Recently we’ve got the tricky website, its data being of dynamic nature. Yet we’ve applied the modern day scraping tools to fetch data. We’ve develop an effective Python scraper using Selenium library for browser automation.
About the project
We were asked to have a look at a retailer website.
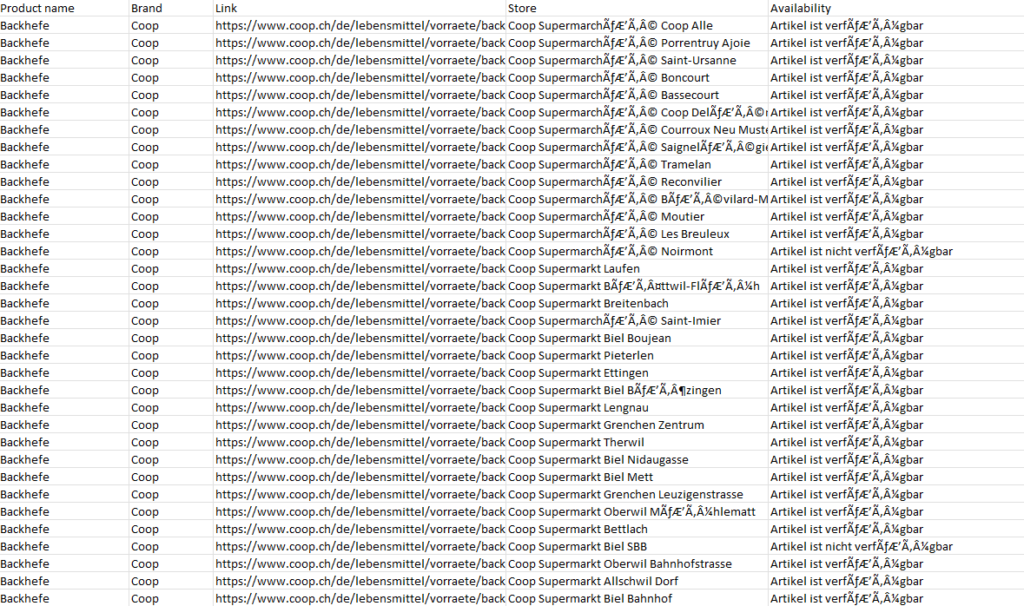
And our task was to gather data on 210 products’ availability in 945 shops. The scrape resulted in about 200K data entries in a CSV format. Moreover, every line contained information about name, link, brand, store and the availability of a product. Below you can familiarise yourself with a small data sample we were able to gather.
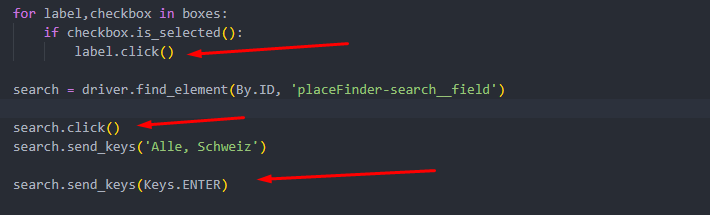
As previously mentioned, this website was of dynamic nature. Furthermore, we had to follow the client’s particular orders to filter out the right data. Our automation script had to follow the specific steps and enter the right information for each product as is shown on the following screenshot:

