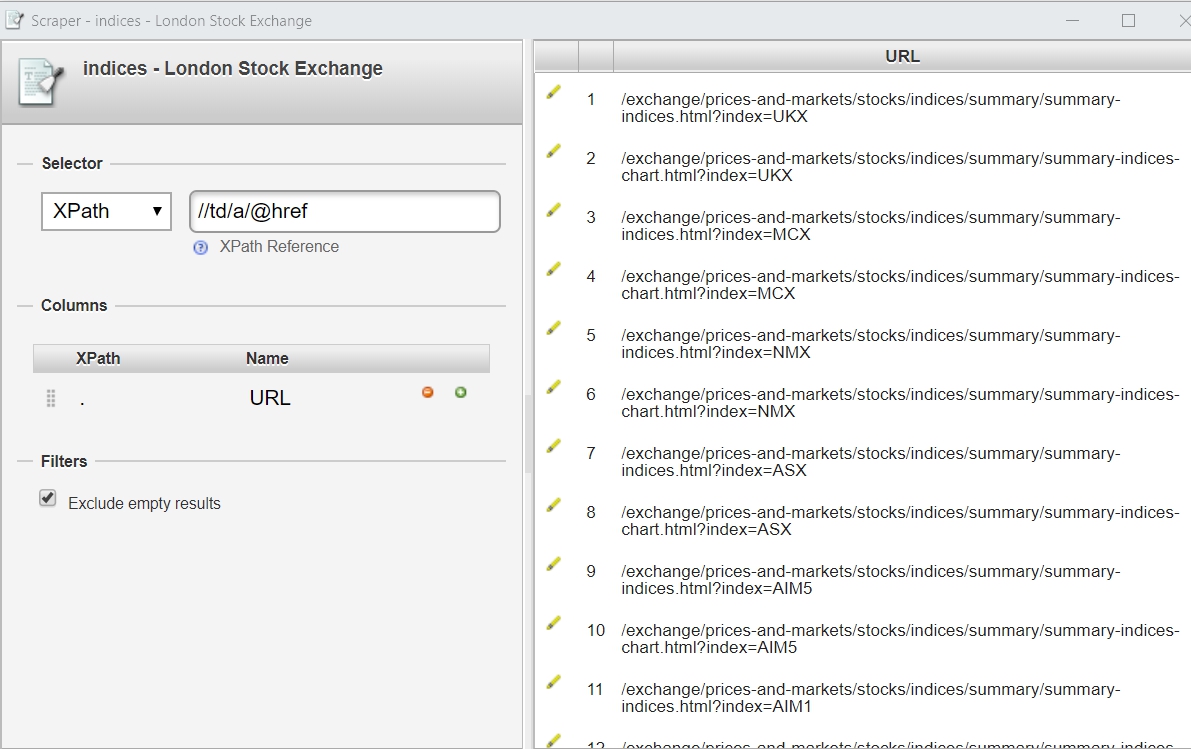 In this example, Scraper should default to //td/a/@href. Here’s a quick explanation of how to read this query:
In this example, Scraper should default to //td/a/@href. Here’s a quick explanation of how to read this query:
- Since it starts with // it will select “nodes in the document from the current node that match the selection no matter where they are”. For me, this is a trigger to read the query from right to left as we are matching an endpoint pattern.
- “@href” refers to the attribute whose name is href; that is the URL we need.
- “a” refers to the <a> node.
- “td” refers to <td> within the structure.
You may edit the XPath expression, whether at Selector or at Columns area, as well as change the column names. Click “Scrape” and the Scraper will reload with improved results. In the picture above, I added /@href to get only URLs rather than Link names too.
Refining & Editing Results
As you notice, the URLs we got from the web are just suffixes with a base URL missing. So now, I’ll concatenate using the in-built Google Docs function: CONCATE(string1, string2). Get the base manually online at http://www.londonstockexchange.com. Type in the adjacent cell =CONCAT(“base url”, A2) and press enter. Don’t forget: the strings are to be always quoted when in functions, indexes not: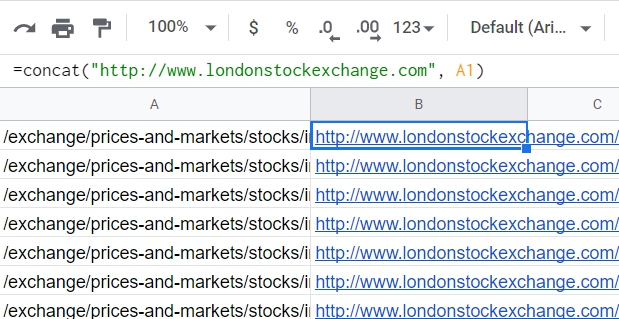
Now, select cell B2 and fill the column down to get full URLs for all the links. That’s it.
How to select and auto-fill: put the cursor into the bottom-right corner of a cell, turning its image into a thin cross, press it and pull it down to auto-fill.
