 Web scraping or crawling is the act of fetching data from a third party website by downloading and parsing the HTML code to extract the data you want. It can be done manually, but generally this term refers to the automated process of downloading the HTML content of a page, parsing/extracting the data, and saving it into a database for further analysis or use.
Web scraping or crawling is the act of fetching data from a third party website by downloading and parsing the HTML code to extract the data you want. It can be done manually, but generally this term refers to the automated process of downloading the HTML content of a page, parsing/extracting the data, and saving it into a database for further analysis or use.
Java Web Scraping Handbook
This blog post is an excerpt from a new book Java Web Scraping Handbook. The book will help you master some of the web scraping skills: from parsing HTML to breaking captchas, handling JavaScript heavy websites and many more. Pre-order now for a special discount! [/box]
Web Scraping vs APIs
When a website wants to expose data to the developer community, they will generally build an API (Application Programming Interface). The API consists of a set of HTTP requests, and generally responds with JSON or XML format. We could imagine that an E-commerce website has an API that lists every product through this endpoint:
curl https://api.e-commerce.com/products
It could also expose a product detail (with “123” as id) through:
curl https://api.e-commerce.com/products/123
Since not every website offers a clean API, or an API at all, web scraping can be the only solution when it comes to extracting website
information. APIs are generally easier to use, but the problem is that lots of websites donʼt offer any API.
Building an API can be a huge cost for companies; you have to ship it, test it, handle versioning, create the documentation; there are infrastructure costs, engineering costs, etc. The second issue with APIs is that sometimes there are rate limits (you are only allowed to call a certain endpoint X times per day/hour), and the third issue is that the data can be incomplete.
The good news is: almost everything that you can see in your browser can be scraped.
Let’s scrape Hacker News
As an example, we are going to collect items from Hacker News. Although they offer a nice API, let’s pretend they don’t.
Tools
You will need Java 8 with HtmlUnit, and Maven. HtmlUnit is a Java headless browser; it is this library that will allow you to perform HTTP requests on websites, and parse the HTML content.
Add this to your pom.xml
<dependency> <groupId>net.sourceforge.htmlunit</groupId> <artifactId>htmlunit</artifactId> <version>2.28</version> </dependency>
If you are using Eclipse, I suggest you configure the max length in the detail pane (when you click in the variables tab), so that you will see the entire HTML of your current page:
The goal here is to collect the titles, number of upvotes, number of comments on the first page. We will see how to handle pagination later.
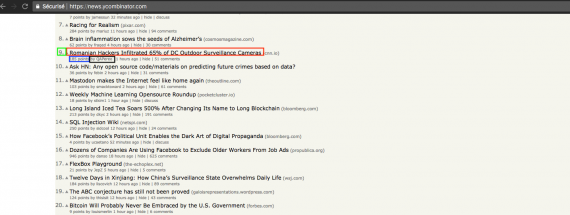
The base URL is:
https://news.ycombinator.com/
Now you can open your favorite IDE, and it is time to code. HtmlUnit needs a WebClient to make a request. There are many options (Proxy settings, browser, redirect enabled…). We are going to disable Javascript since it’s not required for our example, and disabling Javascript makes the page load faster in general (in this specific case, it does not matter). Then we perform a GET request to the Hacker News’s URL, and print the HTML content we received from the server.
