In the evolving world of data and data-driven economies, modern data gathering tools and services are crucial. So, in this post we’ll review Sequentum Cloud, the cloud-based web data scraping suite enabling non-tech users to gather custom web data. Sequentum Cloud is great for both for gathering business intelligence, such as monitoring competitors to drive data driven decision making or powering content-driven AI applications.
Sequentum Vision
Sequentum’s users include data engineers, research analysts, compliance and governance managers who can get started immediately and leverage best-in-class technology to get the most precise data to meet their needs.
In the post we want to introduce you to the most important and outstanding features that Sequentum Cloud possesses.
Below we Outline the post’s major points:
Features
Proxying
Sequentum Cloud Plans for future
Usage/cost
Agents
Online Editor specials
- Idle Time (Incorrect heading level)
- Automated browser scrape
- “Pass through” or “Ignore” when action fails or element missing
- Xpath changes
- User-agent rotation
- Load all dynamic content
- Rotating Browser Profiles
- Runtime data retention
Tracking Changes
Runs – cloud executions
Data validation
Recap
Features
Let’s bring in some key Sequentum Cloud features.
Dynamic Data Handling
Extract data seamlessly from websites using AJAX, JavaScript, forms and more… Simulate human-like browsing behavior to enhance scraping accuracy.Multiple Output Formats
Export data in CSV, Excel, JSON, or directly to databases like SQL Server and Snowflake.Error Handling
Advanced error-handling mechanisms for dealing with web crashes, CAPTCHA, and server downtime. Dealing with modern scraping challenges using built-in tools that handle form submissions, dynamic content loading and CAPTCHA bypassing.Scheduling
Schedule extraction tasks to run automatically, ensuring up-to-date data collection.Scalability
Massively Scalable [concurrent] requests scale up effortlessly to handle high volumes of data extraction without compromising performance.View some scraping challenges addressed by Sequentum Cloud
| Cloud-based | Access and manage data extraction remotely, with automatic scaling to meet your needs. |
|---|---|
| Dynamic Website Handling | Extract data from websites using AJAX, JavaScript, and forms seamlessly. |
| Multiple Output Formats | Export data in CSV, Excel, JSON, or directly to databases like SQL Server and Snowflake. |
| Error Handling | Advanced error-handling mechanisms for dealing with web crashes, CAPTCHA, and server downtime. |
| Scheduling | Schedule extraction tasks to run automatically, ensuring up-to-date data collection. |
Proxying related features
- Residential proxies – $5-7 / GB
- Data center proxies – free
- Bypass anti-bot due to a variety of vast proxies pools, user-agents, generative fingerprinting and more
- API (this was recently released and will be reviewed in a later post)
- A Slick and nice User interface
- Custom functions
- Custom Regular expressions
- Documentation
- Integrated ticketing system
Usage/cost
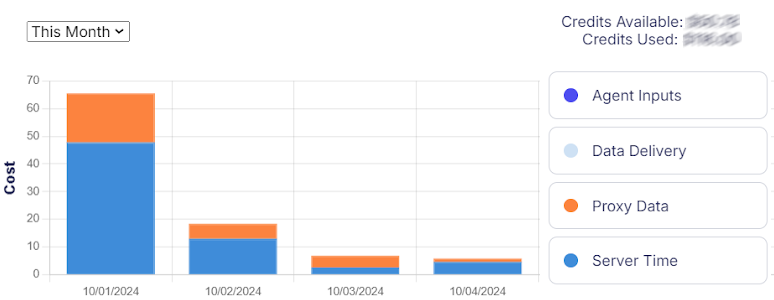
The cost of cloud agents being run is summed of 4 aspects, 2 being the main ones: Server time and Proxy usage.
Agents
Within an Agent one manages crucial aspects such as Input parameters, Proxies, Success criteria, Basic authentication, files and more. Read more on Agent Command.
- Transferable
One can copy a text representation of a scraping agent and save it for later export. See an example of an agent:
One may see an agent as a set of commands, with Xpath extractions, pagination, Regex transformations and more. - Runs
The agent runs are convienient. See the log:11:37:10.042 [INF] Starting log with log level WARNING.
11:37:10.063 [INF] Starting agent
11:37:10.113 [WRN] Proxy override is Sequentum Data Center.11:37:13.482 [INF] End of log.
As we see from the log, the agent ran 3.4 seconds. It had no errors, having hit all the pagination and collecting corresponding data.
