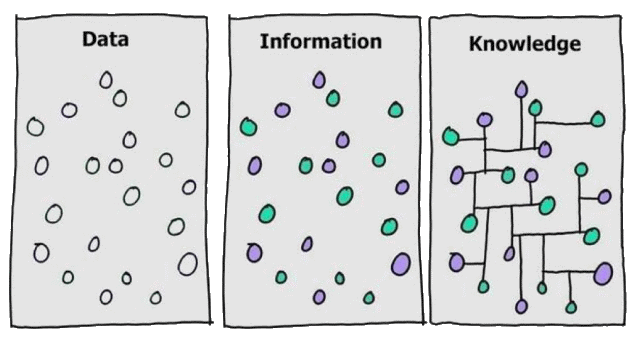
Have you ever thought that there is a difference between such terms as “data”, “information” and “knowledge”? Often people mix and misuse them and it’s not a problem in our daily life, but when we come to Data Mining it’s good to distinguish them. Here I’ll try to show the difference in an comprehensible way.