Web scraping, also known as crawling, involves retrieving data from external websites by downloading their HTML and extracting relevant information.
Below is a quick summary of common protections covered in the post and how to counter them:
| Protection | Solution |
|---|---|
| IP Blocking | Use rotating or residential proxies |
| Browser Fingerprinting | Use stealth browsers with spoofed fingerprints |
| Behavioral Analysis | Randomize timing and simulate mouse movements |
| Rate Limiting | Respect limits and scrape during off-peak hours |
| CAPTCHA | Use solving services like 2Captcha |
| TLS Fingerprinting | Adjust TLS settings to match common browsers |
| Honeypots | Avoid invisible or irrelevant links |
| Geo-blocking | Use location-specific proxies |
| JavaScript Challenges | Use tools like ScrapingBee or Playwright |
This guide will walk you through the most common anti-bot techniques and how to bypass them effectively.
Table of contents
- 1. Use and Rotate Proxies
- 2. Leverage Headless Browsers
- 3. Defeat Browser Fingerprinting
- 4. Understand TLS Fingerprinting
- 5. Customize Request Headers and User Agents
- 6. Handle CAPTCHAs Automatically
- 7. Randomize Your Scraping Speed
- 8. Respect Rate Limits and Server Load
- 9. Match Your Location to the Target Audience
- 10. Simulate Mouse Movements
- 11. Scrape Hidden APIs Instead of HTML
- 12. Avoid Honeypot Traps
- 13. Use Google’s Cached Pages
- 14. Route Traffic Through Tor
- 15. Reverse Engineer Anti-Bot Systems
Effective Strategies to Prevent Scraping Blocks
1. Use and Rotate Proxies
Making too many requests from the same IP address is a fast track to getting banned. Proxies let you route traffic through different IP addresses, making your activity appear to come from multiple locations. Choosing reliable [rotating] residential proxies.
Rotate IPs Regularly
Static IP usage creates patterns that websites can detect. By rotating through a pool of IPs—especially with services like ScrapingBee—you reduce the risk of being flagged. While datacenter proxies work for basic scraping, high-security sites may require more advanced solutions.
Choose Residential or Mobile Proxies
Residential proxies use real ISP-assigned IP addresses from home networks, making them far less likely to be blocked. Mobile proxies (3G/4G) go a step further, mimicking smartphone users—perfect for mobile-first sites. See what is better than residential proxies for web scraping?
Build Your Own Proxy Infrastructure
Tools like CloudProxy let you set up custom proxy servers on AWS or Google Cloud. Though hosted in data centers, these can be configured to blend in better than generic proxies.
Use Reliable Proxy Management Services
Free proxies are slow and often blacklisted. Paid services like Decodo Scrapoxy offer better performance and uptime. Managing your proxy network efficiently is crucial for long-term scraping success. See
2. Leverage Headless Browsers
Many modern websites load content dynamically with JavaScript. Simple HTTP requests won’t capture this data. Headless browsers render pages just like real browsers but run in the background without a GUI. Headless Chrome detection and anti-detection
How Headless Browsers Work
These tools simulate full browser environments, executing JavaScript, handling cookies, managing sessions, and rendering complex layouts. They’re ideal for scraping SPAs (Single Page Applications) and AJAX-driven content.
Camoufox – The Stealth Firefox for Scraping
Camoufox is a modified version of Firefox designed to evade bot detection. With built-in fingerprint spoofing and compatibility with Playwright, it’s one of the best tools for bypassing systems like CreepJS. Learn more in our Camoufox tutorial.
Selenium – The Classic Automation Tool
Selenium supports multiple browsers and offers deep control over automation. For enhanced stealth, try undetected_chromedriver or its successor, Nodriver.
Playwright – Fast and Flexible
Developed by Microsoft, Playwright supports Chromium, WebKit, and Firefox with excellent JavaScript handling and automation features.
Puppeteer – Chrome Automation for Node.js
Puppeteer gives fine-grained control over Chrome/Chromium. Boost its stealth with Puppeteer Stealth and rotating proxies. See Puppeteer Stealth to prevent detection
Cloudscraper – Bypass Cloudflare
This Python library helps bypass Cloudflare’s anti-bot protections. See the ScrapingBee guide on scraping JavaScript-heavy sites.
Nodriver – WebDriver-Free Automation
Nodriver offers high-speed automation without relying on traditional drivers, reducing detection risks.
While these tools work locally, scaling them requires significant resources. For large-scale scraping, a managed solution like Web API is more efficient. https://webscraping.pro/sequentum-cloud-vs-unblockers-for-hard-tough-protected-site/
3. Defeat Browser Fingerprinting
Websites can identify bots by analyzing subtle browser behaviors—like how fonts are rendered or how JavaScript APIs respond. This is called browser fingerprinting.
