![]() Web Content Extractor is a visual user-oriented tool that scrapes typical pages. Its simplicity makes for a quick start up in data ripping.
Web Content Extractor is a visual user-oriented tool that scrapes typical pages. Its simplicity makes for a quick start up in data ripping.
Overview
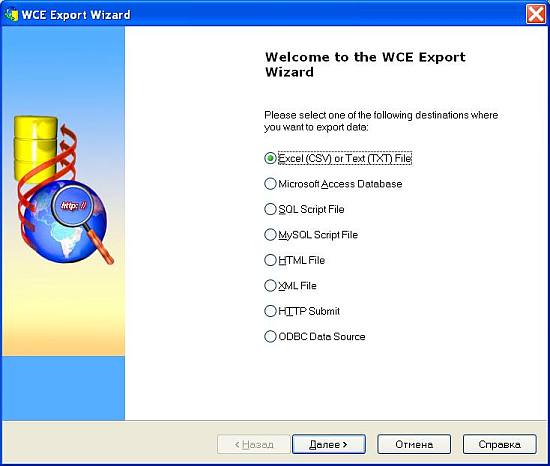
Web Content Extractor (WCE) is a simple user-oriented application that scrapes web pages and parses data from them. This program is easy to use, but it gives you the ability to save every single project for future (daily) use. The trial version will work with only 150 records per scrape project. As far as exporting and putting data into different formats, Web Content Extractor is excellent for grouping data into Excel, text, HTML formats, MS Access DB, SQL Script File, MySQL Script File, XML file, HTTP submit form and ODBC Data source. Being a simple and user friendly application, it steadily grows in practical functionality for complex scrape cases.
Workflow
Let’s see how to scrape data from londonstockexchange.com using Web Content Extractor. First, you need to open the starting page in the internal browser:
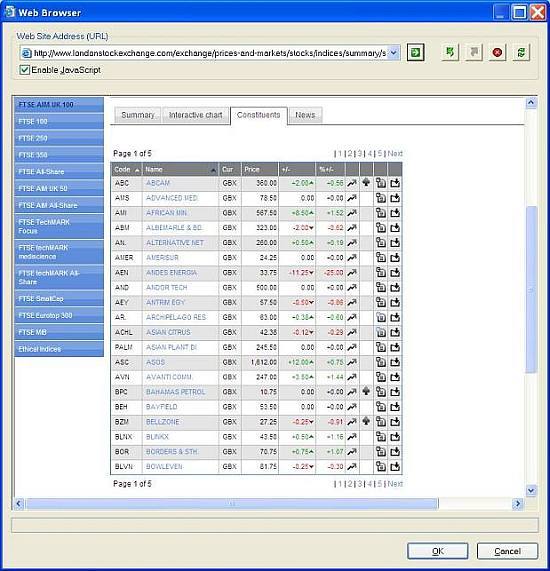
Then, you need to define “crawling rules” in order to iterate through all the records in the stock table:
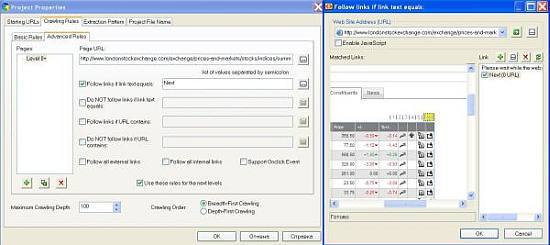
