Recently we encountered a new powerful scraping service called Web Scraper IDE [of Bright Data]. The life-test and thorough drill-in are coming soon. Yet now we want to highlight its main features that has badly (in positive sense, strongly) impressed us.

- Pre-made collectors
- Request a new collector or develop it yourself
- Unblocking tough sites
- Data delivery & integration
- Data retention
- Cost
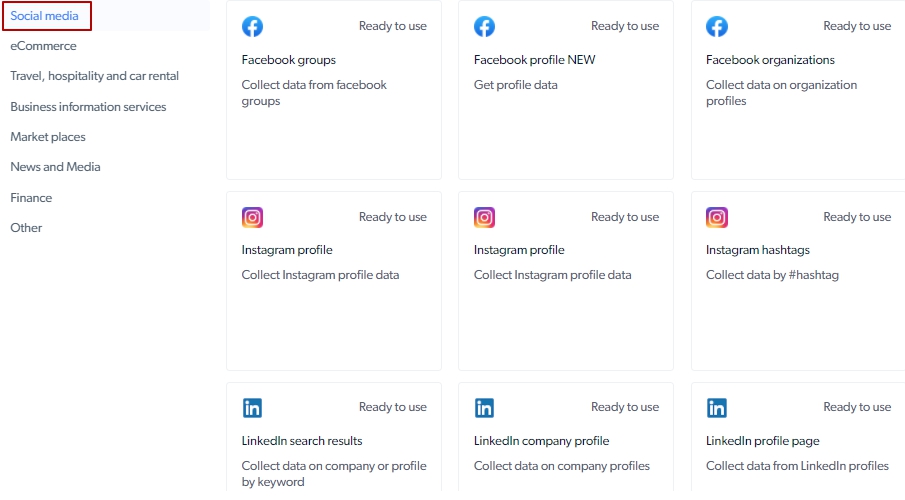
Hundreds of free pre-made agents to gather data of top scrape targets
Data Collector in its nature is a scraping agent that is developed (already!) for a specific task. So, zero-coding-level individuals are welcome to use it. Take a look at the shot of the pre-made free to use data collectors. Eg.:
eCommerce category:
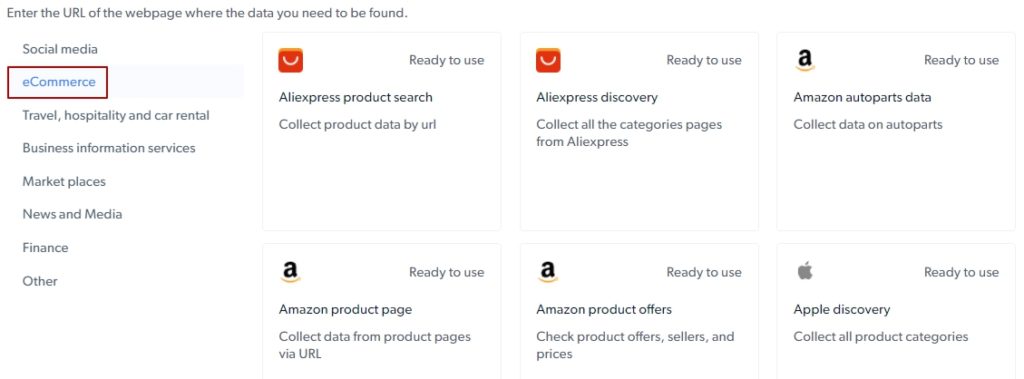
Social media category:
Request for a new collector to be coded or develop it yourself
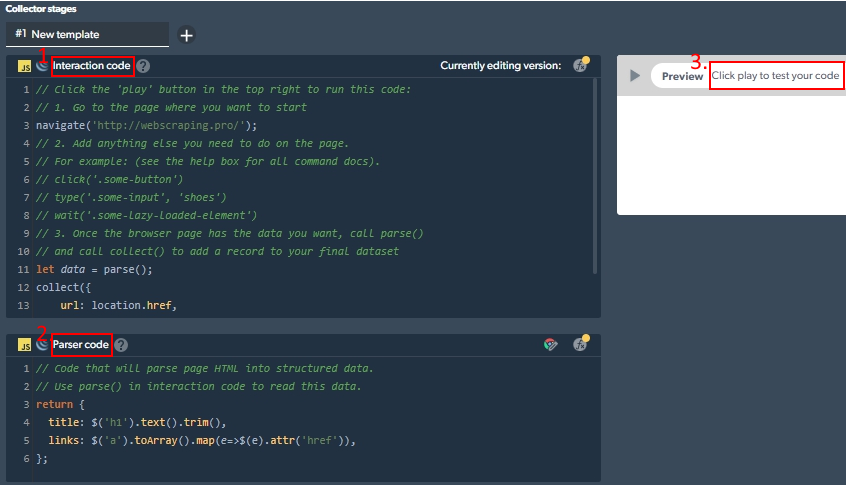
Besides using premade scraping agents/collectors one might (1) request a custom collector or (2) develop your own (with JavaScript) inside a friendly coding environment (IDE) or (3) edit a pre-made agent to tailor it to own needs.
Take a look at the IDE, the page interaction code being separated from the page parsing code:
Note: the cost of ordering a collector (along with its maintenance) is USD $150.
Unblocking tough sites
How to unblock tough sites as business directories and CloudFlare protected ones? The Data Collector utilizes a huge residential and data center proxy network provided by Bright Data. No need therefore to pay for any extra proxy services.
Data delivery & integration
The Bright Data offers various ways to deliver and integrate extracted data.
- SFTP
- Amazon S3
- Google Cloud Storage
- Microsoft Azure Storage
- API download
- Webhook
Besides, one may get data not just (1) at a job completion yet also (2) in real time with a single request.
Data retention
The scraped data retention is 1 week only.
Cost
The service provides quite budget pricing. The max cost is USD $5 for collection of 1000 successful pages.
Conclusion
The Web Scraper IDE by Bright Data seems to meet the present web scraping challenges (business directories scrape, data integration) while keeping a moderate pricing and providing a big heap of pre-made scrape agents.
See other Bright Data Scraping Solutions
| Provider | Time | Bandwidth |
|---|---|---|
| IPRoyal | 2 ½ hour | 5.9 Gb |
| MarsProxies | 3 ½ hour | 4.7 Gb |
| NetNut | 3 ¾ hour | 5.8 Gb |