Problem
I am trying to scrape the page https://tienda.mercadona.es/categories/112 and I have installed the docker and followed all the required steps given in the post. Splash works well, but the spyder does not and I don’t know why. The IP of the splash_url is correct but I can’t see in the response object when I write scrapy shell “webpage” the complete page, ie, the page has not rendered correctly.
Process
I have followed the steps for installing and start with the docker in this link: https://splash.readthedocs.io/en/latest/install.html
My code is very simple. I create in pyCharm a project and I have only changed two files: settings.py and the spider.py.
settings.py:
BOT_NAME = 'MercadonaINE' SPIDER_MODULES = ['MercadonaINE.spiders'] NEWSPIDER_MODULE = 'MercadonaINE.spiders' USER_AGENT = 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' ROBOTSTXT_OBEY = False DOWNLOADER_MIDDLEWARES = { 'scrapy_splash. SplashCookiesMiddleware': 723, 'scrapy_splash. SplashMiddleware': 725, 'scrapy.downloadermiddlewares. httpcompression. HttpCompressionMiddleware': 810, } SPLASH_URL = 'http://192.168.1.37:8050/' SPIDER_MIDDLEWARES = { 'scrapy_splash. SplashDeduplicateArgsMiddlewar e': 100, } DUPEFILTER_CLASS = 'scrapy_splash. SplashAwareDupeFilter' HTTPCACHE_STORAGE = 'scrapy_splash. SplashAwareFSCacheStorage'
spyder.py:
import scrapy from ..items import MercadonaineItem #from scrapy.utils.response import open_in_browser from scrapy_splash import SplashRequest class MercadonaSpider(scrapy.Spider): name = 'mercadona' start_urls = [ 'https://tienda.mercadona.es/ categories/112' ] def start_requests(self): for url in self.start_urls: yield SplashRequest(url, self.parse, endpoint='render.html', args={'wait': 3},) def parse(self, response): #open_in_browser(response) title = response.css('title::text'). extract() yield {'title': title}
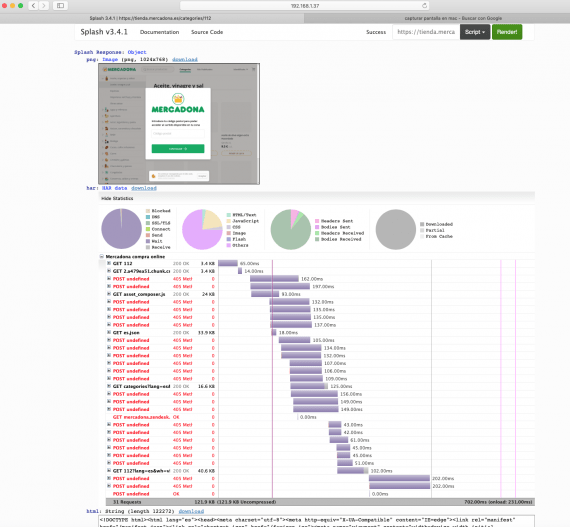
In a browser I check with 192.168.1.37:8050. I see that the code loads the page https://tienda.mercadona.es/categories/112 with the initial form and the products and I can see the html code of all the components. The page loads the content dynamically with javascript. (see the following screen captures).
The problem is when I run the spider. The response object does not contain the complete html elements (see a screen capture below). In the html code there are not the first form of the page and there are not any product with the prices.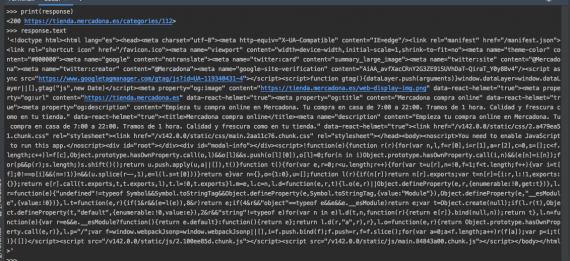
I think this example is the most simple one. I have checked some examples that also work with javascript for loading the main page and they work well (for example the quotes example that is in the web), but the case I described above is impossible for me.
Please, advise any way out thru posting in comments. I appreciate any help.
Julio César