HTTP requests or Dynamic Browser for scrape
The speed was that fast since we applied a Static browser that is a lightweight browser rather than a Dynamic, full-scale, browser. See figure below: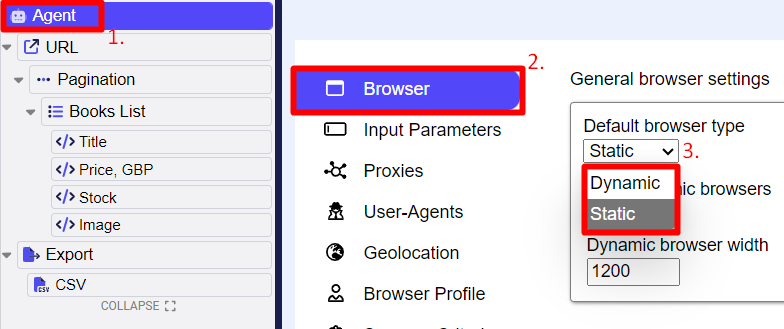
- Export
Besides exporting into multiple destinations (CSV, JSON, S3, Google Sheet, Google Drive, FTP, Snowflake, Export Scripts), the Export setup allows users to define a CSV field delimiter/separator, see figure below: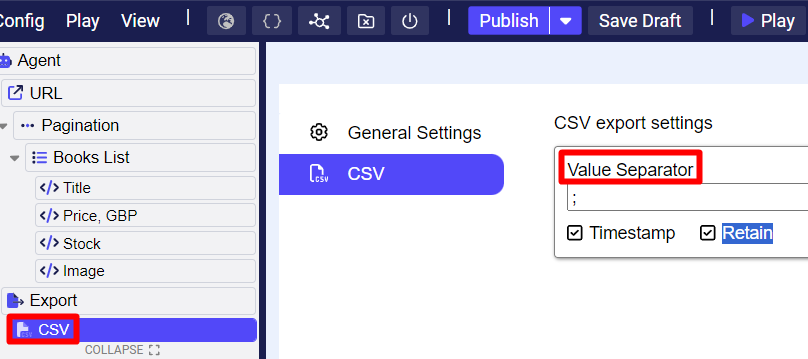
Initially I had some issues with exporting into Google Sheets, but the Sequentum Cloud Support team was able to easily walk me through it.
The export into Google Driver went seamless. See image below:
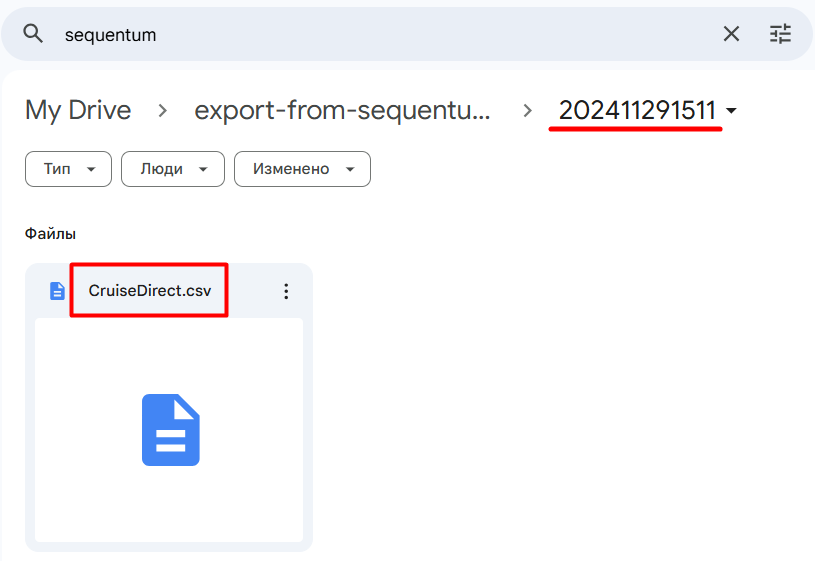
Online Editor specials
1. Idle Time
To optimize server load balancing, there is a 5-minute inactivity threshold for the Agent Editor. While someone’s progress is saved in drafts, active sessions will expire. To continue your work, simply return to the Control Center:
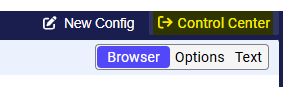
2. Automated browser scrape
For every Agent one may set Dynamic Browser for scrape. See how to set it up.
