![]() In the previous post I’ve shown the way to apply website traffic data (time series) in order to find any correlation with organic search queries from the Google database in time span. Here I want to show two more features of Google Trends (former Correlate): (1) finding search terms that have a pattern of activity over time similar to the custom query and (2) finding query terms whose popularity over time matches any shape you draw. Those features provide some insights into search traffic optimization and might be a support tool for Google Webmaster Tools.
In the previous post I’ve shown the way to apply website traffic data (time series) in order to find any correlation with organic search queries from the Google database in time span. Here I want to show two more features of Google Trends (former Correlate): (1) finding search terms that have a pattern of activity over time similar to the custom query and (2) finding query terms whose popularity over time matches any shape you draw. Those features provide some insights into search traffic optimization and might be a support tool for Google Webmaster Tools.
![]() Both my partner and I were asking: what factors influence website traffic? How does one find any correlations in business intelligence related to organic searches? This post was born out of my attempt to join together both traffic data from the business blog (data source being Google Analytics) and real organic queries done in Google, in order to get some insight into which items my traffic correlates with, in specific how these items ( i.e. those which people are searching for) might have influenced website traffic.
Both my partner and I were asking: what factors influence website traffic? How does one find any correlations in business intelligence related to organic searches? This post was born out of my attempt to join together both traffic data from the business blog (data source being Google Analytics) and real organic queries done in Google, in order to get some insight into which items my traffic correlates with, in specific how these items ( i.e. those which people are searching for) might have influenced website traffic.
This table is what I’ve scraped in 1 min from pinterest.com to access all the categories and the links to corresponding Pinterest pages.
I want to share on the research which was done by some Estonian students concerning web traffic analysis. The case study they undertook is about mining frequent user access patterns from web log files. The primary objective was to discover the most frequent browsing patterns by analyzing the browsing sessions in logs.
 This short essay is about data mining methods applied in web traffic analysis and other business intelligence. It also provides a modern look at data mining in light of the Big Data era.
This short essay is about data mining methods applied in web traffic analysis and other business intelligence. It also provides a modern look at data mining in light of the Big Data era.
 This short essay is about data mining methods applied in web traffic analysis and other business intelligence. It also provides a modern look at data mining in light of the Big Data era.
This short essay is about data mining methods applied in web traffic analysis and other business intelligence. It also provides a modern look at data mining in light of the Big Data era.
For a site owner, business blogger or e-commerce entity, there are always some variables of interest concerning web traffic and statistics. How would you predict future values of variables of interest? Variables of interest might include the number of visitors to a target website, the time each visitor spends on the site, and whether or not the visitor reaches the site’s goals. One needs to mention that these web traffic and site performance analyses are not imposed with stringent time constraints. Data mining techniques seek to identify relationships between the variable of interest and the variables in a data sample. There are at least 3 analysis models for data mining that we consider here.
![]() The content war is currently waging on the web. What particular keywords bring organic traffic to my site? Where is my website positioned in the users’ organic search using these keywords? How does my page get top ranked? These concerns are relevant to many site owners and business bloggers. This topic is to help you to master Google Webmaster Tools (Search console) as the means to see how your page content performs before the click.
The content war is currently waging on the web. What particular keywords bring organic traffic to my site? Where is my website positioned in the users’ organic search using these keywords? How does my page get top ranked? These concerns are relevant to many site owners and business bloggers. This topic is to help you to master Google Webmaster Tools (Search console) as the means to see how your page content performs before the click.
![]() Analytics. Google. Social networks. Marketing campaign. Business Intelligence. It takes strong nerves to deal with all this in the vibrant, growing web business. The first thing necessary is to be real-time aware of what happens within an enterprise. Here I have chosen as notable some of the most usable tools for helping to monitor, visualize and compare analytics’ data.
Analytics. Google. Social networks. Marketing campaign. Business Intelligence. It takes strong nerves to deal with all this in the vibrant, growing web business. The first thing necessary is to be real-time aware of what happens within an enterprise. Here I have chosen as notable some of the most usable tools for helping to monitor, visualize and compare analytics’ data.
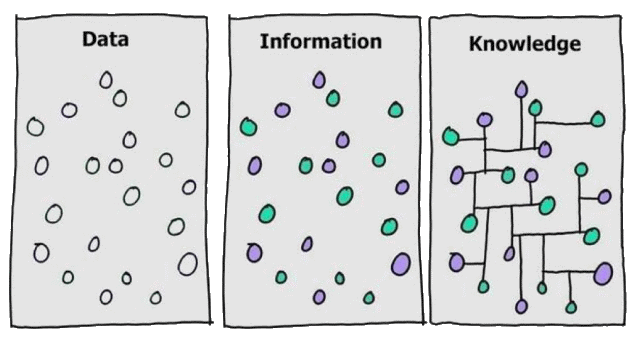
Have you ever thought that there is a difference between such terms as “data”, “information” and “knowledge”? Often people mix and misuse them and it’s not a problem in our daily life, but when we come to Data Mining it’s good to distinguish them. Here I’ll try to show the difference in an comprehensible way.
Categories
Selenium IDE and Web Scraping
![]() Selenium is a web application testing framework that supports for a wide variety of browsers and platforms including Java, .Net, Ruby, Python and other. In this post we touch on the basic structure of the framework and how it can be applied in Web Scraping.
Selenium is a web application testing framework that supports for a wide variety of browsers and platforms including Java, .Net, Ruby, Python and other. In this post we touch on the basic structure of the framework and how it can be applied in Web Scraping.