 In the age of the modern web there are a lot of data hunters people who want to take the data that is on your website and re-use it. The reasons someone might want to scrape your site are incredibly varied, but regardless it is important for website owners to know if it is happening. You need to be able to identify any illegal bots and take necessary action to make sure they aren’t bringing down your site. Not all bots are malicious (think search engine bots) so I’ve outlined some criteria for site owners and developers to use to identify if and how their site is being scraped.
In the age of the modern web there are a lot of data hunters people who want to take the data that is on your website and re-use it. The reasons someone might want to scrape your site are incredibly varied, but regardless it is important for website owners to know if it is happening. You need to be able to identify any illegal bots and take necessary action to make sure they aren’t bringing down your site. Not all bots are malicious (think search engine bots) so I’ve outlined some criteria for site owners and developers to use to identify if and how their site is being scraped.
This post merely categorizes the ways in which people may be scraping your site. For more on how to prevent scraping from happening you can read this post on how to prevent web scraping activity.
Type A. Outwardly sensitive scraping
- Network bandwidth occupation, causing throughput problems. Bandwidth issues are often the harmful result of annoying web scraping, but if you’re properly monitoring your servers bandwidth you should get an early alert of unwanted bots visiting your site.
Matches if proxy used - When querying search engines for key words new references appear to other resources with the same content.
- This should be your SEO team’s job, since after your valuable content is fetched and re-posted you might get potential visitor loss. So watch your traffic analytics carefully.
Matches if proxy used
Type B. Programming detectable only
- Multiple requesting from the same IP.
- High requests rate from a single IP.
- You can configure your server to limit requests rate, but you can’t do much to prevent frequent yet proxy-armed bots.
- Headless or weird user-agent.
Matches if proxy used - Requesting with predictable (equal) intervals from the same IP.
- Certain support files are never requested, ex. favicon.ico, various CSS and javascript files.
Matches if proxy used - The client’s requests sequence. Eg. client accesses not directly accessible pages.
Matches if proxy used
Note 1
If you’re getting scraped a lot you might want to consider providing an API for bots. If your site is being scraped for information you want to provide anyways, an API is incredibly valuable and most people would prefer to use it rather then scrape your site. Creating an API will substantially reduce server load and give you a better idea who is reusing your content (source).
Note 2
You should be tracking which user-agents access your website. If someone is using an automated user-agent or one out of a development language, it will show up differently from your average user (source). Watch the log files. See HTTP request’s headers of a real browser based request: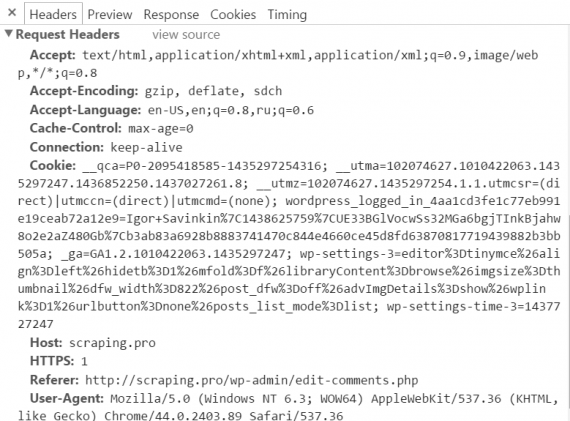
Note 3
That may not work in all cases because a lot of browsers can be configured not to download any dependencies unless the user clicks on them (i.e., ad blockers, flash blockers, etc.). Text browsers may not download certain dependencies either.
Hopefully these scraping signals will be of use to both developers and site owners. Please comment if you notice other ways scraping might be detected. For those who want to know how to fight web scraping activity or bypass it :-), read about 7 ways to protect website from scraping and how to bypass this protection.