I want to share with you the practical implementation of modern scraping tools for scraping JS-rendered websites (pages loaded dynamically by JavaScript). You can read more about scraping JS rendered content here.
Since the project is big, I’ve highlighted some of its sections and you can directly move into them.
1. Project objective
The task for the project was to scrape Xing companies’ info (those in public access) related to certain countries – Germany, Austria and Switzerland. So the seemingly easy task motivated me to develop a serious web scraping project.
This post only presents the project design, tools, algorithm and results. The JS code will be provided in the next post. Feel free to subscribe for notifications of new posts.
2. Project tools
Let me share with you which tools I have chosen to perform the data aggregator scrape.
Node.js is a JavaScript run-time environment, Node.js being a modern tool for server-side scripting.
Puppeteer is a Node.js library for driving headless Chrome or Chromium (no visible UI shell). It makes it possible to run web browser(s) on servers without the need to use X Virtual Framebuffer (Xvfb). Puppeteer gives simple & powerful high-level API for automation browsers (Chrome & Chromium only). Compare with python driving headless browser.
I’ve chosen the Apify SDK, a Node.js library, for the purpose of managing (incl. scaling) a pool of headless Chrome/puppeteer instances. It turned out to fit best to crawl, collect and process 10’s of thousands of URLs from a data aggregator (as Xing is), being a powerful solution. Below I’ve stated some of the Apify SDK features:
- automatically scales a pool of headless Chrome/puppeteer instances
- maintains queues of URLs to crawl (handled, pending)
- saves crawl results to a convenient [json] dataset (local or in the cloud)
- rotates proxies
So, on the practical side, in this scraping project, I have used the Node.js along with Apify [SDK] library.
We will use PuppeteerCrawler of the Apify [SDK] library as the most powerful among the crawlers in that library. Although, if the target website doesn’t need JavaScript to process it, consider using CheerioCrawler instead of PuppeteerCrawler. CheerioCrawler downloads the pages using raw HTTP requests and is about 10 times faster.
Previous tools for scraping JS-rendered websites
3. GitHub integration
The Apify cloud service works using Actors. Actor is a micro-service that performs a data extraction job. It takes an input configuration, runs the job and saves results. So first I created an Apify project locally. Then I pushed it to Github, and then I took a link from Github to create an actor in the Apify cloud.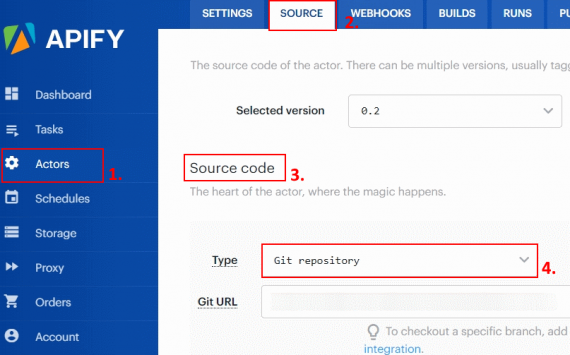
For starting an Apify actor locally, it is better to quick start it by using the apify create command, if you have Apify’s CLI. Then you can git init. For a Quick Start refer to here.
4. The scrape scope evaluation
Ok, we approach the business directory (Xing) containing hundreds of thousands of companies. For all countries and even for a given country the Xing hides the total amount of entries if total number is over 10K. See the following: 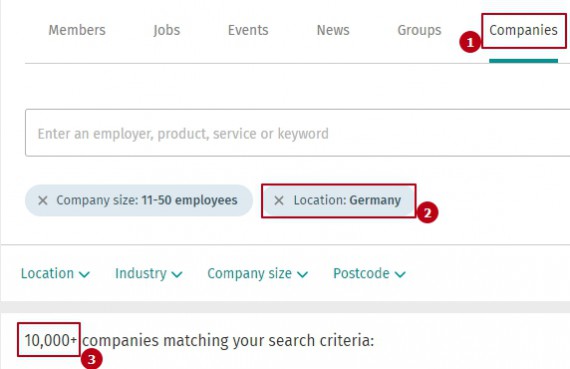
Besides the aggregator returns only a limited number of results for each search request (namely 10 x 30 = 300):
5. Approximation process
The approach for evaluating the scrape scope was to approximate the number of entries for the country in question (in our case it is Germany). First we approximate total number (of a hidden category) using % of a certain [smaller] country where the number is shown by Xing. Then we perform an approximation for hidden categories based on the average % of [German] companies.
Germany companies, Table 1
| Company category | Number | % of total number |
|---|---|---|
| 10001 or more | 793 | 57 |
| 5001-10000 | 511 | 64 |
| 1001-5000 | 2783 | 71 |
| 501-1000 | 2532 | 69 |
| 201-500 | 5372 | 70 |
| 51-200 | 10000+ | |
| 11-50 | 10000+ | |
| 1-10 | 10000+ | |
| Just me | 2144 | 46 |
| average – 63 |
Now, we take a small country (Austria), get its number of companies (for known categories) and find out what % they are of the Total number of companies (for each known category) .