String baseUrl = "https://news.ycombinator.com/" ;
WebClient client = new WebClient();
client.getOptions().setCssEnabled(false);
client.getOptions().setJavaScriptEnabled(false);
try{
HtmlPage page = client.getPage(baseUrl);
System.out.println(page.asXml());
catch(Exception e){
e.printStackTrace();
}
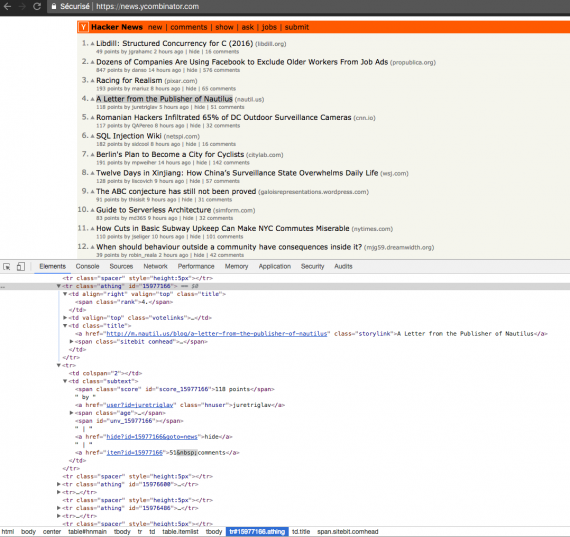
The HtmlPage object will contain the HTML code; you can access it with the asXml() method. Now for each item, we are going to extract the title, URL, author, etc. First let’s take a look at what happens when you inspect a Hacker News post (right click on the element + inspect on Chrome)
With HtmlUnit you have several options to select an html tag:
- getHtmlElementById(String id)
- getFirstByXPath(String Xpath)
- getByXPath(String XPath) which returns a List
- Many more can be found in the HtmlUnit Documentation
Since there isn’t any ID we could use, we have to use an Xpath expression to select the tags we want. We can see that for each item, we have two lines of text. In the first line, there is the position, the title, the URL and the ID. And in the second, the score, author and comments. In the DOM structure, each text line is inside a <tr> tag, so the first thing we need to do is get the full <tr class=”athing”> list. Then we will iterate through this list, and for each item select title, the URL, author, etc. with a relative Xpath and then print the text content or value.
HackerNewsScraper.java
HtmlPage page = client.getPage(baseUrl);
List<HtmlElement> itemList = page.getByXPath("//tr[@class='athing']");
if(itemList.isEmpty()){
System.out.println("No item found");
}else{
for(HtmlElement htmlItem : itemList){
int position = Integer.parseInt(
((HtmlElement)
htmlItem.getFirstByXPath("./td/span"))
.asText()
.replace(".", ""));
int id =
Integer.parseInt(htmlItem.getAttribute("id"));
String title = ((HtmlElement) htmlItem
.getFirstByXPath("./td[not(@valign='top')]
[@class='title']"))
.asText();
String url = ((HtmlAnchor) htmlItem
.getFirstByXPath("./td[not(@valign='top')]
[@class='title']/a"))
.getHrefAttribute();
String author = ((HtmlElement) htmlItem
.getFirstByXPath("./followingsibling::
tr/td[@class='subtext']/a[@class='hnuser']")
)
.asText();
int score = Integer.parseInt(
((HtmlElement) htmlItem
.getFirstByXPath("./followingsibling::
tr/td[@class='subtext']/span[@class='score']
"))
.asText().replace(" points", ""));
HackerNewsItem hnItem = new HackerNewsItem(title,
url, author, score, position, id);
ObjectMapper mapper = new ObjectMapper();
String jsonString =
mapper.writeValueAsString(hnItem) ;
7/9
System.out.println(jsonString);
}
}
Printing the result in your IDE is cool, but exporting to JSON or another well-formated/reusable format is better. We will use JSON, with the Jackson library, to map items in JSON format.
First we need a POJO (plain old java object) to represent the Hacker News items:
HackerNewsItem.java
public class HackerNewsItem {
private String title;
private String url ;
private String author;
private int score;
private int position ;
private int id ;
public HackerNewsItem(String title, String
url, String author, int score, int position, int id)
{
super();
this.title = title;
this.url = url;
this.author = author;
this.score = score;
this.position = position;
this.id = id;
}
//getters and setters
}
Then add the Jackson dependency to your pom.xml:
pom.xml
<dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.7.0</version> </dependency>
Now all we have to do is create a HackerNewsItem, set its attributes, and convert it to JSON string (or a file …). Replace the old System.out.prinln() by this:
HackerNewsScraper.java
HackerNewsItem hnItem = new HackerNewsItem(title, url, author, score, position, id); ObjectMapper mapper = new ObjectMapper(); String jsonString = mapper.writeValueAsString(hnItem) ; // print or save to a file System.out.println(jsonString);
This example is not perfect; there are many other things that can be done:
- Saving the result in a database.
- Handling pagination.
- Validating the extracted data using regular expressions instead of doing dirty replace().
You can find the full code in this Github repository.
This blog post is an excerpt from a new book : Java Web Scraping Handbook. You may pre-order for a special discount!
2 replies on “Web Scraping with Java and HtmlUnit”
Can we screen scrape the Java Applet based application through HTML Unit?? If YES, How?? One example will be helpful.
It should be really buggy to scrape Java Applet based application with htmlUnit, there are some AppletViewer in Java that could do the job, but I don’t have any experience with that.
Kevin