![]() Selenium is a web application testing framework that supports for a wide variety of browsers and platforms including Java, .Net, Ruby, Python and other. In this post we touch on the basic structure of the framework and how it can be applied in Web Scraping.
Selenium is a web application testing framework that supports for a wide variety of browsers and platforms including Java, .Net, Ruby, Python and other. In this post we touch on the basic structure of the framework and how it can be applied in Web Scraping.
What is Selenium IDE
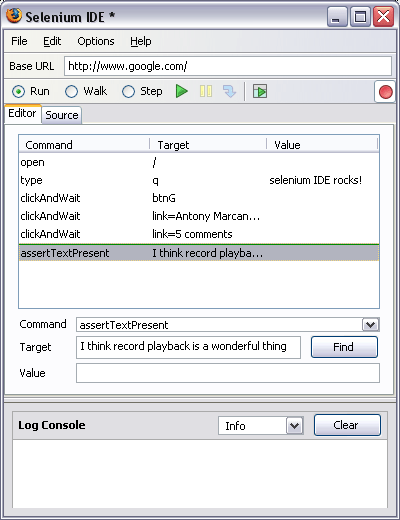
Selenium IDE is an integrated development environment for Selenium scripts. It is implemented as a Firefox plugin, and it allows recording browsers’ interactions in order to build automated test cases. It also can be applied for browser activity automation. The Selenium Remote Control is a separate application allowing automated testing in a distributed environment; it causes custom scripts to be implemented for controlled browsers. Selenium can be deployed on Windows, Linux, and Mac OS. How various Selenium components are supported with major browsers (read here).
What does Selenium do and Web Scraping
Basically Selenium automates browsers. This ability is no doubt to be applied to web scraping. Since browsers (and Selenium) support JavaScript, jQuery and other methods working with dynamic content why not use this mix for benefit in web scraping, rather than to try to catch Ajax events with plain code? The second reason for this kind of scrape automation is browser-fasion data access (though today this is emulated with most libraries).
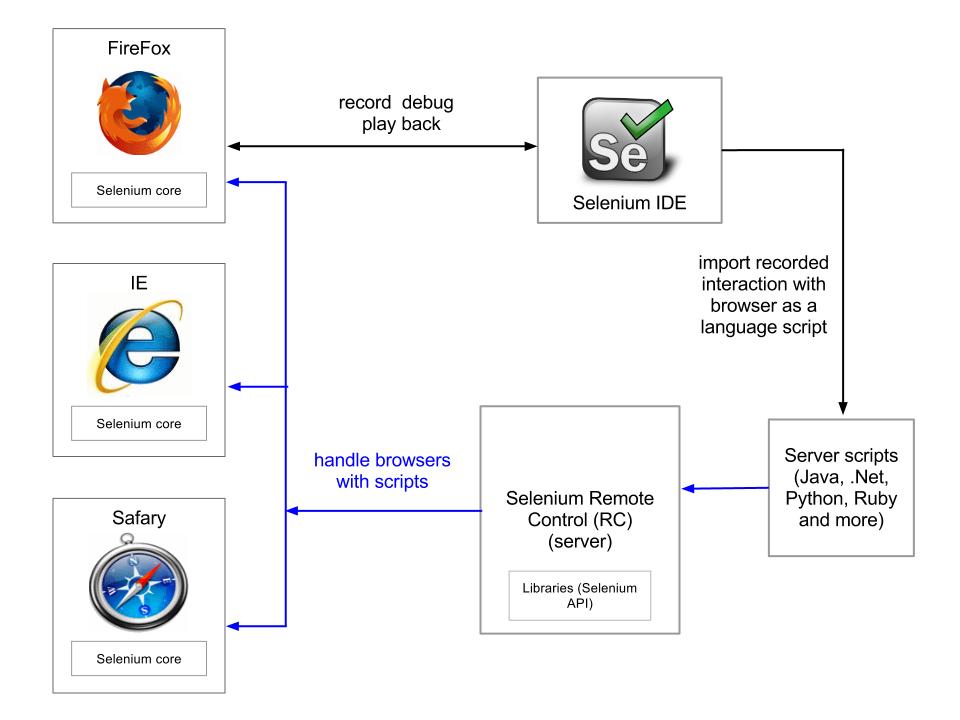
Yes, Selenium works to automate browsers, but how to control Selenium from a custom script to automate a browser for web scraping? There are Selenium PHP and other language libraries (bindings) providing for scripts to call and use Selenium. It is possible to write Selenium clients (using the libraries) in almost any language we prefer, for example Perl, Python, Java, PHP etc. Those libraries (API), along with a server, the Java written server that invokes browsers for actions, constitute the Selenum RC (Remote Control). Remote Control automatically loads the Selenium Core into the browser to control it. For more details in Selenium components refer to here.