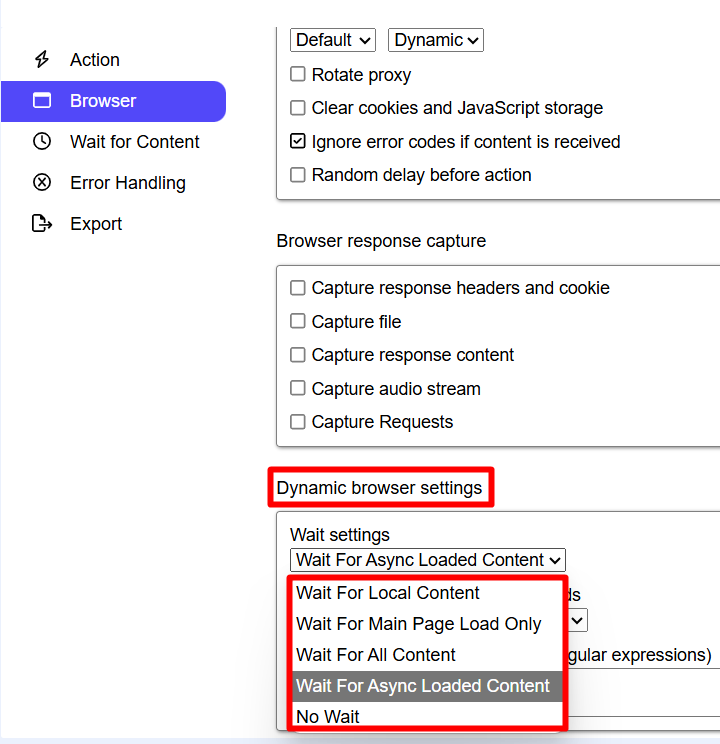
The browsers are run in headless mode. Read more on Dynamic browser setttings.
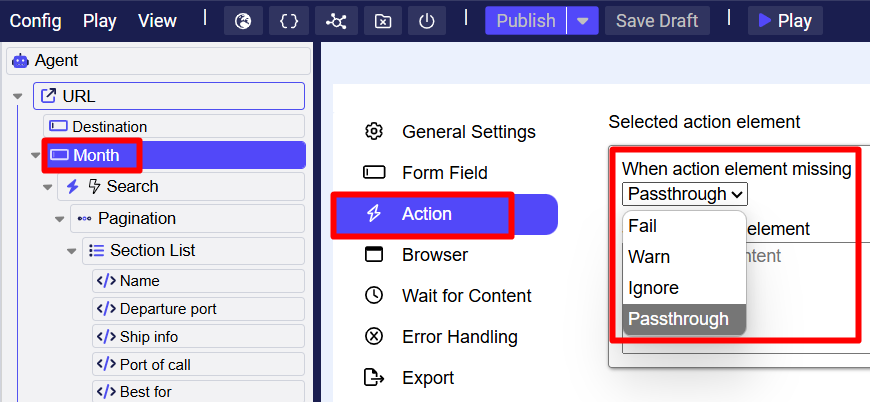
3. “Pass through” or “Ignore” when action fails or element missing
4. Xpath changes
During one of agent UI interactive building a selector XPath notation turned out to to be huge and complicated. This caused a failure in the element finding at a testing phase.
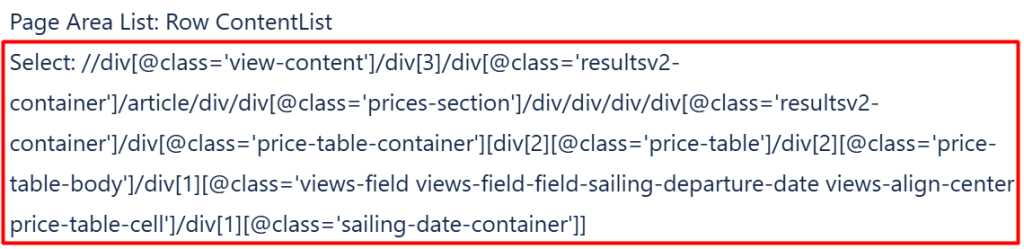
After addressing this issue to the support I received extensive help, providing a short & operative XPath. As a non-programmer may puzzle himself with XPath issue so I’ve double checked with support and they replied to me. Q&A on Agent XPaths:
Q. (me): should I replace [selector] XPath most of the times for seamless work ?
A. (support): There’s no need to replace the XPath repeatedly in a selector. You only need to update it if the webpage structure changes, like class names or tags. If the structure remains the same, the provided XPaths will work perfectly without any changes. Just use optimized XPaths for reliable and efficient performance.
