 The web is becoming increasingly difficult to scrape. There are more and more websites using single page application frameworks like Vue.js / Angular.js / React.js and you need to use headless browsers to extract data from those websites.
The web is becoming increasingly difficult to scrape. There are more and more websites using single page application frameworks like Vue.js / Angular.js / React.js and you need to use headless browsers to extract data from those websites.
Using headless Chrome on your local computer is easy. But scaling to dozens of Chrome instances in production is a difficult task. There are many problems, you need powerful servers with plenty of RAM, you’ll get into random crashes, zombie processes…
The other big problem is IP-rate limits. Lots of websites are using both IP rate limits and browser fingerprinting techniques. Meaning you’ll need a huge proxy pool, rotate user agents and all kinds of things to bypass those protections.
ScrapingBee solves all these problems with a simple API call.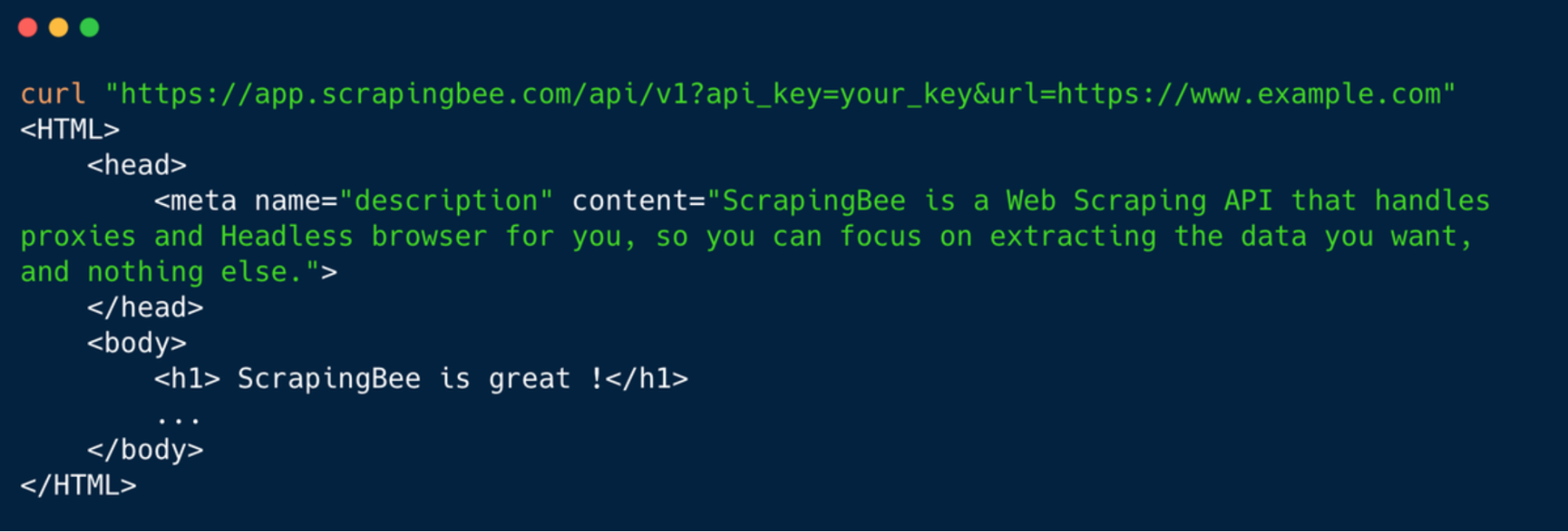
Features
- Large proxy pool, datacenter and residential proxies
- Javascript rendering with headless Chrome
- Ready-made APIs to scrape popular websites like Google and Instagram
- IP geolocation
- Execute any Javascript snippet
- Top-notch support. At ScrapingBee we treat customers as real human beings, not ticket numbers.
In this post we are going to see the different things you can do with the ScrapingBee API.
Web Scraping API
The web scraping API is very useful to scrape IP-rate limiting websites or websites that use a lot of Javascript that needs to be rendered in a headless browser.
We are going to see an example on how to use the ScrapingBee API to extract data from Amazon products. Amazon can be quite complicated to scrape because of rate limits.
Here is a basic code that will extract the product title, image url and price: (gist: https://gist.github.com/ScrapingNinjaHQ/8b2c7ff5a4dee082601f32604b28e505 )
import csv
from urllib.parse import unquote, quote, urlparse
import json
import requests
from bs4 import BeautifulSoup
# Extract product data from amazon
# https://www.scrapingbee.com/
# Replace with your ScrapingBee API
SCRAPINGBEE_API_KEY = ""
endpoint = "https://app.scrapingbee.com/api/v1"
rows = []
params = {
'api_key': SCRAPINGBEE_API_KEY,
'url': 'https://www.amazon.fr/Coders-Work-Reflections-Craft-Programming/dp/1430219483/',
}
response = requests.get(endpoint, params=params)
if response.status_code != 200:
print('Error with your request: ' + str(response.status_code))
else:
soup = BeautifulSoup(response.content, 'html.parser')
product = {
'price': soup.select('span.offer-price')[0].text,
'image_url': soup.select('img#imgBlkFront')[0]['src'],
'product_title': soup.select('span#productTitle')[0].text
}
print(product)More parameters
There are many parameters that can be added to the API call. For example, you can execute arbitrary Javascript snippet to the headless browser. You could need this if you need to scroll a page.
