Can you imagine how many scraping instruments are at our service? Though it has a long history, scraping has at last become a multi-lingual and simple approach. Unfortunately, there is a list of non-trivial tasks which can’t be resolved in a snap.
![]() One of these tasks is scraping javascript sites, those that output data using JavaScript. Facing this task, classic scrapers (not all of them though) ignore JS-data and continue their own life-cycle. However, when this little defect becomes a big trouble, developers all over the world take measures. And they did it! Today we consider one of the most awesome tools which scrapes JS-generated data – Splash.
One of these tasks is scraping javascript sites, those that output data using JavaScript. Facing this task, classic scrapers (not all of them though) ignore JS-data and continue their own life-cycle. However, when this little defect becomes a big trouble, developers all over the world take measures. And they did it! Today we consider one of the most awesome tools which scrapes JS-generated data – Splash.
The elegant scraping of JS-generated data – Splash
Installing Docker
Trying examples from this article is not possible without Docker. The installing process has some pitfalls, so here will be described the right way to install Docker on Windows and Mac OS.
Windows
The best way to install Docker on Windows is to install Docker Toolbox. The installation process is simple “next->next” installation. It contains the Docker Quickstart program (you will run it to launch Docker), Oracle VM Virtual box (help-tool to run Docker) and Kitematic (also a help-tool, but you won’t use it). After launching Docker Quickstart you will be ready to work!
Mac OS
Mac users should download Docker here. After that, the simple installation cycle starts:
- Open dmg to start installation
- Drag the app to your application folder
- Open app. You should authorize with your system password on this step
- If everything is done successfully, you will see the whale in the top status bar. Also, the message with greetings will be shown. Run docker info command to check basic information about your Docker
Quick start
Splash is JavaScript rendering library with HTTP API that was implemented in Python, but it cannot be used alone – only in tandem with Scrapy, which provides the main functionality for scraping web-pages.
There are two main ways to start using Splash immediately
Docker
- docker run –p 8050:8050 scrapinghub/splash
- Visit the address http://127.0.0.1:8050 . If you have install Docker Toolbox, try 192.168.99.100:8050 address
There you should see something like: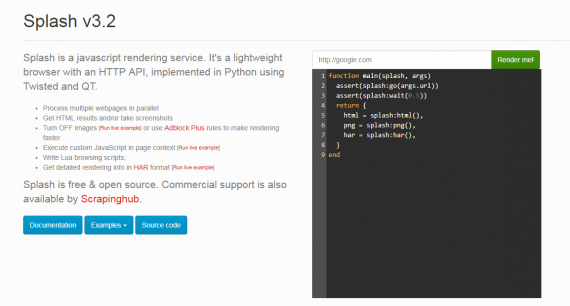
DataFlowkit offering Splash
Eager to test it, but Docker is not installed? Simply visit http://dataflowkit.org:8050/ to play around with Splash (however, this access to Splash only works temporary – so you will have to authorize soon to be able to visit it). The using language is called Lua. It’s ok if you don’t know anything about it – you can use built-in examples or study Lua in 15 minutes.
How it works
Here we will create a simple scraping project that will scrape JS-generated data. As an example, the site http://quotes.toscrape.com/ is used. The data is organized in tags, and there is nothing difficult at all about scraping it.
To begin our Scrapy-Splash trip, we need to install Scrapy. To make this process comfortable, it’s recommended that you install conda. After that, simply print your command line:
conda install -c conda-forge scrapyAlternatively, you can use pip
pip install ScrapyBut for beginners in Python we strongly recommend using the first approach.
After successful installation we can create our first scraping spider:
scrapy genspider quotes toscrape.comThis command will create a quotes.py file with basic functionality, where quotes is a name of the file (quotes.py) and toscrape.com is the site to be scraped. Using toscrape.com as a domain name allows us to work with its subdomains (quotes.toscrape.com, quotes.toscrape.com/js/).
If everything is all right, your code should look like the following:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['toscrape.com']
start_urls = ['http://toscrape.com/']
def parse(self, response):
passLet’s try to scrape the site http://quotes.toscrape.com. As it’s a sub domain of toscrape.com we are able to work with the quotes site.
The first thing we need to do is to analyze the site. For example, we simply want to get all quotes with their authors and tags. Press F12 to see where the needed information is situated. In Chrome it looks like the following: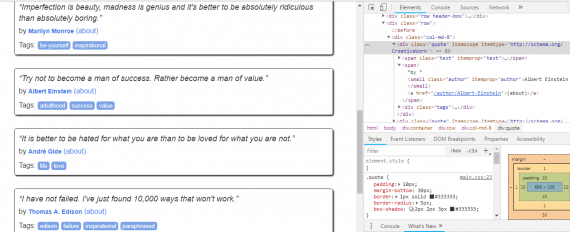
Pointing to the code you can see where its graphical result is situated. Using this simple method we can see that authors’ names are located in <small class = “author”>, text is located in <span class = “text”> and tags are hiding in <a class = “tag”>. In general, we have everything to start scraping.
The scraping class for http://quotes.toscrape.com site is below:
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
for quote in response.css('div.quote'):
item = { 'author_name': quote.css('small.author::text').extract_first(),
'text': quote.css('span.text::text').extract_first(),
'tags': quote.css('a.tag::text').extract(),
}
yield itemIn order to create understandable output, we will put the results in quotes.json file. To launch the scraper and create json-file with output we will use:
scrapy runspider quotes.py –o quotes.jsonThe results will be displayed in json format
[
{"author_name": "Albert Einstein", "text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d", "tags": ["change", "deep-thoughts", "thinking", "world"]},
{"author_name": "J.K. Rowling", "text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d", "tags": ["abilities", "choices"]},
...
