Here we come to one new milestone: the JavaScript-driven or JS-rendered websites scrape.
Recently a friend of mine got stumped as he was trying to get content of a website using PHP simplehtmldom library. He was failing to do it and finally found out the site was being saturated with JavaScript code. The anti-scrape JavaScript insertions do a tricky check to see if the page is requested and processed by a real browser and only if that is true, will it render the rest of page’s HTML code.
How to find out if site is JS stuffed?
When you approach a target page you won’t necessarily be able to tell whether or not it is JS-scrape-proof locked. It might take you some time and a few unsuccessful trials, before you begin to suspect something is wrong; especially since there’s no essential output at scraper’s end. So, prior to starting web scraping it’s wise to use a web sniffer (also called network analyzer) to watch the network activity in the target site’s page load.
Nowadays, every decent browser has built-in developer tool that includes a web sniffer. In this example I used Chrome ext. web sniffer. In the following picture you can see the multiple JS scripts vs only one mainframe load (in red box by me) on every page load (taken by Google ext. sniffer).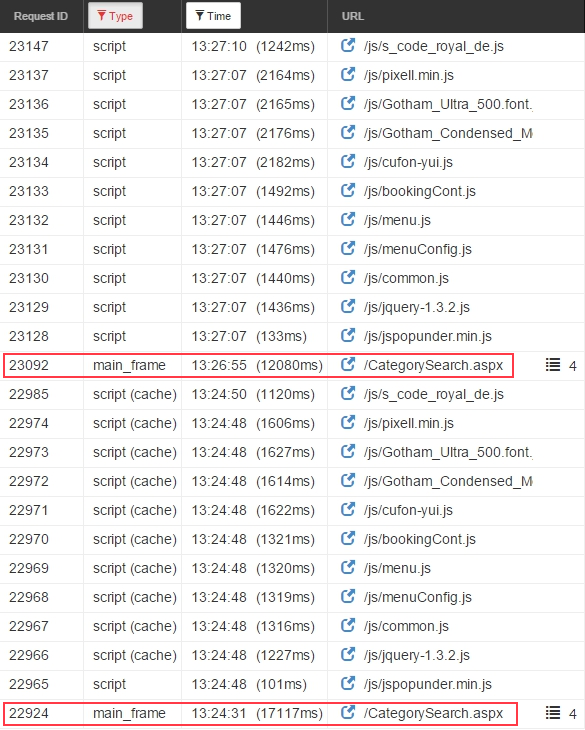
JS-protected content scrape
JS protection logic
First of all, let’s consider what JS logic is using to prevent scraping.
When your browser requests the HTML content, the JS code should arrive first (or at least simultaneously). This code calculates a value which it returns to the target server. Based on this calculation, the HTML code might be not restored from obfuscating or might not even be sent to the requester, thus leaving scraping efforts thwarted.
The ways to break thru anti-scrape JS logic
Simulate real browser for scrape. The most used tools for that are Selenium and iMacros. There is a recently emerged web IDE called WebRobots that drives Chrome browser thru JaveScript robots. Read how to leverage Selenium with headless FF browser.
Use JS plugins to execute JS logic and return needed value to the target server to unlock content for scrape. I found v8js PHP plugin and its Python analog PyV8.
Use the specific libraries (toolkits) as add-ons for the scripting languages. Below is an example of using a library with python in web scraping. One example of such a library is Splash.
Example use of dryscrape library
I wanna show you the code example of how to leverage dryscrape library to evaluate scraped JS for JavaScript protected content.
Python code with only requests library
Since the requests library does not do JS evaluation support, it fails to return the JS protected content.
Scrape without JS support:
import requests
from bs4 import BeautifulSoup
url='www.google.com'
response = requests.get(url)
soup = BeautifulSoup(response.text)
soup.find('a')Scraping code with JS support thru dryscrape library
Scrape with JS support
import dryscrape
from bs4 import BeautifulSoup
sess = dryscrape.Session()
sess.visit(url)
response = sess.body()
soup = BeautifulSoup(response)
soup.find('a')The difference is essential as the library does much to fetch and evaluate JS and provide an access to the desired HTML.
If you know a better way to fight JS prevention methods let me know in the comments.
More
See some other examples of scraping JS-rendered content: 1
11 replies on “Scraping JavaScript protected content”
What was the site he was trying to scrape? If you don’t want to share it here, send me an email.
The site is http://www.royalcaribbean.de
What was the site he was trying to scrape? If you don’t want to share it here, send me an email.
The site is http://www.royalcaribbean.de
The better tool for scraping is:
http://casperjs.org/.
Useful post
Hi – it seems QTWebKit is no longer available (replaced by the QTWebEngine project it seems). So DryScrape is no longer a viable solution??
Hi – it seems QTWebKit is no longer available (replaced by the QTWebEngine project it seems). So DryScrape is no longer a viable solution??
What if we use the PhantomJS, Isn’t it good enough than using Selenium
What if we use the PhantomJS, Isn’t it good enough than using Selenium
But Thanks for improving my Knowledge Regarding this Stuff 🙂