- Click on “Filialsuche”.
- No tick for «jetzt geöffnet» and no tick for «Nur Filialen mit Artikelverfügbarkeit».
- Enter “Alle, Schweiz” in an input field so we get all Switzerland stores.
- Scrape the text for each store.
- Scrape the bold text for each store.
- Take the next product and scrape next stores info.
Gathering Data with Python Selenium Scraper
The Selenium library was a perfect tool for this task as it allows direct interaction with the dynamic content. We were able to instruct the script with specific commands to access the needed parts of the website and enter the required information through Selenium’s WebDriver using .click() and .send_keys() methods.
for label,checkbox in boxes:
if checkbox.is_selected():
label.click()
search = driver.find_element(By.ID, 'placeFinder-search__field')
search.click()
search.send_keys('Alle, Schweiz')
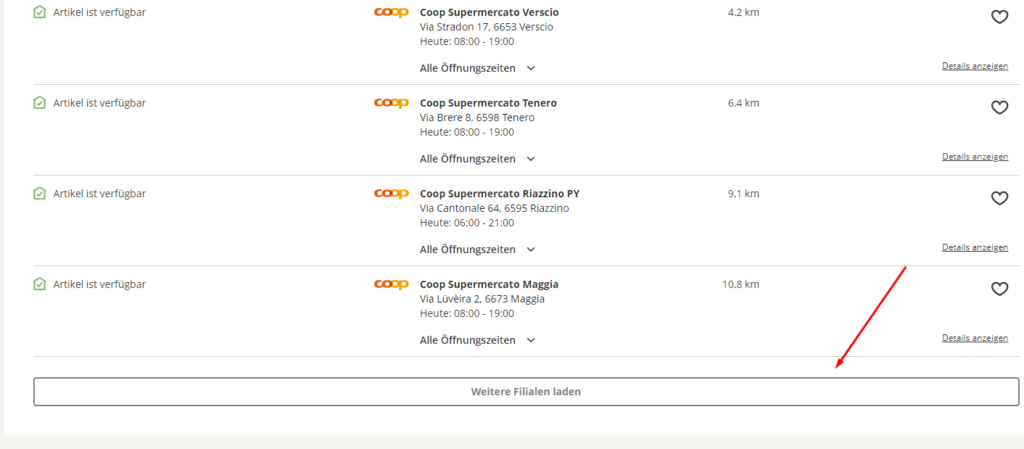
search.send_keys(Keys.ENTER)Moreover, not all 910 shops were readily available and would not be viewable in the source code of the product’s web-page. Only 10 shops at a time were seen on a page and in order to get access to more stores, we had to write a code that would implement the “Load More” button allowing us to see 10 more shops at a time. Therefore, our script had to click on this button until the very last shop was accessible throughout the HTML source code. Our scraping developers were able to achieve this by using a while loop and error-handling for the case when Load Button was no longer active.
Challenges in gathering Dynamic Data
During the process of gathering data, there were a few types of challenges we had to tackle, for example:
- Network instability: Since all commands sent over network: client -> (selenium grid: in case need) -> browser driver -> actual browser. Any connection issue may cause reason to a failure.
- CSS animations: Since it executes commands directly, if you have some animative transitions, it may cause to fail.
- XHR/AJAX-similar requests or dynamic element changing. If you have such “Load more” btn or displaying after some actions, it may not detect or still be overlapping.
Implementing .sleep() method from Python’s built-in time library “time” has shown some improvement, however it was not ideal. The code would still occasionally result in “Element Is Not Clickable at Point” or “Element Is Not Interactable at Point”. The error “Element is not clickable at point” is self-explanatory. It means that the element that you’re trying to click on can’t be clicked at that particular point. You’d usually find this error when you locate an element and try to execute a click action on it. The question is, “why is the element not clickable if the element is found”?
You’ll find this error mostly while using the Google Chrome browser but hardly ever while using the Firefox browser. The reason for this being common in the Chrome browser is because the Chrome driver always clicks in the middle of the element. So when you’re testing a dynamic application, there are chances that the element you want to click on isn’t at the exact location as expected.
Another reason why this kind of error could occur would be that the script is trying to gather data from the page before it is fully accessible. In other words, the page is getting refreshed before it is clicking the element.
Tackling the Challenges
In order to tackle this situation, our programmers had to induce WebDriverWait’s functions from expected_conditions for the element to be clickable: .element_to_be_clickable()

from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="tab-panel__tab--product-pos-search"]/h2'))).click()
Supervising the Data Gathering Process in order to prevent Errors
In order to be able to manually supervise the process of gathering data and debug the code if any errors took place, we put the scraper’s code into a for-loop’s range() function. The start would correspond with the 1st link in the list of products’ links (that were not scraped yet) and the end would be the last link in the list of links (the one we want to go up to). Thus, we were able to scrape a definite amount of products at a time. If the error erose, Python would give us an error at the specific index (or scope depending on how we run the code). Therefore, we would be able to save the previous data and carry on with gathering information about the rest of products.

for i in range(67,70):
print(f'Start of {i}')
scrape_func(i)
print(f'End of {i}')
print('\n')Writing Data into CSV File with Python CSV Library
Finally, we wrote the gathered data into a CSV file using Python’s Built-in CSV Library:

f = open('coop_scrape_final_product.csv','a',newline='',encoding='utf-8')
f_writer = csv.writer(f,delimiter=';')
for line in final_example:
f_writer.writerow(line)
f.close()