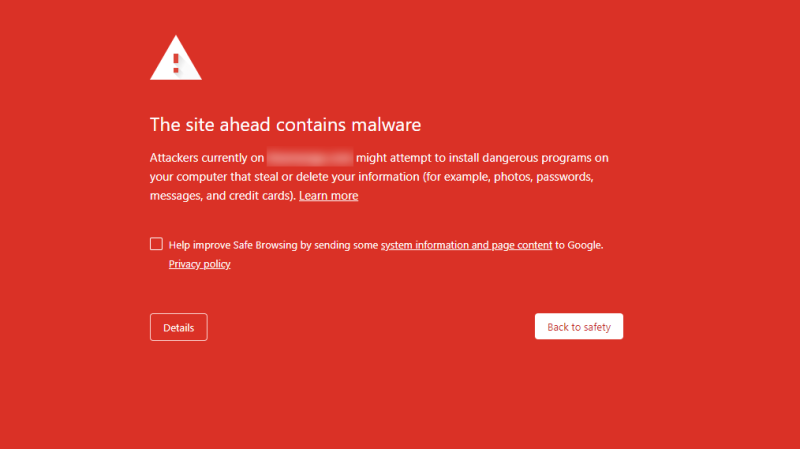
Chrome detecting automated behavior
Interestingly, scrapers benefit from efforts made by browser vendors to prevent malware from detecting headless environments. These improvements make it harder for sites to distinguish real users from bots.
However, running many headless Chrome instances consumes a lot of memory, limiting scalability.
4. Understand TLS Fingerprinting
TLS (Transport Layer Security) secures HTTPS connections. During the handshake, each client sends configuration details—like supported cipher suites and extensions—that form a unique TLS fingerprint.
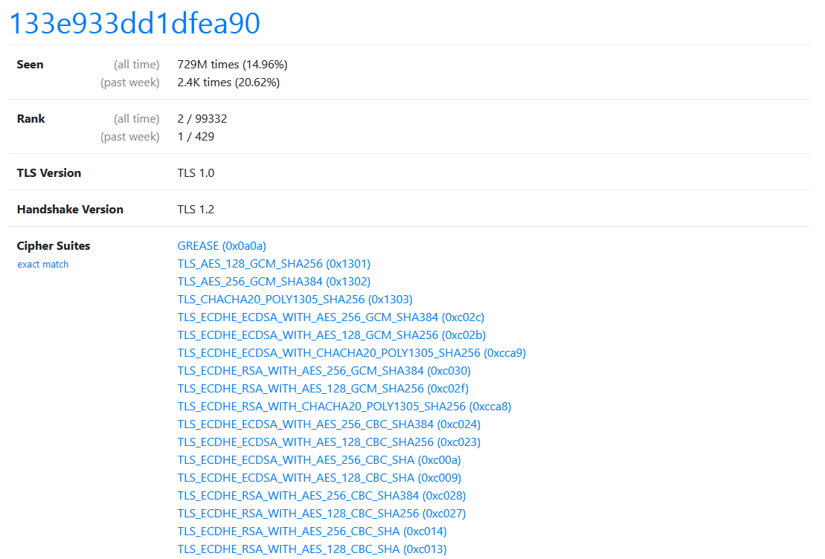
TLS fingerprint of Safari on iOS
Unlike browser fingerprints, TLS fingerprints rely on fewer data points, making them easier to track. Common ones (like Safari’s) are widely recognized; unusual ones raise red flags.
Can You Change Your TLS Fingerprint?
It’s difficult because most libraries (like Python’s requests) don’t allow manual TLS configuration. You’d need to modify low-level settings via tools like HTTPAdapter or use system-level SSL libraries like OpenSSL.
Check out ScrapingBee’s guides on adjusting TLS settings in Python, Node.js, and Ruby.
5. Customize Request Headers and User Agents
Every HTTP request includes headers. The User-Agent header tells the server which browser and OS you’re using. Default values (like cURL’s) are easily flagged.
Why Rotate User Agents?
To avoid detection: – Use real browser user agents (e.g., latest Chrome or Firefox). – Update them regularly to avoid outdated versions. – Rotate between multiple agents to prevent pattern recognition. Libraries like Fake-Useragent (Python), Faker (Ruby), or User Agents (JS) can generate realistic strings automatically. Read on User-Agents by browsers.
Other Important Headers
For more natural-looking requests, set:
– Referer: Simulates coming from another page.
– Accept-Language: Matches regional language preferences.
See an example with cURL using those headers:
curl -H "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36" \
-H "Referer: https://google.com" \
https://example.com
6. Handle CAPTCHAs Automatically
Even with proxies, you might face CAPTCHAs—tests designed to stop bots. reCAPTCHA v2, v3 (the “I’m not a robot” checkbox) are common.
Modern reCAPTCHA challenge
Simple CAPTCHAs can be solved with OCR, but complex ones need human input. Services like 2Captcha and Death by Captcha use real people to solve them for a small fee.
Learn more in our guide: 8 best Captcha Solvers.