Other Points to Mention
When you want to scrape tabled structures, select an area and again right-click “Scrape similar”: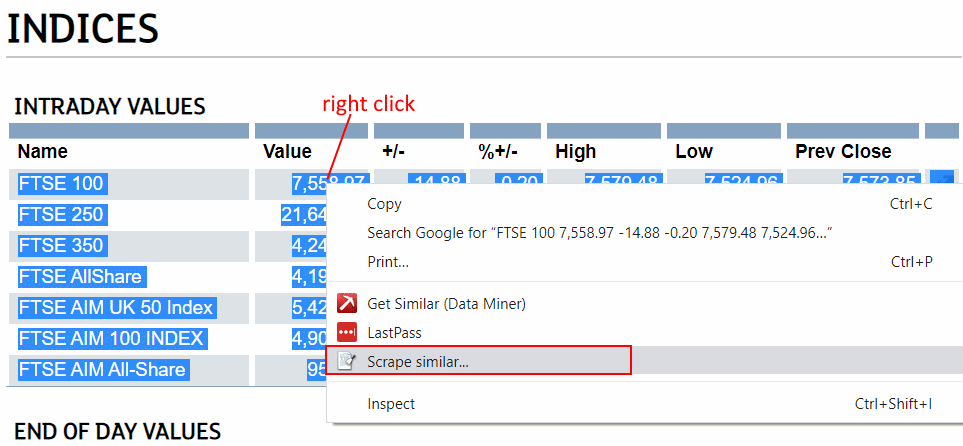
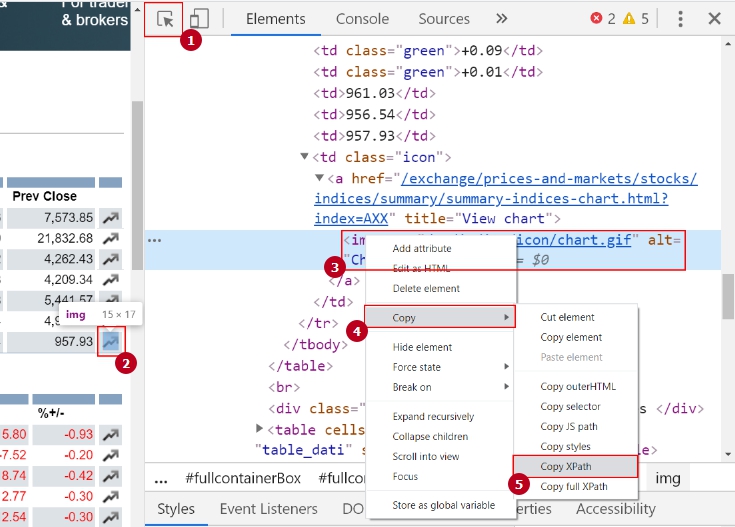
This Scraper doesn’t identify images, unless you specify a link to image inside the HTML element using an additional Xpath selector, as in the picture below: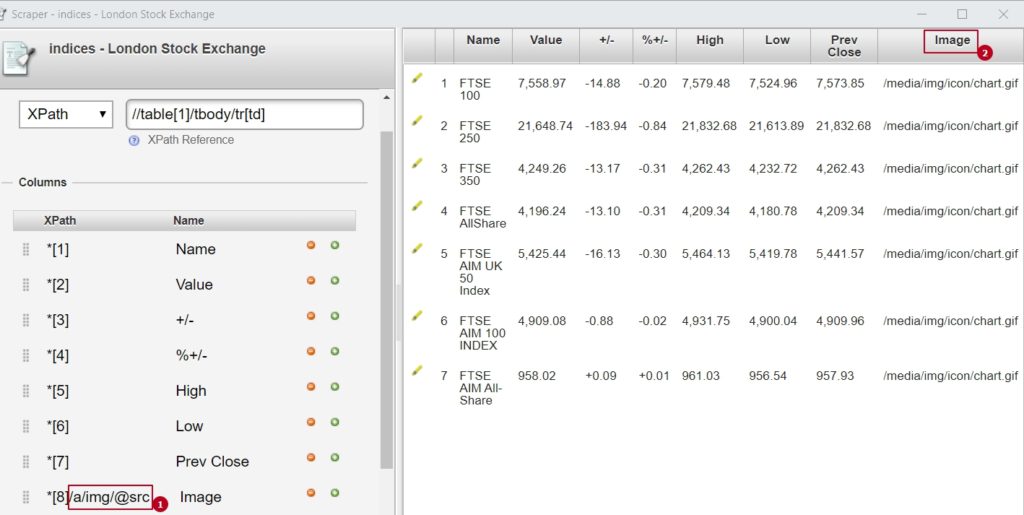
How to Get an Additional XPath Selector to Image Link
- Enable Google Chrome developers tool by F12 or Ctrl+Shift+I.
- In the tab that appears, pick the loupe to point (& click) at the element, and then right-click at the highlighted element in the tab and select Copy XPath!
- I cut the last part of XPath expression to be an additional selector, the last part being ‘/img’ and I added ‘@scr’ to select the very ‘scr’ attribute value.
 No sorcery, just try it!
No sorcery, just try it!