Web scraping is a technique that enables quick in-depth data retrieving. It can be used to help people of all fields, capturing massive data and information from the internet.
As more and more people turn to web scraping for acquiring data, automatic tools, like Octoparse, are getting popular and helping people to quickly turn web data into spreadsheets.
However, the web scraping process does put extra pressure on the target website. When a crawler is unrestrained and sends an overwhelming amount of requests to a website, the server could potentially crash. As a result, many websites “protect” themselves using anti-scraping mechanisms to avoid being “attacked” by web-scraping programs.
Luckily for those that do need the data and want to scrape responsibly, there are solutions to avoid being blocked by anti-scraping systems. In this article, we will talk about some common anti-scraping systems and discuss the corresponding solutions to tackle them.
1. Scraping speed matters
Most web scraping bots aim to fetch data as quickly as possible, however, this can easily cause you to be exposed as a scraping bot, as there’s no way a real human can surf the web so fast. Websites can track your access speed easily and once the system finds that you are going through the pages too fast, it will suspect that you are not a human and block you by default.
Solution: We can set random time intervals between requests, i.e., we can either add “sleep” in the code when writing a script or set up wait time when using Octoparse to build a crawler. Further reading: https://www.octoparse.com/tutorial-7/set-up-wait-time.
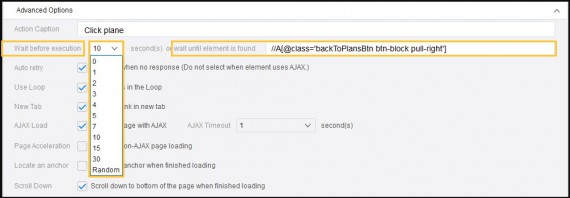
2. Dealing with CAPTCHA
Type 1: Click the CAPTCHA option
Type 2: Enter the CAPTCHA code

Type 3: Select the specified images from all the given images.

Solution of Octoparse: With the surge of the image recognition tech, conventional CAPTCHA can be cracked easily, through it costs a lot. Tools like Octoparse do provide cheaper alternatives, however with somewhat compromised results. Further reading: https://helpcenter.octoparse.com/hc/en-us/articles/360018047392-Is-Octoparse-able-to-handle-CAPTCHA-reCAPTHCA
Unfortunately Octorparse does not provide an interface to plug-in external captcha-solving services like DBC, imagetyperz, 2captcha, etc. But such services for a really small cost provide real-time CAPTCHA solvings, streamlining scrapers’ work.
Yet, Octorparse does provide [its own] CAPTCHA-solving service in Chinese. Premium users may plug it into the Octorparse cloud.
3. IP restriction
When a site detects that there are a number of requests coming from a single IP address, the IP address can be easily blocked. To avoid sending all of your requests through the same IP address, you can use proxy servers. A proxy server is a server (a computer system or an application) that acts as an intermediary for requests from clients seeking resources from other servers (from Wikipedia: Proxy server). It allows you to send requests to websites using the IP you set up, masking your real IP address.(https://en.wikipedia.org/wiki/Proxy_server)
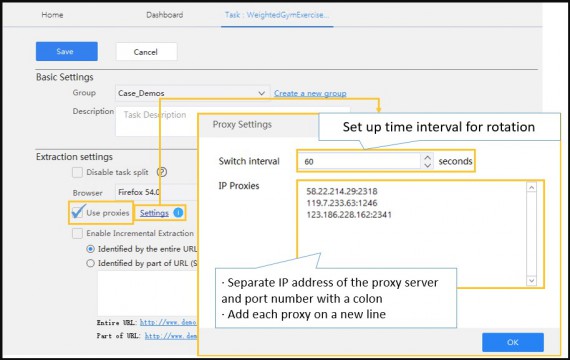
Of course, if you use a single IP set up in the proxy server, it is still easily blocked. You need to create a pool of IP addresses and use them randomly to route your requests through a series of different IP addresses.
Solutions: Many servers, such as VPNs, can help you to obtain rotated IPs. Octoparse Cloud Service is supported by hundreds of cloud servers, each with a unique IP address.
When an extraction task is set to be executed in the Cloud, requests are performed on the target website through various IPs, minimizing the chances of being traced. Octoparse local extraction allows users to set up proxies to avoid being blocked.
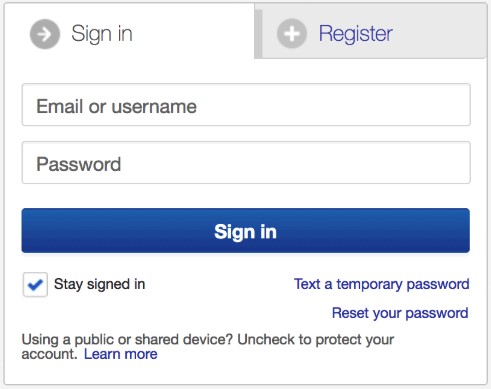
4. Scrape behind login
Login can be regarded as a permission to gain more access to some specific web pages, like Twitter, Facebook and Instagram. Take Instagram as an example, without login, visitors can only get 20 comments under each post.
Solution: Octoparse works by imitating human browsing behaviors, so when login is required to access the data needed, you can easily incorporate the login steps, i.e. inputting username and password as part of the workflow. More details can be found in Extract data behind a login. Further reading: https://helpcenter.octoparse.com/hc/en-us/articles/360018008812-Extract-data-behind-a-login
5. Employing the JavaScript encryption tech
JS encryption tech is used to keep content safe from being scraped. Crawlers that are written in JavaScript can be “tricked” easily.
Solution: When an HTTP Post request is sent, there is no doubt that JavaScript encryption will make it more difficult to scrape; however, with Octoparse, this can be easily dealt with as Octoparse can directly access the data from the target website by its built-in browser, then analyze the website’s structure automatically.

6. Be aware of honeypot traps
Honeypots are links that are invisible to normal visitors but are present in the HTML code and can be found by web scrapers. They are just like traps which detect the scraper and direct it to blank pages. Once a particular visitor browses a honeypot page, the website can be relatively sure it is not a human visitor and starts throttling or blocking all requests from that client.
Octoparse uses XPath for precise capturing or clicking actions, avoiding clicking the faked links (see how to use XPath to locate element here).
7. Pages with different layouts
To avoid being scraped easily, some websites are built with slightly different page layouts. For example, page 1 to 10 of a directory listing may look slightly different than page 11 to 20 from the same list.
Solution: There are two ways to solve this. For crawlers that are written in JavaScript, a set of new codes is needed. For the crawlers built with Octoparse, you can easily add a “Branch Judgment” into the workflow to tell the different layouts apart, then to proceed to extract the data precisely. Further reading: https://helpcenter.octoparse.com/hc/en-us/articles/360018281431-Advanced-Mode
We hope all these tips above can help you build your own solutions or improve your current solution. You’re welcome to share your ideas with us or anything you feel that could be added to the list.
One reply on “Web scraping: How to bypass anti-scrape techniques”
To be honest, most of the problems can be solved while using proxy services. Especially when it comes to geo-restrictions and masking your scraper from the detection of the website. Nowadays you can easily find high-quality proxy services, like smartproxy, geosurf, microleaves, etc. that can be used to work on web scraping tasks. I’ve never tried using VPN in this case, should look for more info about that.
All in all, great article and detailed explanations.