Also, as you need to process all the pages, set the scraper to follow the “Next” link on every page:
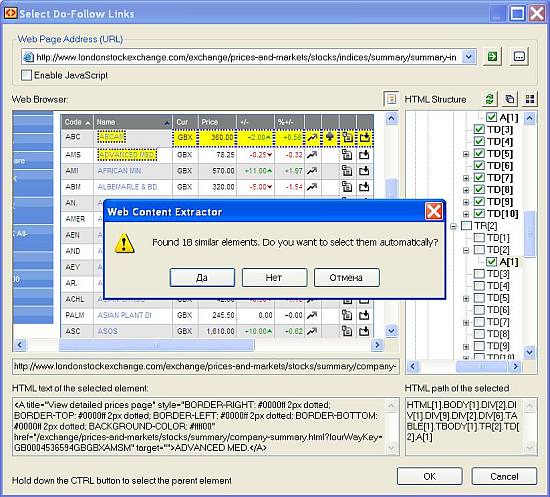
After that, drill down into each stock table row and extract information from the “Summary” section. This is done by defining an “Extraction pattern” for getting data fields:
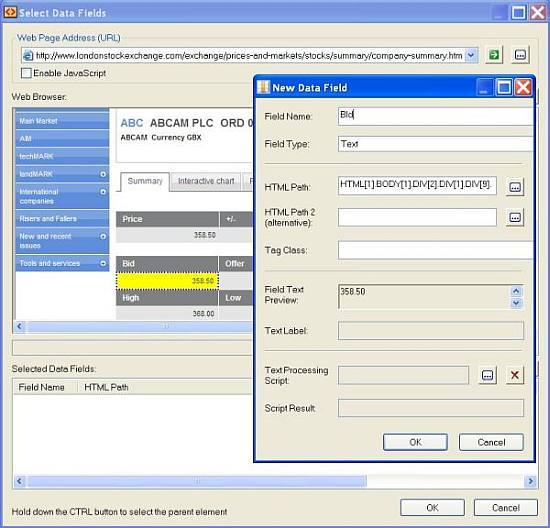
And finally, when you’re done with all the rules and patterns, run the web scraping session. You may track the scraped data at the bottom:
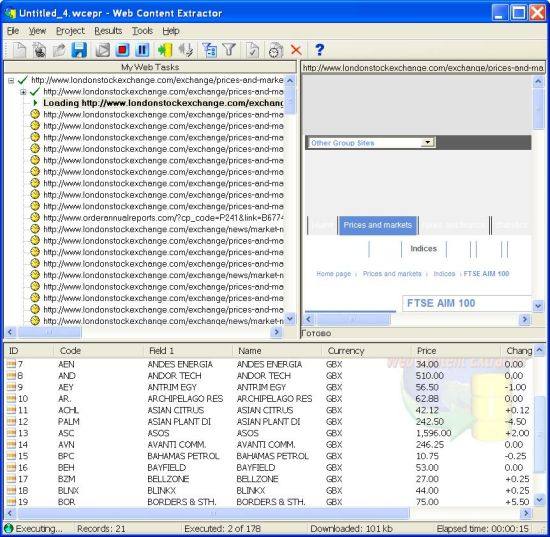
As soon as you get all the web data scraped, export it into the desired destination:
Dynamic Elements Extraction
Scraping of dynamic web page elements (like popups and ajax-driven web snippets) is not an easy task. Originally, we didn’t consider Web Content Extractor to be able to break through here, but with transformation URL script, it’s possible. Thanks to the Newprosoft support center, we got help with crawling over popups on a certain web page.
Go to Project->Properties->Crawling Rules->URL Transformation Script, where you may compose a script that will change casual crawl behavior into a customized one:
![]()
The task of building a transformation script is not a trivial one. Yes, it is possible to make a project to crawl through dynamic elements, but, practically speaking, you’ll need to know web programming (XPath, Regex, JavaScript, VBScript, jQuery).
