In the post we share about web fingerprinting and particularly TLS fingerprinting. First let’s categorize the fingerprinting.
Passive Fingerprinting
This kind of Fingerprinting takes place at 3 levels:
- TCP
- TLS/SSL*
- HTTP

*TLS – Transport Layer Security, wiki. TLS is actually just a more recent version of SSL. It fixes some security vulnerabilities in the earlier SSL protocols.
Active Fingerprinting
- Browser fp – a server sends something to you (browser) and watches how you/browser react to that. This might be further categorized as the following:
– Canvas fingerprinting
– Behavior fingerprinting
TLS fingerprinting
Visit the website browserleaks.com/ssl to see your TLS data. When hashed, these will be TLS fingerprinting. Different browsers and robots run from the same machine will cause the TLS to differ.
- One User-Agent (UA) has only one TLS fingerprint.
- 1 TLS fingerprint for many UAs.
Anti-scrape tools match your TLS fingerprint to the UA that you are sending thru the request.
Bypass TLS fingerprinting [for web scraping]
- Randomize TLS Cipher [suite] parameters and randomize TLS version. Thus you send a different TLS code with each request. The challenge is to make random Cipher parameters match the TLS connection version.
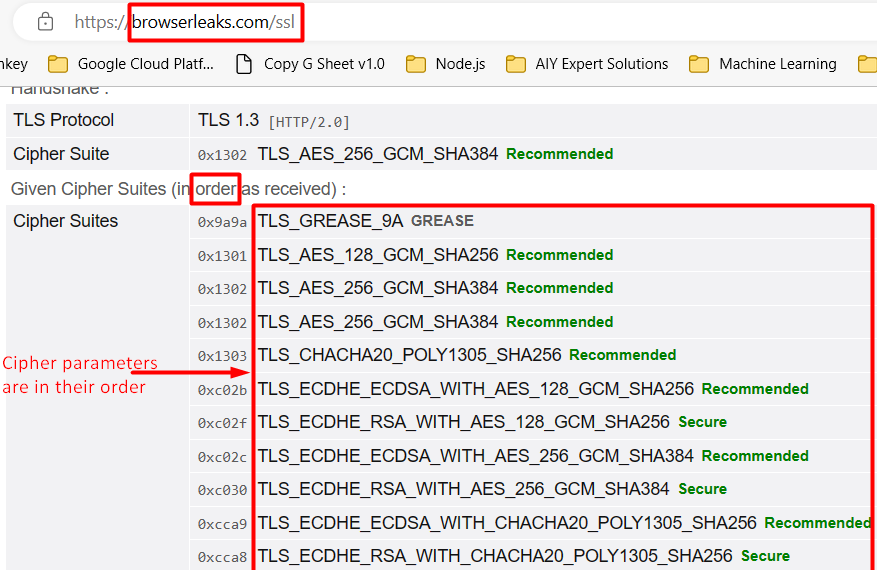
- Align all the TLS parameters with UA that we send. Yet for this we need a huge UA DB, that being the challenge.
The TLS manipulation is a thing in itself. The dealing with a combination of symmetric and asymmetric cryptography requires reading lots of RFQs. See more here. - Use real browsers with their real UA. Eg. you load different Chrome revisions with their corresponding UAs.
Conclusion
Let’s see how to react for web scraping as far as the TLS alignment is concerned.
Case 1. No need to deal with TLS alignment
• Many domains scrape
• One domain is not crucial if scrape fails
• Not much time for development
Case 2. TLS alignment realized
• Specific domain(s) scrape
• Data is crucial, it should not be compromised
• Bringing scraping bots to the next level
The TLS alignment for web scraping comparison table
| No need to deal with TLS alignment | TLS alignment realized | |
| Scrape scope | Many domains scrape | Specific domain(s) scrape |
| Critical data | One domain is not crucial if its scrape fails | Data is crucial, no data to miss |
| Timing | Not much time for development | Decent timing for TLS alignment |
| Development | No | Yes, incl. studying HTTP Secure level crypto |
| Bot level | Regular | Bringing scraping bots to the next level |