 Web Data Extractor is a web scraping tool specifically designed for mass-gathering of various data types. The software can harvest URLs, phone and fax numbers, email addresses, as well as meta tag information and body text.
Web Data Extractor is a web scraping tool specifically designed for mass-gathering of various data types. The software can harvest URLs, phone and fax numbers, email addresses, as well as meta tag information and body text.
Overview
Web Data Extractor can be thought of as a “link extractor utility.” It works by spidering a list of URLs from a file, or by using a keyword into search engines. You can allow it to follow external links from the original pages, with the capability to go as deep into the URL paths as you need
Characteristics
| Usability |  |
|---|---|
| Functionality | |
| Easy to learn | |
| Customer support | email; |
| Price | $89 - $199 |
| Trial version/Free version | 14 days |
| OS (Specifications) | Win |
| Data Export formats | CSV |
| Multi-thread | yes |
| API | no |
| Scheduling | no |
Workflow
Get started in a new session by defining the search parameters.
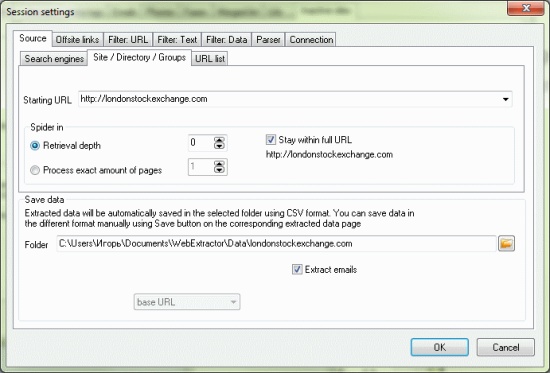 The geographical area you want to search is configurable (see Search Engines).
The geographical area you want to search is configurable (see Search Engines).
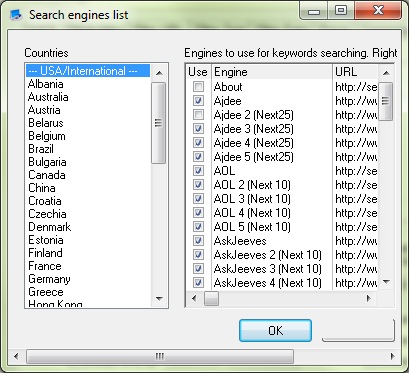 The program queries search engines using your desired keywords, fetches the matching URLs, removes duplicate URLs and searches through the links to extract specific data.
The program queries search engines using your desired keywords, fetches the matching URLs, removes duplicate URLs and searches through the links to extract specific data.
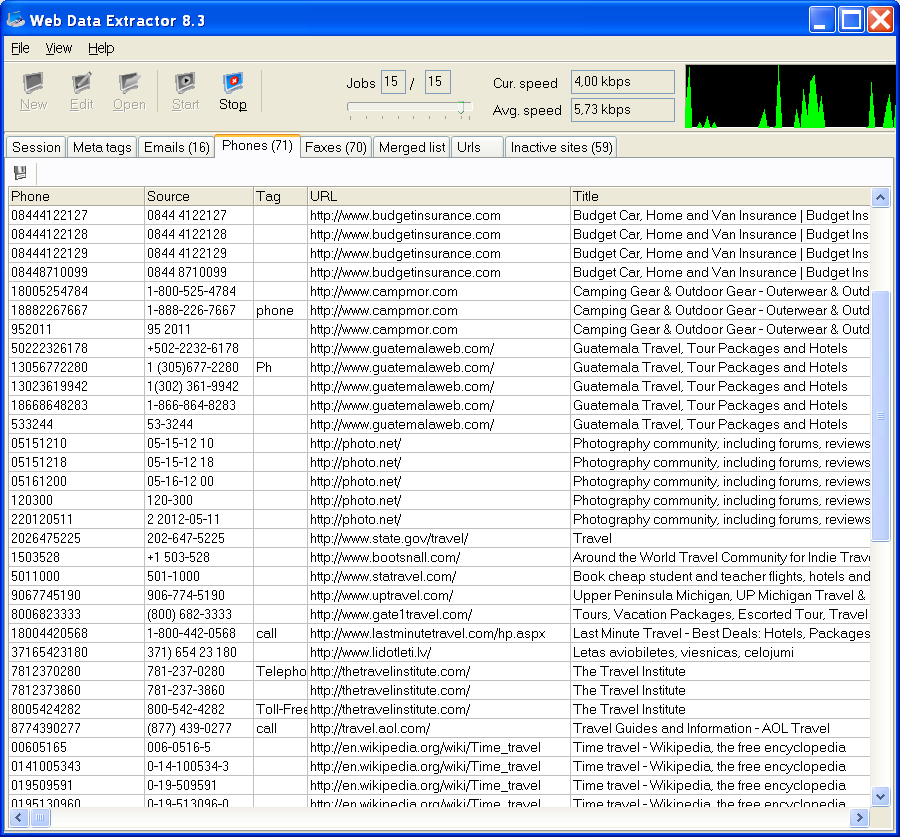
Web Data Extractor is powerful. You can use it to follow external sites with unlimited looping by utilizing the Unlimited feature within the External URLs Loop configuration. By using this feature, you can essentially search the entire Internet. While the scraper spiders and rips the entire web you manually need to stop it. Thus Web Data Extraction allows user-selectable recursion.
There are also various filters available to help get the data you want:
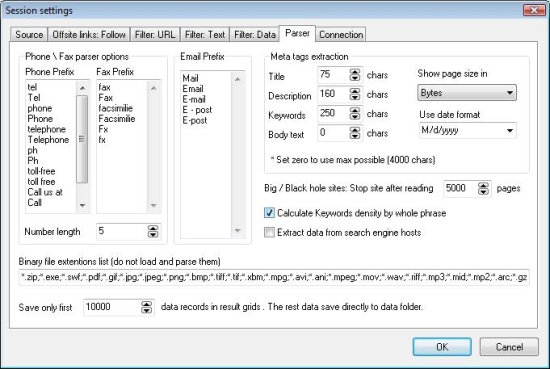
The trial version of Web Data Extractor 8.3 doesn’t support the “save format” or “save session” features. Web Data Extractor also allows web proxying for those who need it. As we requested support shortly soon (within 12 hours) an answer was given.
Note: As the Web Data Extractor was scraping I searched something else in Google and… oops, Google prompted a CAPTCHA to check if it’s my requests were a bot. This is somewhat unpleasant, especially since the developers claim the data extractor can process thousands of sites and gigabytes of data. This leads me to believe you’re better off using a scraping service online, instead of having your IP address banned.
Summary
Web Data Extractor is superior for searching through multiple layers of websites and harvesting specific link data types related to the keywords you provide. Not to say this data extractor is not focused for scraping data catalogs, rather it gathers exceptional amounts of links (i.e. company contact data) for responsible b2b communication.
2 replies on “Web Data Extractor Review”
hi
i am doing a research on forums so can you plz send me a demo to test it on my research
thanks in advance
Please, turn to the software developers.