![]() Today I want to share my experience with Dexi Pipes. Pipes is a new kind of robot introduced by Dexi.io to integrate web data extraction and web data processing into a single seamless workflow. The main focus of the testing is to show how Dexi might leverage multi-threaded jobs for extraction of data from a retail website.
Today I want to share my experience with Dexi Pipes. Pipes is a new kind of robot introduced by Dexi.io to integrate web data extraction and web data processing into a single seamless workflow. The main focus of the testing is to show how Dexi might leverage multi-threaded jobs for extraction of data from a retail website.
NB Pipes robots are available starting from PROFESSIONAL plans.
I heard some of the Dexi.io developers talking about Pipes so I decided to try it out against AliExpress (a retail website). For my test I pulled some thousands 🙂 of products from AliExpress.
Pipes, being a robot, requires robotic configuration: a project tree in this case. Basically each Dexi.io user must design his own Pipes project. I originally made my own configuration consisting of a crawler gathering random links to product pages followed by an extractor harvesting data from the product pages. It turned out to be time inefficient and error prone. To overcome these shortages, I turned to an advanced design.
A Crawler is able to collect any data from static HTML but only Extractors can handle dynamic content, filling in forms, downloading images, etc.
The advanced design scheme, proposed by Dexi tech support included two Extractor robots. The first one gathering category links and the second getting data from the links.
To do the advanced testing I made the workflow scheme and chose 3 category urls:
- Dresses (3000 items*)
- Clock-parts-accessories (4000 items*)
- USB flash drives (over 40000 items*)
*The numbers above are approximate.
Scheme:

This robot will iterate over pages and loop through elements to gather all product urls of each of the 3 categories.
As soon as this robot finishes its work on one input category, its output (product_urls) will become the input of the second robot extracting information. Thus the parallel processing is worked out.
For the first robot inputs we’ve created a Data set (see here how to do it) and filled it with those selected category urls.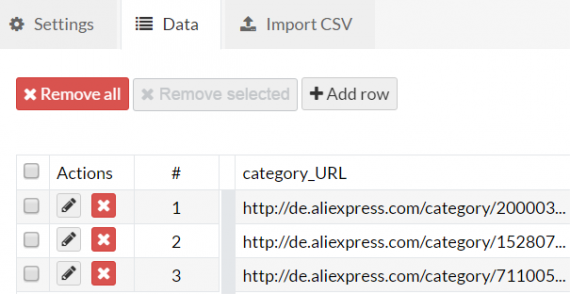
The second robot is quite straightforward. It works to extract product data from a single product page: item, image, title and price. The Robot 2’s inputs depend on Robot 1’s outputs.
Scheme:

This Pipes robot integrates the two Extractor robots (Robot 1 and Robot 2) into one binding.
Scheme:

Dexi restricts the number of robots that an individual user is permitted to run. The robots running at a certain point in time are called workers. The free plan limits you to only 2 workers (simultaneously running robots). You pay monthly for each additional worker. This test project required 3 workers: one for the first Extraction robot, one for the second Extraction robot and the one for the Pipes robot!
Because the Pipes robot incorporates both Robot 1 and Robot 2, you only need to monitor the Pipes robot. The Pipes robot does everything. The Pipes robot gets the outputs from Robot 1, passes them as inputs to Robot 2 and then starts Robot 2. The Pipes robot is responsible for balancing tasks between available workers. See the picture below, it shows Active and Completed executions. We see four workers actively working: two of them as Robot 1 and two of them as Robot 2.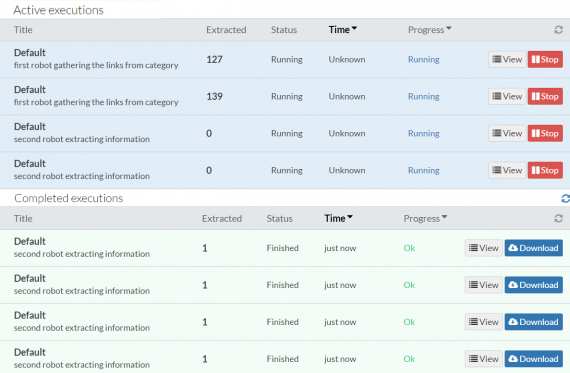
 By monitoring the Pipes robot we can see that they worked properly. From the Executions panel of our run we can see that most of the time 3 workers are fully occupied. The executions monitoring window has little bit of a delay between what is actually happening on the server and what it shows, so you won’t always see 2 or 3 running executions.
By monitoring the Pipes robot we can see that they worked properly. From the Executions panel of our run we can see that most of the time 3 workers are fully occupied. The executions monitoring window has little bit of a delay between what is actually happening on the server and what it shows, so you won’t always see 2 or 3 running executions.
My test resulted in the Pipes robot gathering over 64K product items (title, price, image).
My first attempt with the simple Pipes config, not described here, resulted in 1.05 rows/minute while with the advanced Pipes I achieved 3.8 rows/minute – the advanced config was more than 3 times more effective.
Some may argue that 3 records/min is not a high speed. Yet, you should realize that the Dexi.io cloud scraping engine works as a full-scale browser. It performs a request to the server of the website and loads all of the webpage’s files like CSS, JS, Fonts, etc. along with mainframe HTML files. This way the performance gets drastically low compared to HTML load scrapers. Yet this scraper behavior prevents the Dexi scraper from being blocked by target servers. See the post on how web services might detect web scraping.
It is possible to increase scraping speed by blocking certain unnecessary network requests for a particular robot. Thus to exclude eg. weighty images loads or similar.
The main advantage of the advanced Pipe config is that if you have three workers available then the robot that actually extracts information (Robot 2) can start its work immediately after Robot 1 has extracted the very first product URL. If you have only 2 workers available, you need to wait until the first Extractor finishes.
I had a question for the support: What if I use my previous execution results [eg. of a first robot] in a new Pipes execution to not extract them twice?
Answer: Pipe would run the crawler from scratch again, robots don’t keep state history that could be reused at a later moment.
My test ran into some problems with proxies. Dexi Support told me that they had found “some problems, as it seems that all original DE proxies were flagged”. Therefore we had to force my robots to use US proxies instead. This happened after tens of thousands of requests were made. See the image below to see how you can change proxies’ for your run:
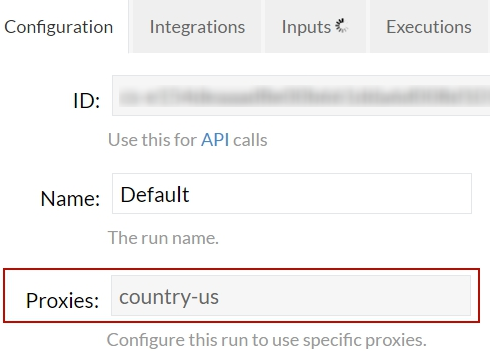
Note proxies can only be changed when robot is not running!
The testing of the advanced Pipes robots configuration has been a new thing to me. While performing the test, I regularly asked questions of Dexi support and they were very responsive with assistance. Through this test I learned a couple of important new things about both the robots and workers:
- Create a Pipes configuration that best fits the multi-threading nature of data scrape.
- Regardless of how good your project tree is (advanced Pipes config), you are limited by the number of simultaneous executions that you can run, which is determined by the number of workers that your plan contains.
- Setting a robot to not make certain kinds of requests (eg. for images) while leaving other non-bandwidth consuming requests turned on improves the speed of the execution while enabling a full-browser extraction.
The importance of parallel work is evident as the amount of web data grows rapidly. The main goal of the advanced testing was multi-threading executions. So Dexi.io has proven that it is stable for parallel executions.