![]() Recently we encountered a new service that helps users to scrape the modern web 2.0. It’s a simple, comfortable, easy to learn service – https://dataflowkit.com
Recently we encountered a new service that helps users to scrape the modern web 2.0. It’s a simple, comfortable, easy to learn service – https://dataflowkit.com
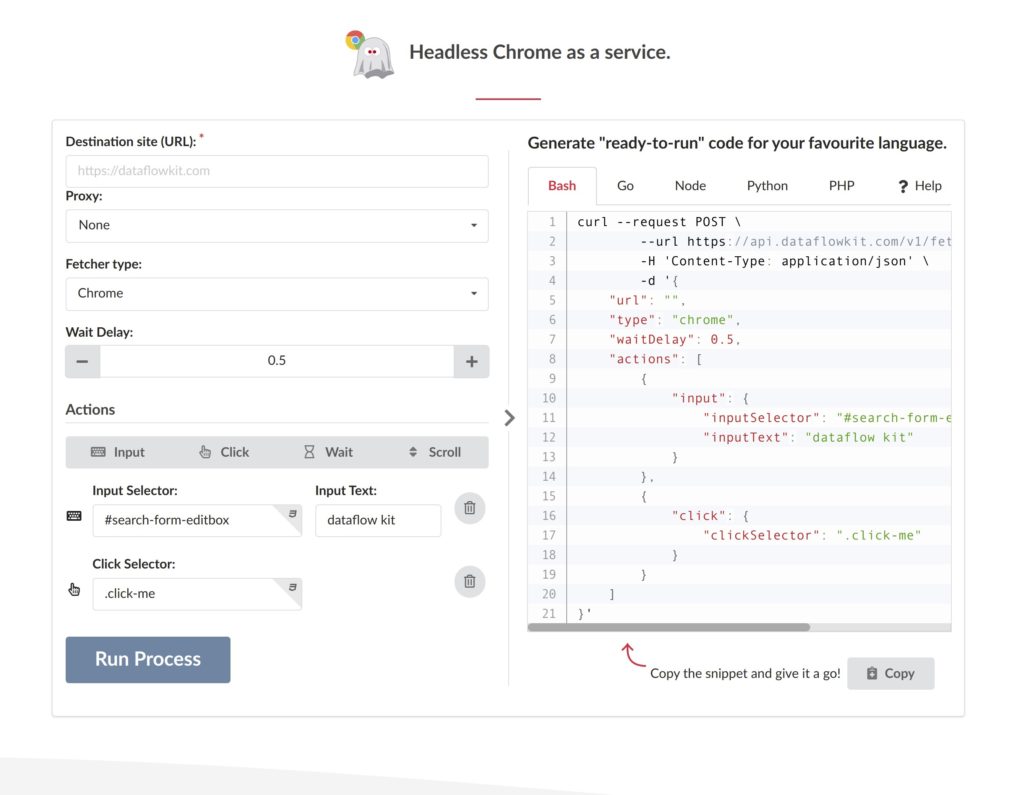
Let’s first highlight some of its outstanding features:
- Visual online scraper tool: point, click and extract.
- Javascript rendering; any interactive site scrape by headless Chrome run in the cloud
- Open-source back-end
- Scrape a website behind a login form
- Web page interactions: Input, Click, Wait, Scroll, etc.
- Proxy support, incl. Geo-target proxying
- Scraper API
- Follow the direction of robots.txt
- Export results to Google drive, DropBox, MS OneDrive.
Ajax and JS evaluation
The service manages to run headless Chrome browser in the cloud. So it can render Javascript web pages to a static HTML. JavaScript code evaluation support is in progress… the service developers are to implement a new custom JS code evaluation action.
