![]() Clustering is a data mining process where data are viewed as points in a multidimensional space. Points that are “close” in this space are assigned to the same cluster. The clusters themselves are summarized by providing the centroid (central point) of the cluster group, and the average distance from the centroid to the points in the cluster. These cluster summaries are the summary of the entire data set. Having assigned sets of data in clusters, data mining techniques directly process a large amount of data with much greater computation effectiveness.
Clustering is a data mining process where data are viewed as points in a multidimensional space. Points that are “close” in this space are assigned to the same cluster. The clusters themselves are summarized by providing the centroid (central point) of the cluster group, and the average distance from the centroid to the points in the cluster. These cluster summaries are the summary of the entire data set. Having assigned sets of data in clusters, data mining techniques directly process a large amount of data with much greater computation effectiveness.
Ideally, points in the same cluster have small distances between them, while points in different clusters have large distances between them.
An illustration using social nets representation and their contribution to incoming web traffic is shown in next figure.
Figure A: Plotting the social networks on Visits / Pages per visit dimensions.
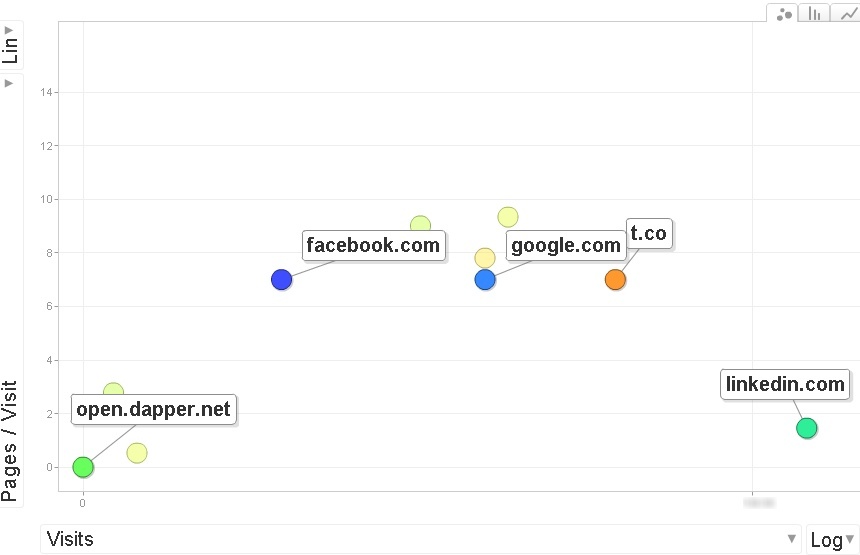
We can see just by looking at the diagram that the social nets fall into three clusters. The networks clustered disclose some common features. While the ‘Linkedin’ network is ahead in number of visits, the networks in the middle of the figure exhibit better pages per visit behavior. With small amounts of data, any clustering algorithm will establish the clusters, and simply plotting the points and “eyeballing” the plot will suffice as well.
Clustering formations algorithms
Clustering algorithms are clustered (!) into two groups that follow two fundamentally different strategies.
- Hierarchical algorithms start with each point as its own cluster. Clusters are combined based on their “closeness”, using one of many possible definitions of “close”. Merging clusters together stops when further combination leads to clusters that are ineffective for one or several parameters.
- The other class of algorithms are based on point assignment. Points are considered in some order, and each one is assigned to the cluster into which it best fits. Variations allow occasional combining or splitting of clusters, or may allow points to be unassigned if they are too far from any of the current clusters.
Algorithms for large amounts of data often take shortcuts, since it is not feasible to pass thru all pairs of points. For example, with 1,000,000 points the computation degree will be over a half a trillion operations.
The algorithms differ depending on the data model, whether static with no point added in the future, or dynamic where more data are to be worked with. The latter does require more flexibility because of cluster features needing to be re-calculated.
More reading on clustering algorithms may be found here (starting from section 7.1.2 “Clustering Strategies”).
Euclidean space in clustering
An N-dimensional Euclidean space is one where points are vectors of N real numbers. The conventional distance measure (d) in the space is defined:
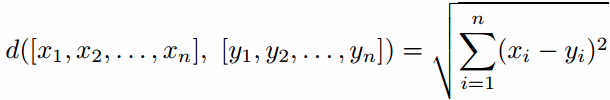
In a Euclidean space it is possible to summarize a collection of points by their centroid – the average of the points.
In a non-Euclidean space, there is no notion of a centroid, and we are forced to develop another way to summarize clusters (ex. one or several representatives of a cluster). Consider the summarizing of books by categories based on the frequency of similar words in their titles.
Some problems if clustering in non-Euclidean spaces
Representing a cluster in any non-Euclidean space is an issue, because we cannot replace a collection of points by their centroid. Therefore the algorithms to be applied to the data in this space are more sophisticated.
Given the example with social nets contributing into target web traffic, the dimensions are clear ‘visits’ and ‘pages per visit’, numeric. Yet the clustering might be done with other non-numerical parameters as: how the posts/ads in those nets are inserted, or the difficulty-degree/man-power of putting backlinks in those nets and others.
The big challenge is to cluster documents by their topic, based on the occurrence of common but unusual words in the documents. It is also challenging to cluster moviegoers by the type or types of movies they like.
Given that we cannot combine points in a cluster when the space is non-Euclidean, our only choice is to pick one of the points of the cluster itself to represent the cluster. Ideally, this point is close to all the points of the cluster, so it in some sense lies in the “center”. The representative point is called the clustroid. Applying to moviegoers we might define as a clustroid the people who like a certain movie (cannot be called “central movie”) that has a least “non-Euclidean distance” to other movies in cluster.
Here we have briefly touched on the clustering problem in data mining, so in the future we’ll post on the algorithms and methods for clustering as well as data mining frameworks. For more reading on clustering go to the Mining of massive data sets book.