WebHarvy Data Extractor is a lightweight, visual, point-to-click web scrape tool. It won’t be long before you become masterful at the generally tedious task of data extraction.
Overview
WebHarvy is best suited for quick scraping of text, URLs and images from web pages. Extracted data can be saved into common formats (CSV, TSV, XML) and also SQL for database input.
Workflow
After navigating to the target page, enable WebHarvy by using the Start Config button. Click the desired data element and the pop-up window will prompt how to process the data.
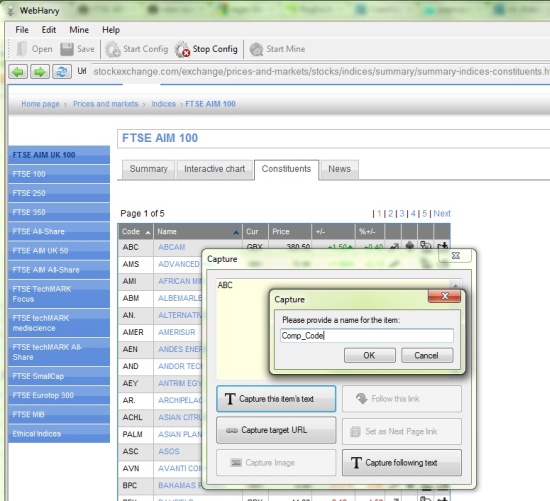
If you choose one item in the resulting column/catalog and name it, the capture algorithm will proceed to identify remaining similar data. The captured data preview is a feature that should make your job easier. It’s also quite simple to navigate to multiple pages while using the tool.
Search configurations can be saved and modified for use at a later time. For editing an existing configuration, find the Edit tab and follow the Edit Configuration item.
On to the data extraction. You’ll soon find WebHarvy a smooth and easy-to-use product. Once WebHarvy finished processing, you can export the captured data as a file (XML, CSV or TSV file) or insert it into a database by clicking the ‘Export’ button. Please note the configuration file is of XML format, so if you exported the captured data to the same XML format, it’s safe to use different file names when you save your files.

For slow-responding websites, or sites employing AJAX, there’s a ‘Page load timeout’ setting that allows you to configure as needed. Web proxying is another feature that some find useful. Multi-treating is worked out in here by running multiply versions of WebHarvy scraper as developers define.
Overview
The WebHarvy data extractor is stable and simple to use and easy to learn. It’s good for quick web scraping with several export data formats. In future versions of the product, look for a scheduling feature.