7. Randomize Your Scraping Speed
Requesting pages every second is a dead giveaway. Real users browse irregularly.
Instead: – Shuffle the order of URLs you visit. – Add random delays (e.g., 1–10 seconds). – Occasionally “browse” unrelated pages or pause longer. This mimics natural behavior and reduces detection risk.
8. Respect Rate Limits and Server Load
Overloading a server is unethical and risky. Watch for signs of throttling—slower responses or HTTP 429 errors.
How to Find Rate Limits
- Check the site’s
robots.txtor API docs. - Look for headers like
RateLimit-RemainingorRetry-After. - Gradually increase request frequency until errors occur.
- Contact the site owner if unsure.
Use exponential backoff when blocked, and scrape during off-peak hours (e.g., midnight local time).
9. Match Your Location to the Target Audience
Scraping a France service from a U.S. IP looks suspicious. Use geolocated proxies that match the site’s primary user base.
Also consider:
– Local browsing habits (peak times, language).
– Geo-blocking techniques used by the site. This helps your traffic blend in with genuine users.
10. Simulate Mouse Movements
Some sites track cursor behavior. Bots rarely move the mouse; humans do. Using tools like Selenium, you can simulate random mouse movements and hover actions to appear more authentic.
This also helps trigger content that only loads on hover or scroll.
11. Scrape Hidden APIs Instead of HTML
Many sites fetch data via internal APIs. These return clean JSON and are often easier to scrape than rendered HTML.
How to Reverse-Engineer an API
- Open browser DevTools (Network tab).
- Perform an action (e.g., “Load more comments”).
- Find the XHR/fetch request and inspect its headers and parameters.
- Replicate it in your code.
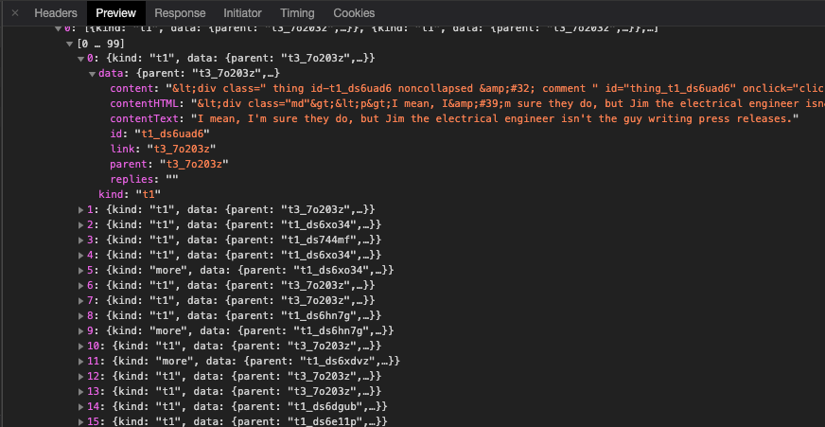
Inspecting API responses
Export requests as HAR files and test them in tools like Postman or Paw.
Analyzing requests in Paw
Mobile App APIs
Reverse-engineering mobile apps is harder due to encryption and obfuscation. Use MITM proxies like Charles Proxy, but beware of hidden security layers (e.g., Starbucks’ encrypted API).
12. Avoid Honeypot Traps
Some sites hide invisible links (display: none, left: -9999px) to catch bots. Any scraper that follows them is flagged.
To avoid traps:
- Ignore links not visible in the DOM.
- Skip links with background-matching colors.
- Stick to relevant navigation paths.
- Follow
robots.txtguidelines. - Regularly audit your scraper to ensure it doesn’t fall for decoys.
13. Use Google’s Cached Pages
For static or infrequently updated content, try scraping Google’s cached version:
https://webcache.googleusercontent.com/search?q=cache:https://example.com/Pros:
– Bypasses some anti-bot systems.
– Accessible even if the site blocks your IP.
Cons:
– Data may be outdated.
– Not all sites allow caching (e.g., LinkedIn).
Always check legal and ethical boundaries before scraping cached content.
14. Route Traffic Through Tor
The Tor network anonymizes your connection by routing it through multiple relays. It changes your IP every ~10 minutes.
But:
– Tor exit nodes are publicly listed and often blocked.
– Speed is slow due to multi-hop routing.
Tor browser is best used in combination with other methods, and only when necessary for privacy.
15. Reverse Engineer Anti-Bot Systems
Advanced sites use behavioral analysis, fingerprinting, and JavaScript challenges to detect bots. To beat them:
- Analyze the site’s JavaScript for bot-detection logic.
- Compare your scraper’s network traffic with a real browser.
- Test which headers or behaviors trigger blocks.
- Study when and why CAPTCHAs appear.
Final
Web scraping isn’t just about extracting data — it’s about doing so intelligently and ethically. The key is to blend in, respect server limits, and adapt to evolving defenses.
Also check out Scraping software & services landscape