You could also specify a wait if the page fires a lot of AJAX requests to wait for completion.
Another interesting parameter is the premium_proxy parameter. This will use Residential proxies instead of data center ones, which are much more difficult to block.
You can learn more about those parameters here: https://scrapingbee.com/documentation
Scraping Google
ScrapingBee offers a set of ready-made APIs. Those APIs are interesting because you don’t have to do maintain your scraper with CSS selectors / XPath selectors, they do it for you and return JSON formatted data: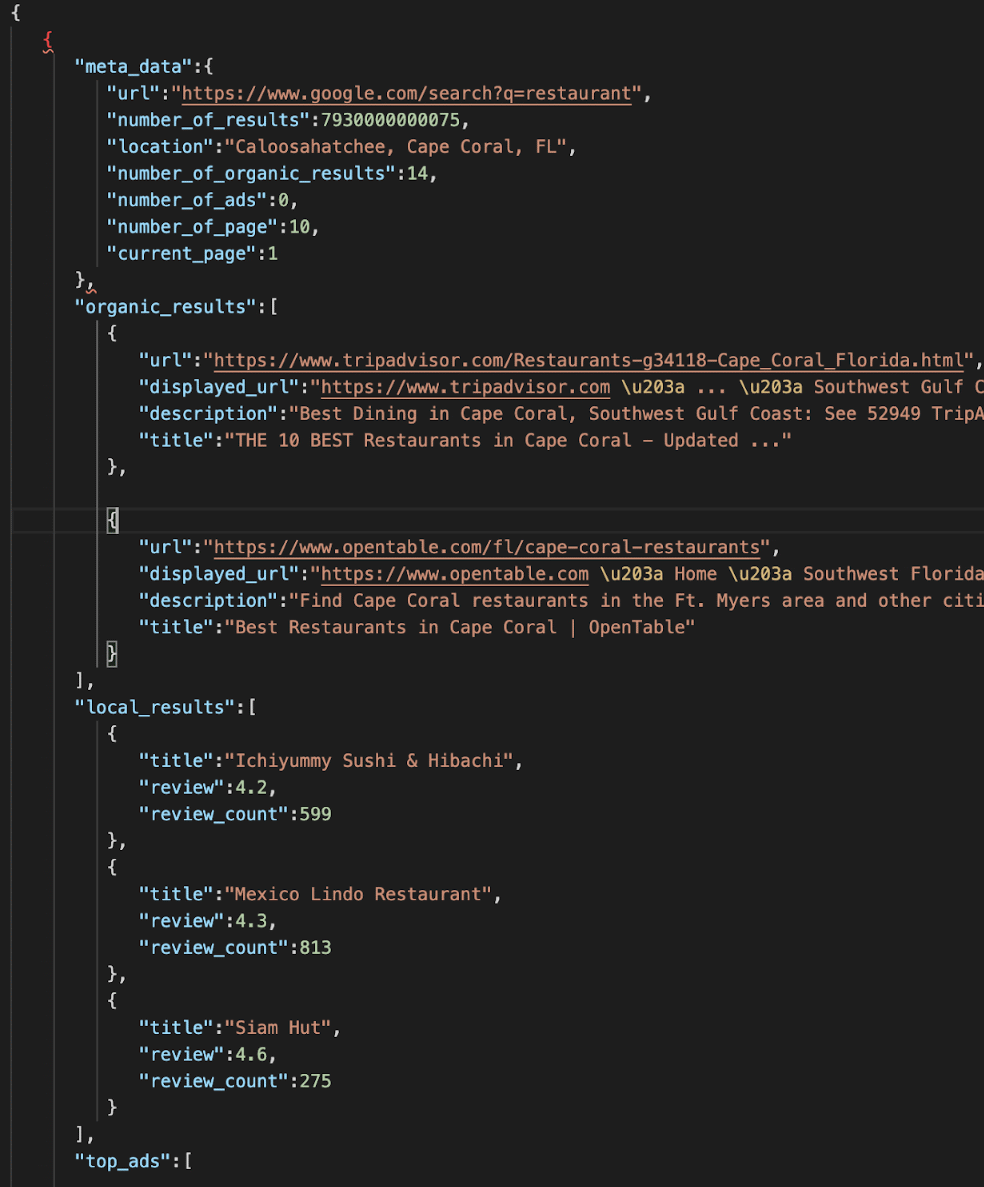 At the time of this blog post, they offer two ready-made APIs, a Google search API and an Instagram API.
At the time of this blog post, they offer two ready-made APIs, a Google search API and an Instagram API.
We are going to see how to use the Google API to perform a keyword rank tracking script.