A tough scrape task for programmer
 cURL is good, but it is very basic. I need to handle everything manually; I am creating HTTP requests by hand. This gets difficult – I need to do a lot of work to make sure that the requests that I send are exactly the same as the requests that a browser would send, both for my sake and for the website’s sake. (For my sake because I want to get the right data, and for the website’s sake because I don’t want to cause error messages or other problems on their site because I sent a bad request that messed with their web application). And if there is any important javascript, I need to imitate it with PHP. It would be a great benefit to me to be able to control a browser like Firefox with my code. It would solve all my problems regarding the emulation of a real browser – it seems that Selenium will allow me to do this -Ryan S
cURL is good, but it is very basic. I need to handle everything manually; I am creating HTTP requests by hand. This gets difficult – I need to do a lot of work to make sure that the requests that I send are exactly the same as the requests that a browser would send, both for my sake and for the website’s sake. (For my sake because I want to get the right data, and for the website’s sake because I don’t want to cause error messages or other problems on their site because I sent a bad request that messed with their web application). And if there is any important javascript, I need to imitate it with PHP. It would be a great benefit to me to be able to control a browser like Firefox with my code. It would solve all my problems regarding the emulation of a real browser – it seems that Selenium will allow me to do this -Ryan S
Yes, thatís what we will consider below.
Scrape with Selenium
In order to create scripts that interact with the Selenium Server (Selenium RC, Selenium Remote Webdriver) or create local Selenium WebDriver script, there is the need to make use of language-specific client drivers (also called Formatters, they are included in the selenium-ide-1.10.0.xpi package). The Selenium servers, drivers and bindings are available at Selenium download page.
The basic recipe for scrape with Selenium:
- Use Chrome or Firefox browsers
- Get Firebug or Chrome Dev Tools (Cntl+Shift+I) in action.
- Install requirements (Remote control or WebDriver, libraries and other)
- Selenium IDE : Record a ‘test’ run thru a site, adding some assertions.
- Export as a Python (other language) script.
- Edit it (loops, data extraction, db input/output)
- Run script for the Remote Control
Selenium components for Firefox installation guide
For how to install the Selenium IDE to Firefox see here starting at slide 21. The Selenium Core and Remote Control installation instructions are there too.
Extracting for dynamic content using jQuery/JavaScript with Selenium
One programmer is doing a similar thing
1. launch a selenium RC (remote control) server
2. load a page
3. inject the jQuery script
4. select the interested contents using jQuery/JavaScript
5. send back to the PHP client using JSON.
He particularly finds it quite easy and convenient to use jQuery for
screen scraping, rather than using PHP/XPath.
Conclusion
The Selenium IDE is the popular tool for browser automation, mostly for its software testing application, yet also in that Web Scraping techniques for tough dynamic websites may be implemented with IDE along with the Selenium Remote Control server. These are the basic steps for it:
- Record the ‘test’ browser behavior in IDE and export it as the custom programming language script
- Formatted language script runs on the Remote Control server that forces browser to send HTTP requests and then script catches the Ajax powered responses to extract content.
Selenium based Web Scraping is an easy task for small scale projects, but it consumes a lot of memory resources, since for each request it will launch a new browser instance.