Austria companies, Table 2
| Company category | Number | % of total number |
|---|---|---|
| 10001 or more | 73 | 5 |
| 5001-10000 | 53 | 7 |
| 1001-5000 | 264 | 7 |
| 501-1000 | 226 | 6 |
| 201-500 | 418 | 5 |
| 51-200 | 1046 | n/a |
| 11-50 | 2191 | n/a |
| 1-10 | 5322 | n/a |
| Just me | 297 | 6 |
| average – 6 |
Now as we calculate the avg. Total companies number in Xing (based on, e.g., Austria data) and knowing the avg. % of German companies in Xing, we may approximate Germany’s missing categories number:
Germany companies approximated, Table 3
| Category, by employees number |
Total companies in Xing | Total companies approximation, based on Austria data, see Table 2 |
Germany companies, based on Total approximated and avg. % of German companies, see Table 1 |
|---|---|---|---|
| 10001 or more | 1400 | ||
| 5001-10000 | 800 | ||
| 1001-5000 | 3937 | ||
| 501-1000 | 3646 | ||
| 201-500 | 7727 | ||
| 51-200 | 10000+ undefined | 19716 | 12421 |
| 11-50 | 10000+ undefined | 41621 | 26221 |
| 1-10 | 10000+ undefined | 96906 | 61051 |
| Just me | 4704 |
Having approximated figures, we can roughly estimate the number of records for scrape. Besides, it gives you the possibility to count the scrape cost if paid by entry.
6. Accounts
The Xing aggregator limits each account to disclosing only up to 5000 pages per month. So, since we scrape much more, we create and utilize several Xing accounts. It is not necessary for them to be Premium ones.
7. Cloud scrape efficiency
| Local execution | Cloud execution, requests per hour |
|
|---|---|---|
| 1050 requests per hour(1) | 1325 requests per hour (2) | |
| 260 JS-rendered pages per 1 CU |
(1) Limited with processor capability: Intel(R) Core(TM) i5, CPU @ 1.33 GHz Processor, 12Gb RAM and 64 bit Operating System (Win 10)
(2) Limited with allocated memory: 8.2 GB.
Local
I initially scraped using my local PC. This scrape was conducted using a machine with Intel(R) Core(TM) i5, CPU @ 1.33 GHz Processor, 12Gb RAM and 64 bit Operating System (Win 10).
Cloud
Apify Cloud platform measures scraping processing resources using Compute units (CU).
With the cloud execution 1 Compute unit (CU) has been spent for approximately 260 crawl pages. It was less than expected, namely 400 JS-rendered pages per 1 CU as claimed at their site.
And the Apify support team (very responsive, believe me) explained that 400 JS-rendered pages per 1 CU is the broad average and the Xing pages can be heavier or the scraper code might not be optimized enough. The latter is right, since I logged out a quite lot for the sake of gathering numerical performance data.
8. Speed
The actual execution or the scrape speed depends on the allocated memory (and thus CPU share) that drives the concurrency. It’s this way since the Apify SDK balances the memory load when concurrent threads are in run. Since I was using a free developer plan, the running actor memory 1 was limited to 8.2 GB. The scrape speed reached was comparable with my local scraping speed (Intel i5 @1.33 GHz). See the table in section 7.
Their support just shared with me: “We would happily increase actor memory for free. The limit is there to prevent system abuse”.
9. Scrape algorithm
How to retrieve all the companies if the aggregator returns only a limited number (threshold = 300) of companies per search request? Right, we need to make many various search requests to reach all kinds of companies. The aggregator has made it possible by categorizing the searches.
Since the search queries query the Xing’s own DB, the result might be not delivered as fast as ready-to-deliver content. For that reason, support recommends setting up a big timeout value. Mine was 500 sec.
Filter
One may choose to filter searches by number of employees (company size), locality, industry, and even post index.
I’ve chosen to make multiple searches with specific location and company size. See the sample requests:
https://www.xing.com/search/companies?filter.location[]=2921044&filter.size[]=8&keywords=h
https://www.xing.com/search/companies?filter.location[]=2782113&filter.size[]=7&keywords=ac
The query parameters filter.location[], filter.size[] speak for themselves.
Xing has a small number of companies if filtered by company size for Austria and Switzerland. Yet concerning Germany I had to extend the filtering, adding a keywords parameter. I made that parameter to be equal with single letters ({a, b, c…}) and with coupled letters ({aa, ab, ac…}) to narrow down the search results number even more. Thus, almost all the search requests returned the number of results as less than Xing’s threshold.
Performing search requests, the crawler gathers the companies’ pages’ urls. The same crawler will request those urls to collect each company info. The Apify SDK makes it super easy to push a single info into a JSON data record (a JSON file if locally). Later it becomes a consolidated JSON dataset.
10. Data validation
The gathered data I had to validate, since in some cases Xing substituted company website info with its own website. So, I ran Python scripts to analyze data units and find if some have a website field containing ‘xing.com’. Besides, I’ve validated datasets by country & employees number.
11. Numerical Results
It turned out that most of the results were extracted from my local PC, the scraping in the cloud having been done at the Apify cloud platform too.
Performance in cloud
The actual requests done (both search requests and companies pages requests) as a function to the Compute units used.Speed graph
Conclusion
The scrape project using Node.js scripting was new to me. However, it revealed Node.js features such as simplicity and [threads] asynchronous execution. Apify SDK library greatly helped to work out scalability, memory management, data storing and the Apify cloud worked well with the script cloud executions.
The project code will be published in a following post. Get subscribed.