Inspyder Power Search is a crawling and scraping application which is more for straightforward scraping, using both XPath and Regex. The program has a simple, nice interface making it easy to learn and employ it.
Inspyder is designed for multiple purposes:
- Regex application
- Using Xpath for finding html elements
- Extract Match performing
- Wildcard matching
- Scrape by crawling as many pages as possible and applying a predefined pattern
You can find a user manual at the product official page.
This application functions well with combining both XPath (ex. extract some hidden page elements: titles or image “alt” attribute text) and Regex (point and click interface). It enables to work with both techniques at the same interface to crawl or scrape data. So, if for certain pages one needs to set extraction patterns using both XPath and Regex, this tool fits the best.
Concerning the disadvantages, I would mention the lack of pages navigation techniques; that is, the crawler works to scrape all similar (of the same domain name) pages; no explicit navigation is possible. It’s possible only to exclude certain pages from program crawl. The crawler evidently does not perform web forms filling or captcha bypassing.
Other application features are:
- Scheduling of crawling and scrape jobs
- Email notification upon completion of the scheduled crawling job.
The following picture gives a brief view of how the Inspyder works for scrape:
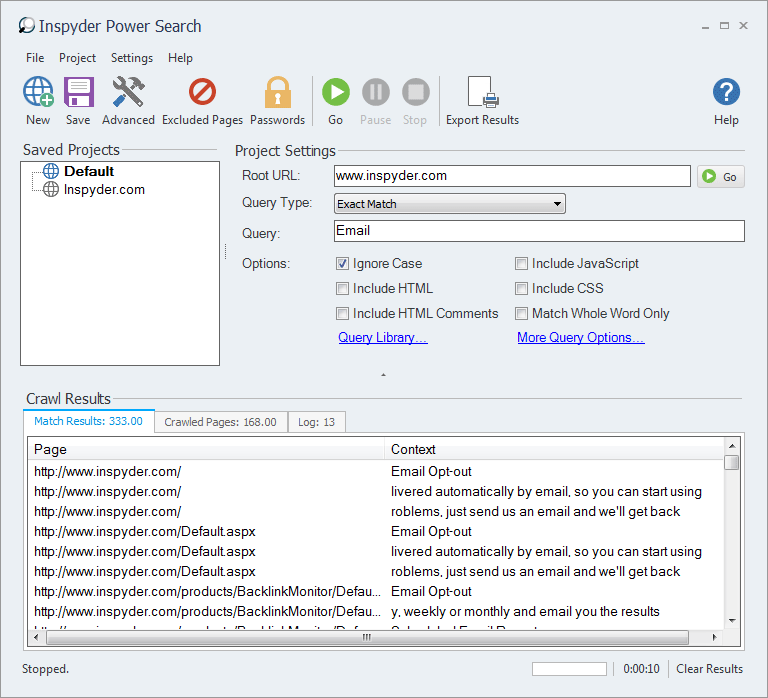
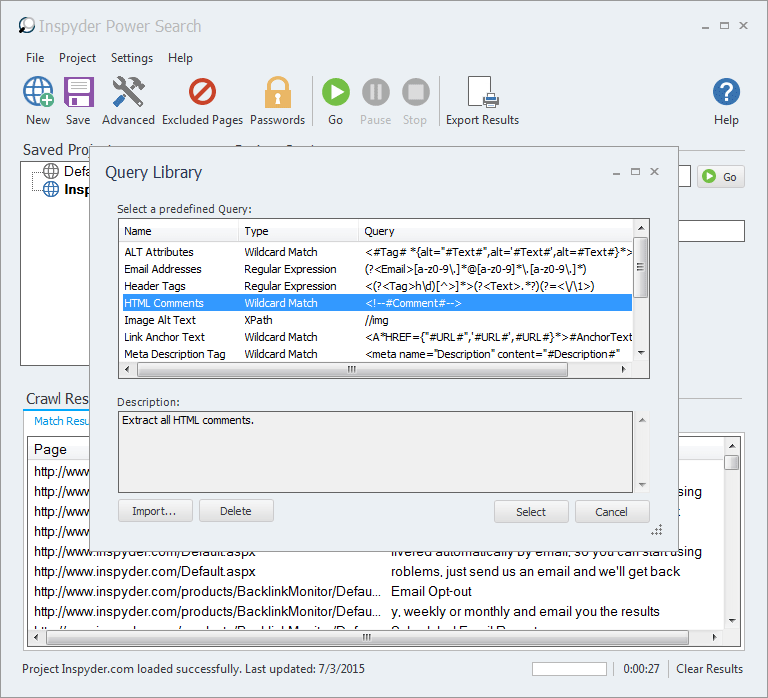
The export can be performed in 2 formats, CSV and XML.
Advanced options
There are also several advanced options:
- crawler delay
- crawler timeout
- user agent disguise
- max file size definition
- max crawl depth definition
- crawler threads (multi-threading) setting
- JavaScript processing
Summary
This simple scrape application, Power Spider, works well for casual, non-commercial scrape tasks, as well as to let developers to explore HTML page structures and work to find and to apply XPaths. One may also use Regex testing upon a set of pages with this program.