Nowadays, when one has some questions, it comes almost naturally for us to just type it in a search bar and get helpful answers. But we rarely wonder how all that information is available and how it appears as soon as we start typing. Search engines provide easy access to information, but web crawling and scraping tools, which are not such well-known players, have a crucial role in wrapping up online content.
Over the years, these tools have become true game-changers in many businesses including e-commerce. So, if you are still unfamiliar with them, keep reading to learn more.

What are web crawling and web scraping tools?
Web crawlers and web scrapers have many other names, such as spiders, bots, robots, etc., which all pretty much sum up what they do – extract content and data from a website. This process allows companies to obtain all publicly available information from any website. But our attention here will be mostly on data extraction in eCommerce.
This is an automated process in which a query is sent to a requested page, then the robot combs through the HTML for specific items. If the process wasn’t automated, it would be so time-consuming to perform this task that the results would be questionable. With this automation, you are able to gather all the data in bulk and display it in a table format.
However, it is important to note that some of the main challenges when using these tools can be banning, very complex sites that are difficult to crawl, and so on.
Web crawling and data extraction in the early days
This crawling process has been present from before the time that search engines were developed as a way to make web pages searchable. It all started as a process of finding out how websites are connected with each other and to calculate the page rank index. These tools were also used for checking if the website works properly and spotting any issues interfering with that.
Back in time, web sites consisted mainly of HTML code, so scraping was a project that could be done by almost every developer. Nowadays, web pages have a significantly more complex structure, which means that these tasks must be done by the whole team or by companies that have developed data extraction tools (e.g. Price2Spy) that are more able to respond to the demand of a complicated business environment.
Finishing all those daunting tasks nowadays wouldn’t be possible without using the right tools. By using web scraping tools, companies can be more agile and versatile when thinking about making further steps in their business strategy. Therefore, having the extracted product data is one of the biggest aspects of a company’s success.
Changing the needed data types
With the rise of new online platforms and the development of e-commerce, the types of data that companies need have also changed. The new forms of data, such as the ones coming from social media, are presented in graphs, videos, pictures, or audio. Companies now want to have an insight into competitor product assortment so that they are able to enrich their own offer and content in general. Besides the data extracted from eCommerce websites, there are also new forms of data, such as the one coming from social media, are presented in graphs, video, picture, or audio. These data need to be collected and sorted in a format that is suitable for further analysis.
This complexity means that you need to gather the data coming from different sources, which brings us to another problem – data duplication. Duplicating data is a very serious problem that must be taken into consideration when conducting your SEO strategy. All the duplicate content will be recognized and penalized by Google – so if you are not producing brand new content, then moderate changes in the product name and description must be made. Besides the written part of the content, images can also be subject to copyrighting. In case you are using scraping services for more than one site, it is vital that there are no inconsistencies.
The change in the web scraping environment – DaaS
As we have already mentioned, the web scraping environment has come a long way from what it was a few years ago. Today, the nature of web scraping services consists of so much more than just gathering the text from web pages.
So, if you manage to successfully overcome all the above-mentioned obstacles (such as data type variety and data duplication), you may come across a new one, which is where all that scraped data is being stored. The most common solution is DaaS (Data as a Service), which represents a form in which the data is offered and where you can have it delivered in a form and method that is most suitable for your company’s needs.
In that way, you don’t need to worry about aspects like maintenance or the modifications required if the website you need to crawl or scrape undergoes some changes. All those aspects are already taken into consideration when defining the service price, so you are paying only for the data that you use, and nothing more. There are many services that you can use for this purpose, but we will come to that in a few lines below.
Crawling vs Scraping?
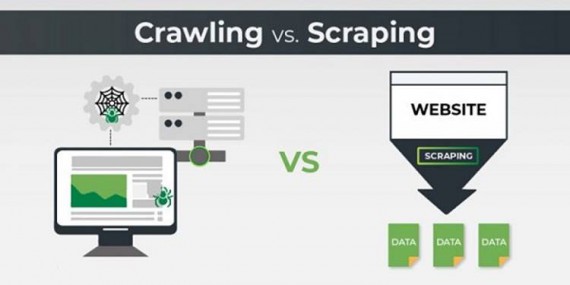
Now that you are more familiar with this process, it is important to dig a little bit more into details. Even though they might seem like similar terms, there are some important differences between web scraping and web crawling that need to be addressed. Web crawlers collect information such as the URL of the website, the meta tag information, the links in a web page, and other relevant information.
They keep track of the URLs which have already been downloaded in order to prevent downloading the same page again. However, web scraping works differently, or to say, more precisely. While the crawler visits all the found links, the scraper goes to the web page by a definite link, and collects only the needed data (which will again differ depending on what your main aim is). For example, companies can get any data that they need from a competitor’s website. Some of the things that they would be able to get from a scrape are:
- product name and URL
- product description,
- product category,
- product price,
- product image,
- brand information,
- stock levels, etc.
The list doesn’t end here. By doing data extraction, it is possible to get contact information, reviews, or any data that is publicly available.
Conclusion
One of the hardest tasks for companies is to collect and analyze the data they’d need for their business. Therefore, it is no surprise that web crawling and scraping tools have become so widely popular. Web scraping provides valuable data to companies, whether they are big or small ones, an online retailer, brand or distributor.
It’s becoming an essential part of e-commerce businesses gaining insight that will help companies develop good strategies. With it, they’ll be able to create better offers, be more competitive, understand the market and most importantly make better business decisions.