5. User-agent rotation
Besides regular User-Agent rotation the Sequentum Cloud offers Associate With Proxy Address. That is, it synchronizes User-Agent rotation with proxy changes. 6. Load all dynamic content
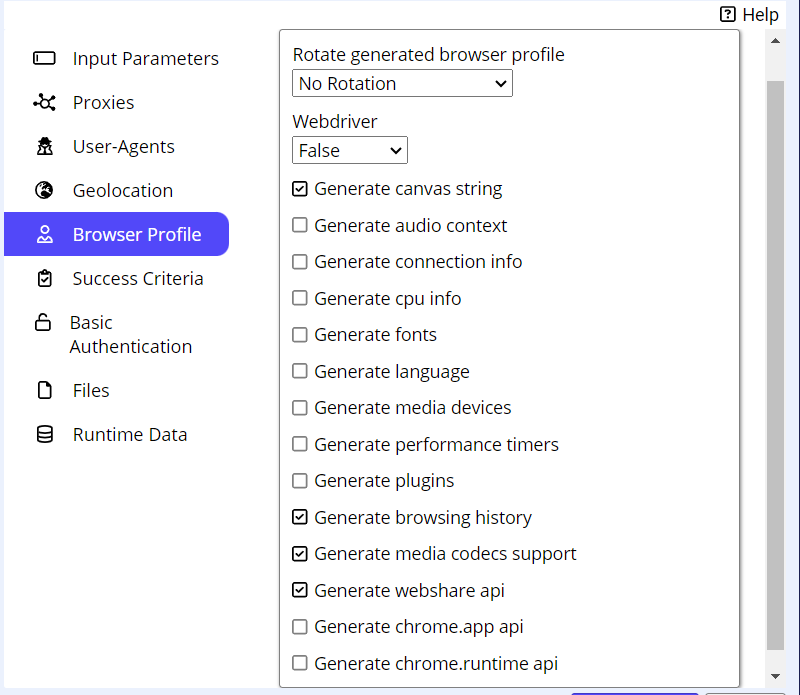
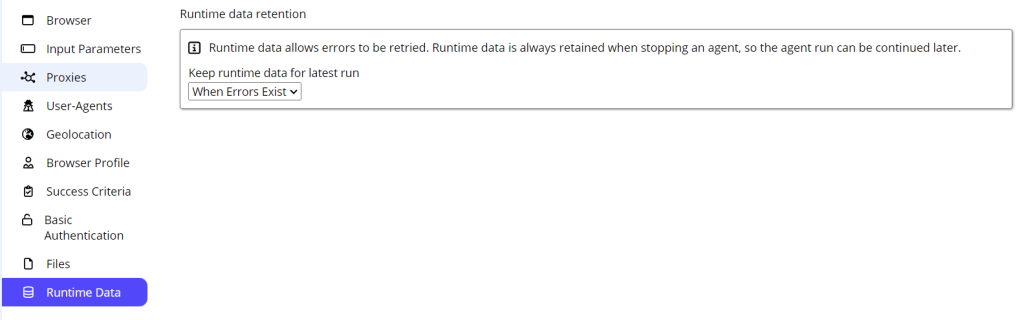
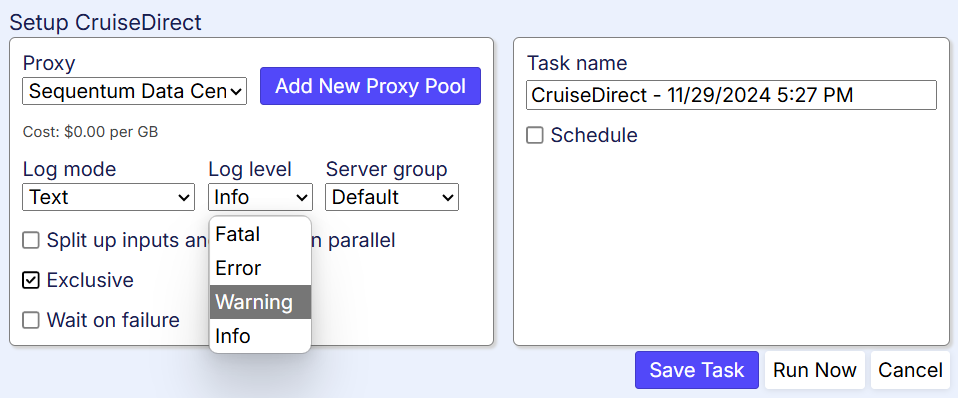
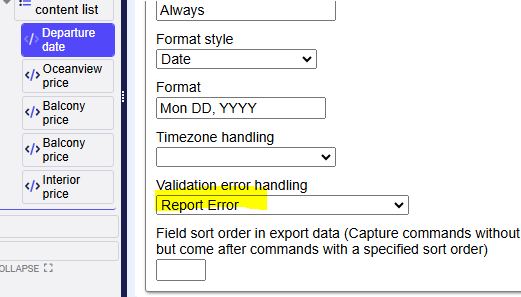
The Parse All Content button forces agent to reload and reprocess all the frames and elements on a page, ensuring that the entire content is properly captured. Note the Parse All Content functionality is applicable to the Agent Editing mode. If one wants the agent to handle dynamic content at run-time, please refer to point 2 with “Dynamic content settings” above. Read more here. Sequentum Cloud makes effective Browser profiles with configurable options (various parameters that affect how the browser functions) and rotating possibilities. Read more on Browser profile settings. Runtime data might be retained for later agent re-run. This ensures that data remain