
Easy Web Extract is visual screen scraper for extracting data for business purposes. This data extractor rips desired web content (text, url, image, html) from webpages with minimum effort. Customize data export formats with its HTTP submit form, a unique feature of this screen scraper.
Overview
Easy Web Extract by Web2Mine is designed for simple and quick data extraction. This scrape tool is written using .NET technology and allows you to apply data transforming built-in scripts (C#, VB, JS). Easy Web Extract is excellent for exporting data into Excel (CSV), text, XML file, HTML formats, MS Access DB, SQL Script File, MySQL Script File, HTTP submit form and ODBC Data source. One shortcoming is that while making a scrape project, loading the URL sometimes takes a long time.
Workflow
Start a new session by creating a new project. Go to the target page through the built-in browser and define the data you want. Now, you can start to Specify Extracting Data Pattern. After clicking “Next” you can start to define the first data record, thus creating a DOM tree (see a Project tree at the upper left corner). To select an item in a record use “CTRL+Click” and by using the visual rectangle icons above the tabs, you may expand/shrink the items set of the first record.
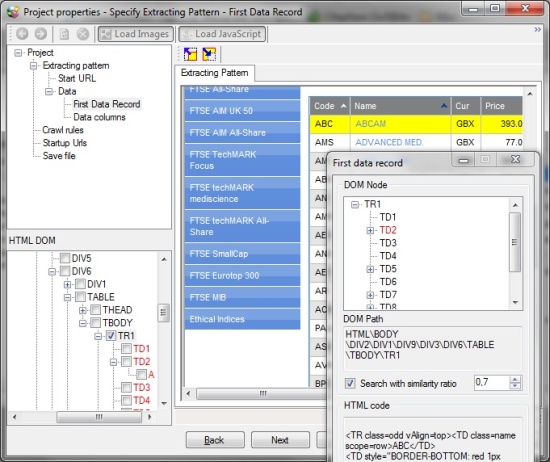
After choosing the first data record, proceed “Next” to choose Data Columns according to the record.
Again, use “CTRL+Click” to choose needed record fields to be the data columns and define them in the service window. If in a record there is a reference to details’ page, define this reference as of the “Link” type and check it as “Link to details”. Moving to the details page (“Sub page” tab), select fields needed. The visual rectangle icons will help with specifying. If you want to cut/split something in the chosen column info, invoke a transformation script.
To finish defining the data columns, follow with Crawl rules, clicking “Next”. Highlight the navigation area of the webpage (CTRL+Click) and activate navigation to multiple pages in Advance Crawling Rules in a Crawling Rule window.
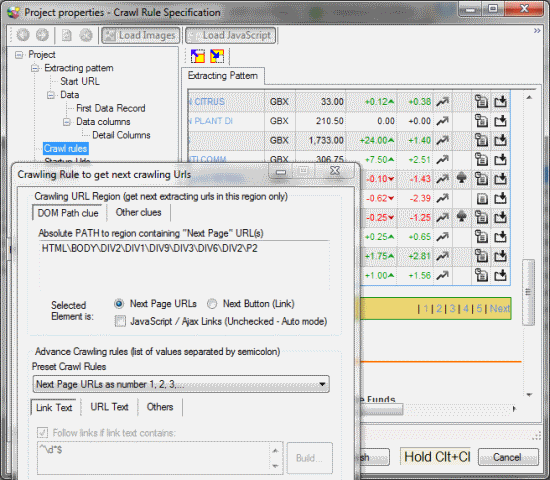
Now, proceed “Next” to confirm the target URL or choose more starting URLs (from file or a web page). Don’t be afraid to close the window; it pops-up just for multiple URL choices or confirmation.
Then, name your project and close the window. Now, the project is ready!
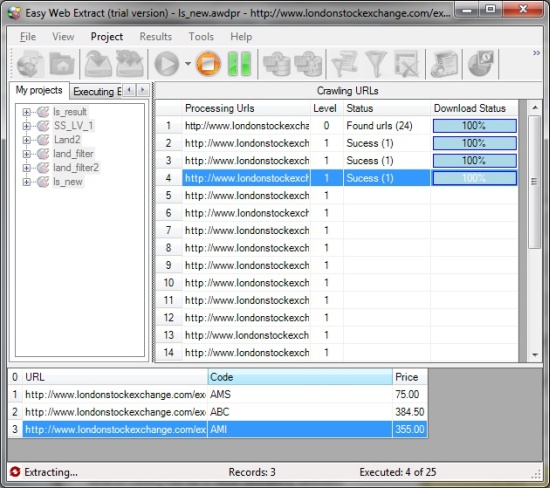
Click “Finish” and you are back to the main console. Here you can start to Automate Scraping Data. To my surprise, the data extractor allows up to 50 multi-threats, which is good for a quick scrape to run. The option to define the number of threats is in Tools – Options. If you want to edit the project after you’ve made and saved it, just follow Project – Properties.
The extracting is smooth, having a preview window.
Various export options are available. Unlike most similar scraper software, this tool doesn’t set any limitations on the data extracting in the trial version. It allows only 200 records for export though.
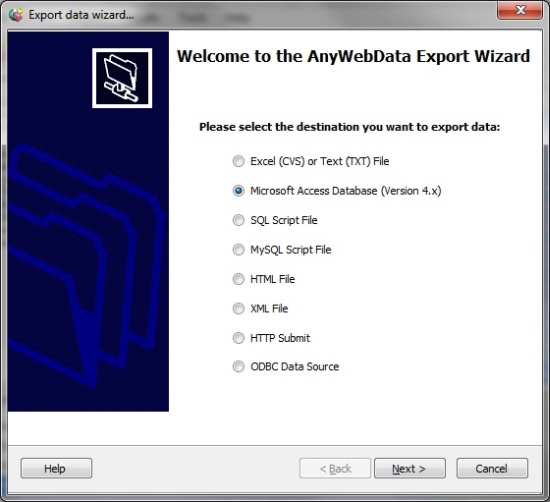
This screen scraper gives the impression of a simple tool that diligently crawls and extracts, though with some “oops” if you don’t select data fields in order. It took me some time to learn how to follow “CTRL+Click” and not to forget to define the output file name.
The current version of Easy Web Extract doesn’t support a scheduling function. However, developers plan to offer this function in the next version. As far as customer support, we asked through the submit form and within 12 hours received an answer.
Summary
The Easy Web Extract is a good tool for a simple scrape with few steps. It allows scraping details’ pages and navigation to multiple pages and it also supports scraping Ajax/JS content. The outstanding feature of this scraper is multiple formats for exporting and an HTTP submit form that works well for dynamic page content management, that is, sending data extracted directly to the destination website through an HTTP submit form.
They do provide useful videos of how to scrape Amazon, Google product pages.
One reply on “Easy Web Extract Review”
Web Scraper
I want to scrape all the data off any web site without any special parameters
And I want to run the program in batch mode, with a parameter of the URL
Can Easy Web Extract do this?
Thanks
Kerry Farmer
Dynamic Intelligence Ltd