Here is an example of such an URL transformation script for scraping popups from http://www.fox.com/schedule/ (the script was composed by a Newprosoft specialist, so in difficult cases you’ll need to turn to them):
Function Main ( strText )
dim strResult
If ( InStr ( strText, "episode" ) > 0 ) Then
strjQueryValue = Get_jQueryValue ( strText )
If ( IsNumeric( strjQueryValue ) ) Then
strResult = "javascript: jQuery('div.episode:eq(" + CStr ( CInt (
strjQueryValue ) - 2 ) + ")').mouseenter(); void(0);"
End If
End If
Main = strResult
End Function
Function Get_jQueryValue ( strText )
dim strResult
strResult = Sub_String ( strText , " jQuery" , ">" , "")
strResult = Sub_String ( strResult , "=""" , """" , "")
Get_jQueryValue = strResult
End Function
Function Sub_String ( strText ,
strStartSearchFor , strEndSearchFor , strReverseSearch )
dim numStartPos , numEndPos , numLineIndex, strResult
If ( Len ( strStartSearchFor ) > 0 ) Then
If ( strReverseSearch = "1" ) Then
numStartPos = InStrRev ( strText , strStartSearchFor )
Else
numStartPos = InStr ( strText , strStartSearchFor )
End If
Else
numStartPos = 1
End If
If ( Len ( strEndSearchFor ) > 0 ) Then
numEndPos = InStr ( numStartPos + Len( strStartSearchFor ) ,
strText , strEndSearchFor )
Else
numEndPos = Len ( strText ) + 1
End If
If ( numEndPos = 0 ) Then
strEndSearchFor = ""
numEndPos = Len ( strText ) + 1
End If
If ( numStartPos > 0 AND numEndPos > numStartPos + Len (
strStartSearchFor ) ) Then
strResult = Mid ( strText , numStartPos + Len ( strStartSearchFor ) ,
numEndPos - numStartPos - Len ( strStartSearchFor ) )
Else
strResult = ""
End If
Sub_String = strResult
End Function
Multi-Threading and More
As far as multi-threading, the Web Content Extractor sends several server requests at the same time (up to 20), but remember that each session runs with only one extraction pattern. Filtering helps with sifting through the results.
Summary
The Web Content Extractor is a tool to get the data you need in “5 clicks” (the example task we completed within 15 minutes). It works well if you scrape simple pages with minimum complications for your private or small enterprise purposes.
11 replies on “Web Content Extractor Review”
Hi,
I have been using this software for years. It works very well with a bit of getting used to how it is organized. But having tried out other software on this site, this one is not that bad to use.
But, I have been trying to reach Michael for weeks to help with support. He had always been very good about getting back to me, but he has disappeared. I am not sure what is going on.
There are some websites that you simply need his help to formulate the queries. Without his help, the software is worthless on those websites.
Hope he comes back around.
Sam
Hello Sam,
Please send your request here: http://www.newprosoft.com/service.htm
Michael,
Newprosoft
I want to find out if your extractor can work on http://www.vconnect.com, I want to extract Business name, contact name, phone numbers, business address, email address . Category or business type
Do I need programing skill to use your software on the above website?
Hi Lekan,
Web Content Extractor is not our software. You can contact their support if you have any questions. But I don’t think that you need any programing skills to build a project with WCE (unless the website is too complicated).
Regards,
Mike
VERY nice post. It made me able to understand basic steps which I was not able to understand by watching videos. Thanks a lot
Hi Michael Shilov,
I am thankful to you for this wonderful post.
I have downloaded the trial version and possibly buy it in near future.
But I have a question for the support but If any one can help, then I will be highly thankful.
Question is that how can I scrape the data hidden in form of hyperlinks.
For example visit this page:
http://www.yelp.com/biz/the-grasshopper-smoke-shop-brownsville#query:smoke%20shops
When we hover the curson above the button “write a review”, we see the address “http://www.yelp.com/writeareview/biz/m_-fCuCb0RkFbeHmJFGz6Q?return_url=%2Fbiz%2Fm_-fCuCb0RkFbeHmJFGz6Q”.
I want to copy this address and I am not sure how can I do this.
Hi,
It not our program. I suggest you to send your request to Newprosoft at http://www.newprosoft.com/service.htm. I think they will be happy to help you.
Thanks,
Mike
This is very useful information shared here. Thank you for sharing it.
i want to know how useful and how effective can it be for my website. http://www.africalinked.com
One drawback is it ignores whatever encoding the target website has in terms of HTML data, resulting in foreign characters extracted as mojibake/gibberish.
I have had previous experience with the web content extractor tool.
I’m currently trying to scrape a page from Amazon Vendor Central (requires a two-factor authentication). In my previous job I was able to create a project where the crawling rule would be to follow link text equals “Next”.
I duplicated this same project at my current job but for some reason, the project does not get back the first page.
Could you please help sort out the issue here so that my results will pull all the available pages of information?
Thanks so much!