available when stopping an agent, enabling the run to be continued later. Agents might be configured to track (and Export) only changes that occurred since the last successful run or only export data that has changed since a specified number of days. This option pertains to the Export command. Read more here. Each run is an execution of an agent under certain conditions. Following are the run setup conditions: The run setup might also become a task scheduled. See details below: See some runtime execution details: Data validation is normally performed in the agent Schema. The given schema makes an agent to check scraped data thus excluding result. I’ve set up Schema in the Export attribute. 755 It’s kind of useful to validate data at run time. Suppose we want to find Departure dates matching exactly MMM dd, YYYY (Dec 28, 2024). We set it at Export → Schema → Departure date → MMM dd, YYYY as Format value. Now as a scraper checks validity of specified field at a run-time we may set up what to do if scraped data is invalid: Sequentum Cloud is an end-to-end data pipeline platform that delivers the most reliable custom web data, all fully observable and auditable for analysis and informed decision-making. It includes all the features needed for a data operation that can be used by savvy specialists as well as by non-tech persons thanks to their point-and-click interface. Click here for more information on Sequentum Cloud or here to go directly to their sign-up page for a Free Trial. Read more on the Sequentum Cloud bypassing strict scrape blocking 7. Rotating Browser Profiles
8. Runtime data retention
Tracking Changes
![]()
Runs – Cloud Executions
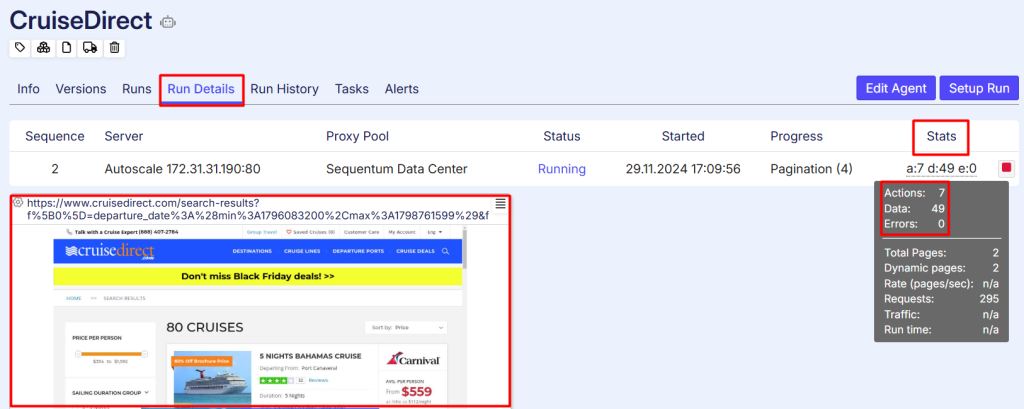
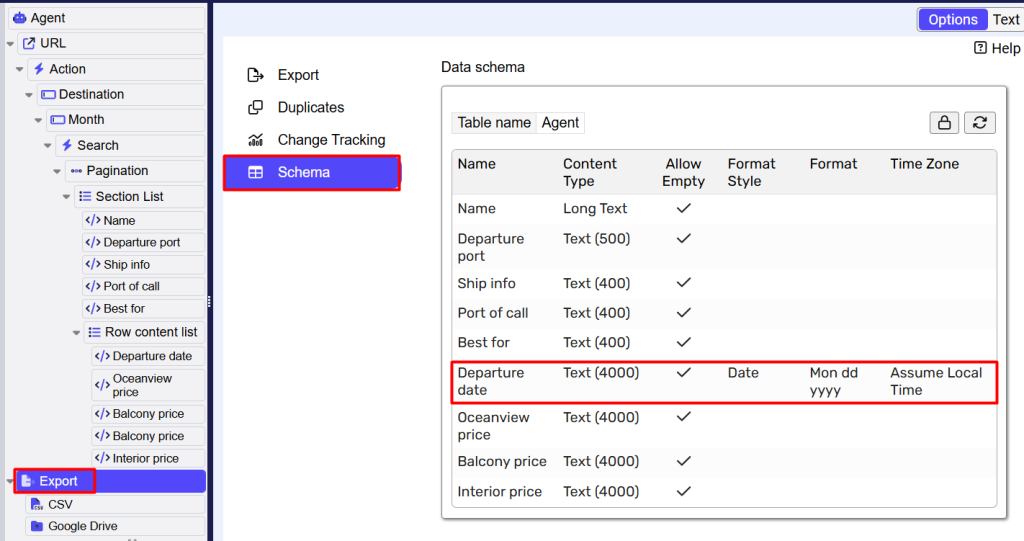
Data validation
Now as I play an agent the log shows:Executing Capture command Departure date756 Command "Departure date" extracted text that doesn't match the specified date format Mon dd yyyy. Captured value is Dec 28, 2026
The formats supported by Sequentum Cloud on the Custom date & time format.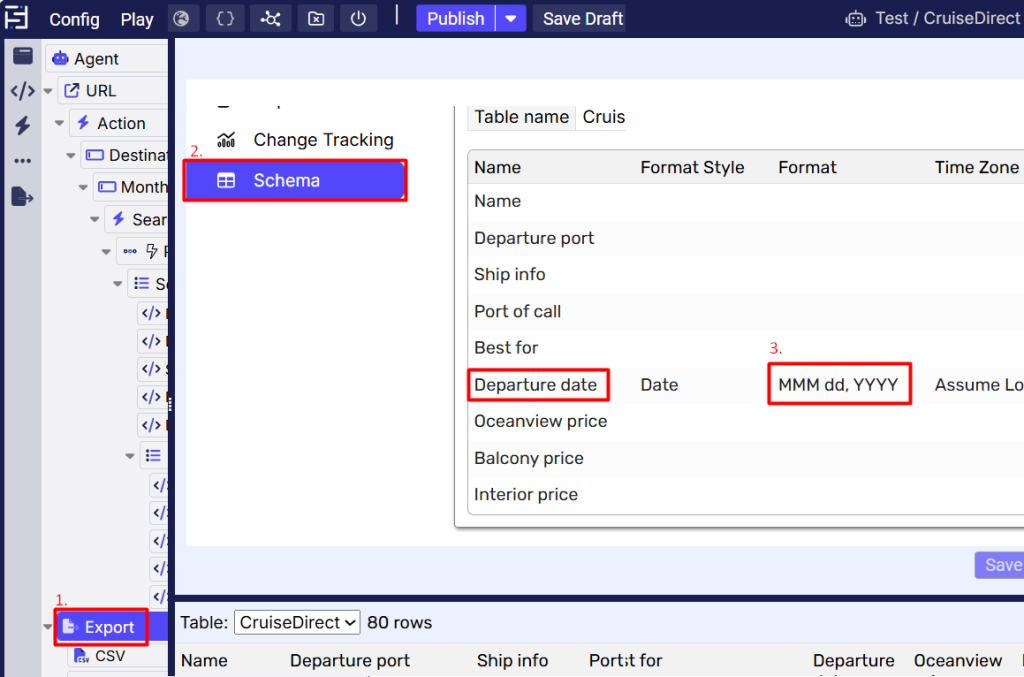
Recap