Monitoring
Once a task is created, it is possible to build new processes spawned from it. Click Start/Stop buttons to launch/stop a process accordingly.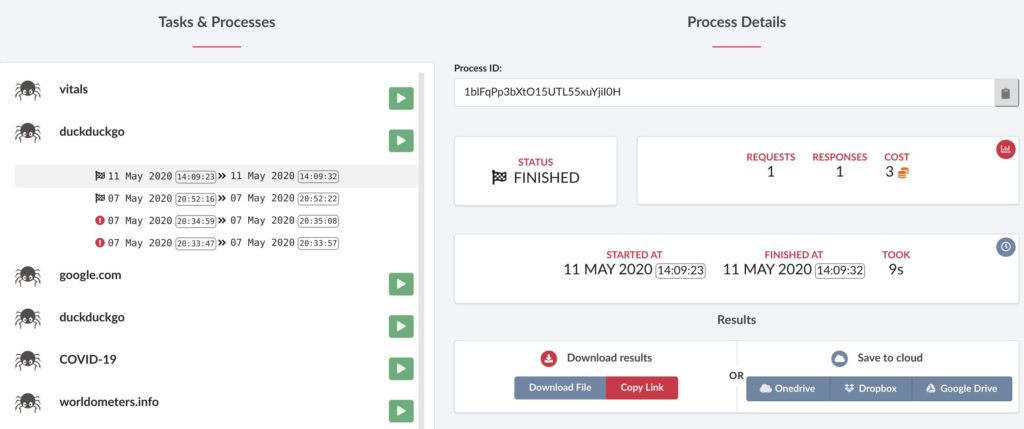
Detailed information is shown in blocks with current status, start/finish time, requests/responses, and cost. Balance (remaining credits) is shown on the right top of the dashboard.
Proxies
Proxies are included in the service, but no external proxies plugin option is available.
Select the target country from 100+ supported global locations to send your web/SERPs scraping API requests.
Specify proxy by adding country ISO code to country- value to send requests through a proxy in the specified country.
Use country-any to use random Geo-targets.
Import & export scrape projects
It is possible to reuse saved projects. Go to https://dataflowkit.com/collections
Data storage
The service uses MongoDB as a central (intermediary) storage.
Users may choose one of the following formats to export data: CSV, JSON (Lines), Excel, XML. The service allows converting the resulted JSON to the most popular RDBMS or Clouds using JSON2SQL tool – https://dbconvert.com/json-sql
After completing a scraping project, data may be downloaded from S3 compatible storage.
Optionally, users can upload scraped data to one of the most popular cloud storage possibilities, including Google Drive, Dropbox, Microsoft Onedrive.
Some service’s bounties
Multi-threading
One can internally scale up and down the number of scraping/parsing requests to a web site.
Log in to website
Target website log-in has been implemented. But currently, it is not publicly available.
Page into PDF
Url-to-pdf service is available at https://dataflowkit.com/url-to-pdf
Screenshots
Url-to-screenshots option: https://dataflowkit.com/url-to-screenshot
Form Navigation
Here is a list of available actions:
“Input” action – Performs search queries, or fills forms.
“Click” action – Clicks on an element on a web page.
Pagination & infinite scroll
Pagination is supported. “Scroll” action – automatically scrolls a page down to load more content.
Scraper API
DFK API is easy integrated with web applications using a favorite framework or language, including Curl, Go, Node.js, Python, PHP. Dataflow Kit OpenAPI (Swagger) specification is available at https://dataflowkit.com/open-api
It only takes a few minutes to start using its API at scale using visual code generators available at service pages.
One may generate a “ready-to-run” code for your preferred language in no time.
Service’s shortages
CAPTCHA solving is not supported in the service. Neither scheduling nor multiple users are supported. Neither images nor files scrape are supported. Iterate drop-down options and OCR are not supported even though not many services support it.
Multiple inputs are partially supported.
Pricing
Requests to web pages for data extraction are measured in CREDITS. Once after sign-up, you are granted free 1000 credits, which is equal to €5 for evaluation and testing. See the following table to evaluate the cost by a scrape type:
| Production setup | Development setup | |
|---|---|---|
| 1. Code | Code is split & gets minified. | No |
| Code | Code is split | No |
| 2. Manifest file | Yes | Yes |
| 3. Pre-cache manifest | Pre-cache manifest gets generated | No |
| 4. Source references | No | Source map |
| 5. Dev server & Hot reload | No | Hot reload at Development server for debug purposes and caching |
| 6. | No | Development serverfor hot reload and caching |
| 6. Entry file name | index.production.phtml | index.developmet.html |
| 7. Build & debug | 2 steps build | Cached files instead of generated files |
| 8. Build speed | Slow | Much faster than in Production mode |
Conclusion
We find the service is an easy online way to learn to use a scraping tool with many basic functions pertaining to the scraping suit. The service cost is calibrated dependent on the kind of web pages a user wants to scrape: static web pages , js-rendered pages , and SERP.
Watch a short video of a DataFlowKit scraper creation:
https://www.youtube.com/watch?v=5gRcftONmTU