When I needed to extract dictionary words’ definitions I chose Python and lxml library. In this tutorial, I’ll review the steps of scraping Webster online dictionary using lxml in Python.
Download and Install lxml Library
To put lxml into my Linux system, I ran: “wget http://xmlsoft.org/downloads.html”.
To install it there, I executed the following as super-user (or administrator): “pip install lxml”.
How to Find XPath of Items on a Web Page
For the scrape i need to locate the page elements i want to get, so for this i do parsing of the web page elements using XPath. How to find a XPath of a particular HTML element? I used both Google Chrome developer tools (Ctrl+Shift+I or Settings -> Tools -> Developer Tools) and Scraper CG (Google Chrome) extension.
- Select “loup” tool at the bottom panel of developer tools
- Click on the element in the browser window, highlighting it
- At the opened DOM tree, right-click on the blue highlighted element HTML notation and in the contextual menu, choose “Copy XPath” – to save XPath of an element to the clipboard:
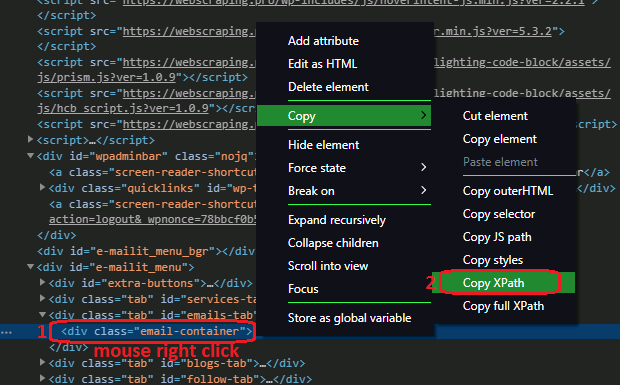
Interestingly, the XPath issued by Google Chrome developer tools, Scraper GC (Google Chrome) extension, and even XPather, FF add-on, did not match the real XPath I eventually extracted with. Given by the tools:
I found it through trial and error using DOM tree structure at Google Chrome:
Use lxml.html.parse to Parse with XPath
First, I grab the whole HTML dictionary page according to a word supplied:
import lxml.html
word = raw_input()
doc = lxml.html.parse('http://www.websters-online-dictionary.org
/definitions/%s' % word)Second, I find out that the word’s parts of speech with definitions start from a 3-D table row (<tr>) and don’t include the last one (this is needed for later scrape). To find it, I used Scraper CG ext.; see the picture below. Through Google Chrome developer tools, I re-checked the actual starting table row with definitions, but it turned out to be different.
Now, using XPath method of the lxml library I get all related trs:
trs = doc.xpath("/html/body/div[1]/div[1]/table[1]/tbody/tr")Then, I extract the text of the target cells from the HTML content looping over the target table rows (starting from 3d):
table = []
trs = doc.xpath("/html/body/div[1]/div[1]/table[1]/tbody/tr")
for tr in islice(trs, 3):
for td in tr.xpath('td'):
table += td.xpath("/b/text() | /text()")And, finally, I concatenated the result list “table“ into the string variable for output:
buffer = ''
for i in range(len(table)):
buffer += table[i]Here is the whole code snippet:
import lxml.html
import os
class SkipException (Exception):
def __init__(self, value):
self.value = value
word = raw_input()
try:
doc = lxml.html.parse('http://www.websters-online-dictionary.org
/definitions/%s' % word)
except SkipException:
doc = ''
if doc:
table = []
trs = doc.xpath("/html/body/div[1]/div[1]/table[1]/tbody/tr")
for tr in islice(trs, 3):
for td in tr.xpath('td'):
table += td.xpath("/b/text() | /text()")
buffer = ''
for i in range(len(table)):
buffer += table[i]That’s it. If you have any questions, feel free to ask them here.