{"author_name": "Steve Martin", "text": "\u201cA day without sunshine is like, you know, night.\u201d", "tags": ["humor", "obvious", "simile"]}
](docs)
Scrape JS-generated data
Everything is perfect. In the example above we simply get data from the source HTML code, but what should we do if we need to scrape JS-generated data? Let’s look at the site, similar to the above-mentioned one http://quotes.toscrape.com/js/ . At first glance, everything looks like in the previous example. So, let’s try to scrape it – change the value of variable start_urls to http://quotes.toscrape.com/js/. Run the command once more… And we can’t see any data! Strange, isn’t it? Let’s take a look at its source code. For that press Ctrl + U and see the following code (inside of page’s html) in a new tab:
for (var i in data) {
var d = data[i];
var tags = $.map(d['tags'], function(t) {
return "<a class='tag'>" + t + "</a>";
}).join(" ");
document.write("<div class='quote'><span class='text'>" + d['text'] + "</span><span>by <small class='author'>" + d['author']['name'] + "</small></span><div class='tags'>Tags: " + tags + "</div></div>");
}In the end of the script you can see a cycle that generates HTML-code by JavaScript. Scrapy can’t resolve this trouble solo. Fortunately, Splash is our rescue ranger!
First, we should set up Splash by Docker
docker pull scrapinghub/splashThen, run Splash
docker run –p 8050:8050 scrapinghub/splashNow we need to install the Splash by pip
pip install scrapy-splashGood, now we have everything to solve dynamically-generated-data problem. The code for scraping JS-generated data is below:
import scrapy
from scrapy_splash import SplashRequest
class QuotesSpider(scrapy.Spider):
name = 'quotes'
custom_settings = {
'SPLASH_URL': 'http://localhost:8050',
# if installed Docker Toolbox:
# 'SPLASH_URL': 'http://192.168.99.100:8050',
'DOWNLOADER_MIDDLEWARES': {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
},
'SPIDER_MIDDLEWARES': {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
},
'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter',
}
def start_requests(self):
yield SplashRequest(
url='http://quotes.toscrape.com/js',
callback=self.parse,
)
def parse(self, response):
for quote in response.css("div.quote"):
yield {
'text': quote.css("span.text::text").extract_first(),
'author': quote.css("small.author::text").extract_first(),
'tags': quote.css("div.tags > a.tag::text").extract(),
}In custom_settings we should add middleware, which is needed for scraping with Splash. All in all, the code is easy enough.
Try to launch the quotes.py file now. Results will be displayed in logs or in .json file, if you use it for saving code output.
What can we say about Splash after some practice?
- Easy in use
- Capable of using Python or Lua
- Open-source project
Today, Splash is on its way to gaining huge popularity, and this is great – the Scrapy ecosystem should become popular!
Scrapy and its awesome features
Instead of an ordinary conclusion, we want to introduce the cool Scrapy feature that will motivate you to study this tool more deeply. The feature is scraping infinite scrolling pages, which allows you to get information from long-page websites.
As usual, we will practice on the quotes site. Visit this url and press F12, open the network tab and start to scroll the page. What’s going on in the developer console?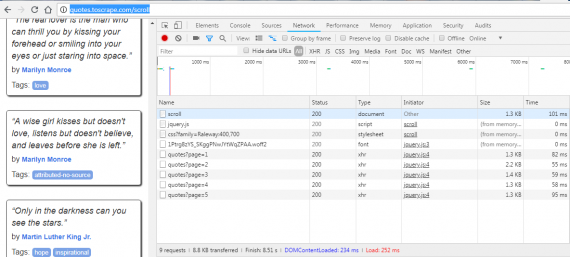
The new events are appearing while the page gets scrolled down. New quotes are loaded thru AJAX (XMLHttpRequest) requests. All we need is to retrieve them. The simple code below will help us to get all quotes from such a long page of quotes.
import json
import scrapy
class QuotesInfiniteScrollSpider(scrapy.Spider):
name = "quotes-infinite-scroll"
api_url = 'http://quotes.toscrape.com/api/quotes?page={}'
start_urls = [api_url.format(1)]
def parse(self, response):
data = json.loads(response.text)
for quote in data['quotes']:
yield {
'author_name': quote['author']['name'],
'text': quote['text'],
'tags': quote['tags'],
}
if data['has_next']:
next_page = data['page'] + 1
yield scrapy.Request(url=self.api_url.format(next_page), callback=self.parse)Nothing complex at all, thanks to such a convenient instrument as Scrapy and Python, of course. Hope, this article will be a first step in your scraping adventure with Scrapy.
3 replies on “JavaScript rendering library for scraping javascript sites”
There’s now a scalable web crawling and scraping library for JavaScript.
https://sdk.apify.com/
https://github.com/apifytech/apify-js
Let us know what you think.
Happy crawling!
Nicolas, would be interesting to make a post of the library for the webscraping.pro.
Now the post is live: Using Modern Tools such as Node.js, Puppeteer, Apify for Web Scraping (Xing scrape)
Hello Igor,
I am trying to scrap the page “https://tienda.mercadona.es/categories/112” and I have installed the docker and follow all the required steps. Splash works well, but the spyder does not and I don’t know why. The ip is correct but I can’t see in the response object the complete page.
If you could help me I would be very gratefull.