Often for the purpose of scraping, one needs to find certain elements’ XPath on a webpage. How can one do that with browser Web developer tools, aka Web inspector? A picture is worth of thousand words. 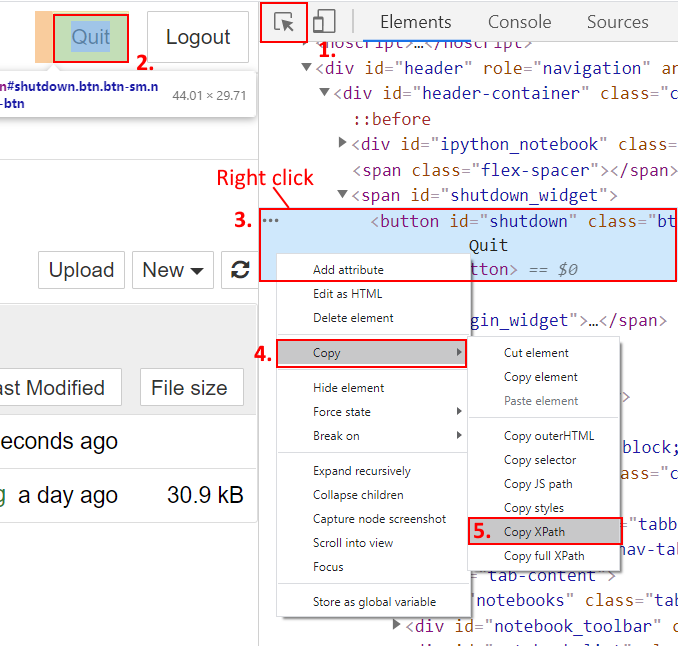
In the Chrome browser web dev. tools (F12) you execute the following steps:
- Choose Elements tab
- Press Element Selector button
- With that button pressed you click an element in the main browser window.
- In the DOM-elements window you right-click that highlighted element.
- The context menu appears, and you choose Copy.
- Choose Copy XPath in a sub menu. Now you have that element’s XPath in a console buffer.
Attention!
The browser composes an element’s XPath based on its own algorithm. It might not be the way you think or the way that fits to your code. So, you have to understand XPath in nature, be acquainted with it.
For example the Chrome browser has issued for Trailing P/E element at a Yahoo finance page the following xpath:
//*[@id=”main-0-Quote-Proxy”]/section/div2/section/div/section/div2/div1/div1/div/table/tbody/tr[3]/td1/span
2 replies on “Find XPath using web developer tools”
That is a great tip. So far, it has worked perfectly for me while working on a C#.NET app. The only thing I had to do was escape quotes in the string.
Sample directly from Chrome Copy Xpath://*[@id=”login-loginForm”]/p/button/span
After adding Escape for quotes: //*[@id=\”login-loginForm\”]/p/button/span
Great information about XPath.
This tutorial simplifies my web parsing process in php curl.
Thanks a lot