The script will call the ScrapingBee API on a set of keywords and save the ranking and urls into a CSV file for further analysis:
(gist: https://gist.github.com/ScrapingNinjaHQ/12f14290387abbc62e4f5fd65c2455a7 )
import requests
import csv
from urllib.parse import unquote, quote, urlparse
import json
# Keyword rank monitoring on Google
# This script takes a keyword list and perform a Google search for each keyword with the ScrapingBee API:
# https://www.scrapingbee.com/api-store/google/
# It then stores the result into a CSV file
keywords = ["java web scraping"]
# Replace with your ScrapingBee API
SCRAPINGBEE_API_KEY = ""
endpoint = "https://app.scrapingbee.com/api/v1/store/google"
rows = []
for keyword in keywords:
params = {
'api_key': SCRAPINGBEE_API_KEY,
'search': keyword,
'country_code': 'us'
}
response = requests.get(endpoint, params=params)
if response.status_code != 200:
print('Error, status code: ' + str(response.status_code))
else:
json_dict = json.loads(response.content)
# we only take the first 10 results
for result in json_dict['organic_results'][:10]:
position = result['position']
url = result['url']
rows.append({'keyword': keyword, 'position': position, 'url': url})
# write the results to the CSV file
f = open('rank.csv', 'w')
with f:
fnames = ['keyword', 'position', 'url', ]
writer = csv.DictWriter(f, fieldnames=fnames)
writer.writeheader()
for row in rows:
writer.writerow(row)It will create a CSV file with all the data: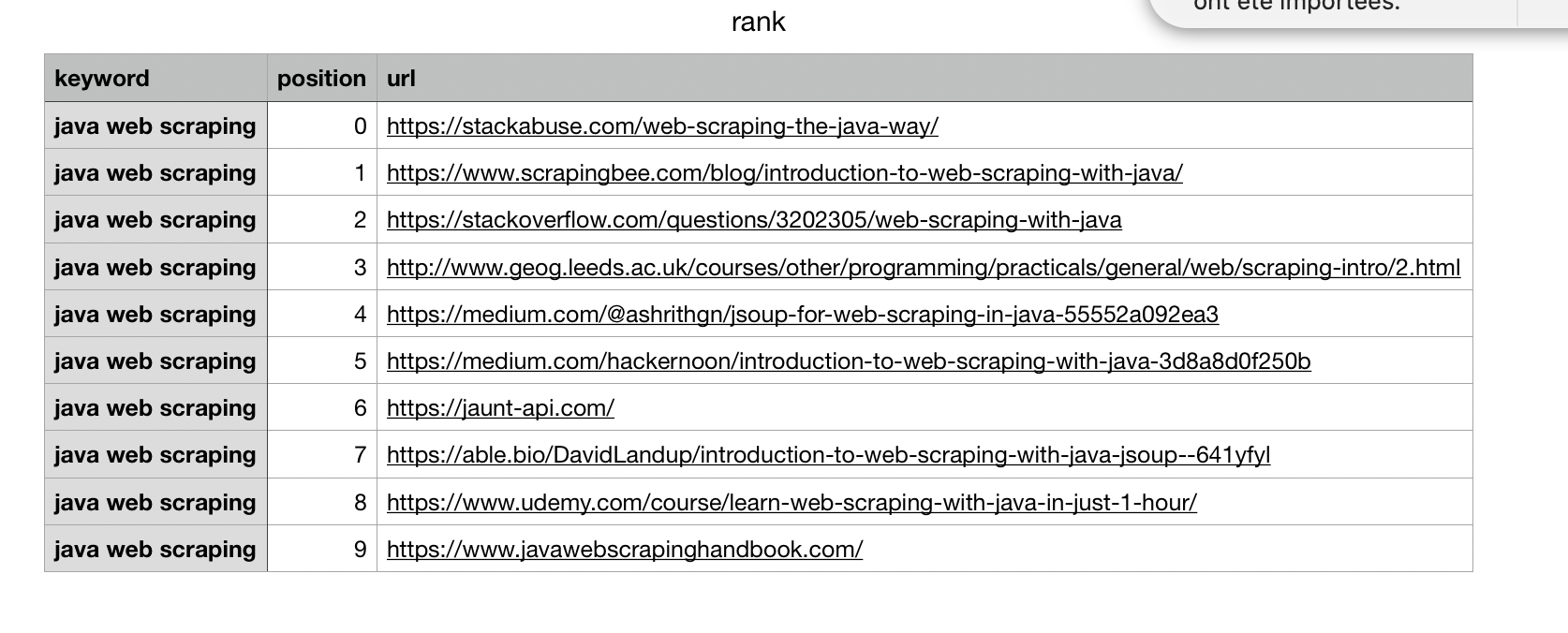
Price
- $29/mo for 250 000 credits
- $99/mo for 1 000 000 credits
- $199/mo for 2 500 000 credits
ScrapingBee is a really good choice for freelancers, small and medium businesses that don’t want to handle the web scraping infrastructure themselves.
It can greatly reduce the cost of renting the proxies yourself and/or deploying and managing headless browsers in the cloud.