
We’ve already written about suitable proxy servers for web scraping. Now we want to focus our readers on those for the huge/mass quantities data records scrape, particulary from the business directories. When scraping business directories, their web servers can identify repetitive requesting and put you on hold by looking at the IP address that is used for frequent http requests. Proxy rotation web service is the means for repeatedly changing IP address. Thus, target web server can only see the random IP addresses from rotating proxies pool at each request.
Private Proxy Switch (rotating proxies)
We list here some prerequisites for proxy service fitting to mediate huge data sets extraction.
- Avoid a target business directory server software [easy] to detect unusual activity by observing a large number of requests from a single IP address.
- Being able to change IP address periodically (basically with each request to a business directory).
- Should be a huge pool of IP proxies, provided the huge number of data requests are to be made.
The main idea is that for the hundreds of thousands of scraper bot requests should be few requests from the same IP, so that a target business directory (ebay, amazon, linkedin etc.) would not define this activity as “originating from one single IP” but have an idea of unrelated multiple (hundred thousands of) users’ visitations. This does require a huge IP pool or decentralized IP network. It should provide you not just anonymity but also IP unrepresentative.
It’s supposed to be scalable to meet high bandwidth and high-frequency requests.
The scraping agent
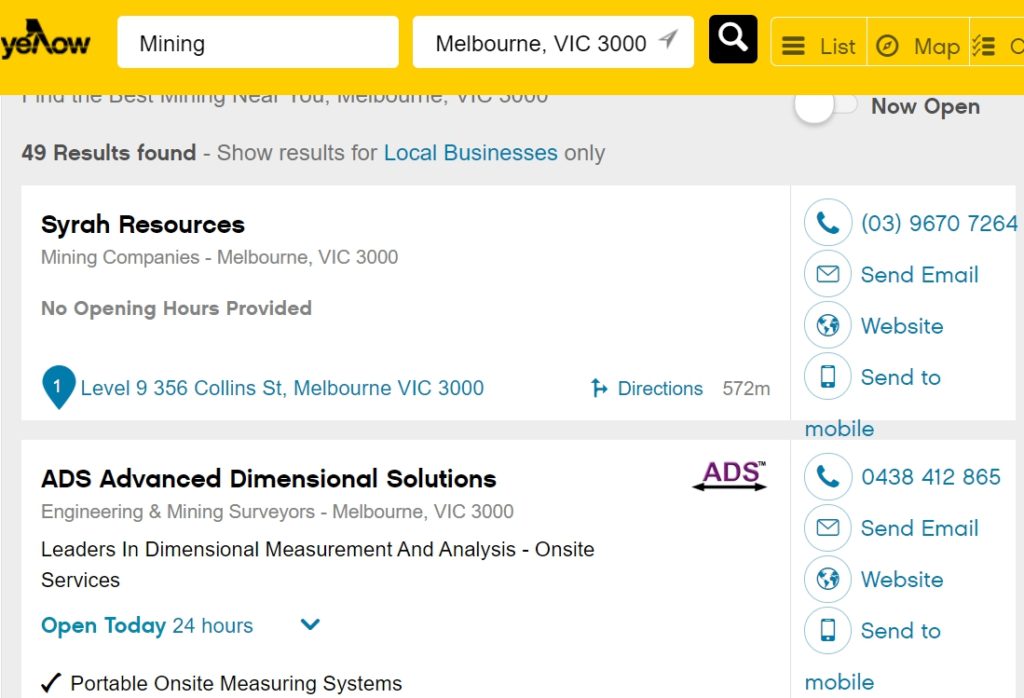
With Content Grabber support we’ve got an yellowpages.com.au scraping agent. We have set it to traverse YP directory to get a list of Australia hotels (only name and phone number), sure we have not exposed the extracted data to anyone. This extraction exercise was solely for testing purpose.
Concurrency
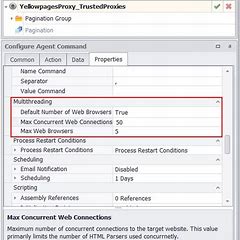
After the first test round we’ve found out most of the proxy services support concurrent connections. Content Grabber also allows to execute agent with concurrent requests. We do not recommend you to set multiple connection number to 500 since it puts a significant strain on almost any website, including business directory site. At the picture to the left you can watch how to set concurrent requests in Content Grabber.
Proxy services test results
The overall proxy services results
| Stars | Speed | Error rate | Proxies pool | Notes | |
|---|---|---|---|---|---|
 | Low | Excellent! | |||
 | Low | ||||
| Low | 7000 requests trial limit |
The numerical results of the test
| Web requests done | Total execution time | Total extracted (unique) records number | |
|---|---|---|---|
| 10046 | 30 min – ½ hour | 1180 | |
| 19466 | 2 ½ hours | 1214 | |
| 7000 | 45 min – ¾ hours | 960 | |
| 20512 | 1 ⅕ hours | 855 |
*SquidProxies.com is not a rotating proxy service. It’s a data-center proxy provider.
The numerical results of the Content Grabber scraping agent of yellow pages aggregator using different rotating proxy services. 50 concurrent requests by the agent.
Nohodo
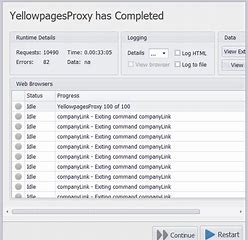
With Nohodo I got the best results. It has seamlessly integrated into the Content Grabber and has done a prompt scrape of yellowpages website. Proxy worked well. It turned out that Content Grabber facilitates proxy service work in debug mode too. See the Nohodo results completed. Total 10490 requests done for little more than half an hour! 1180 unique records extracted. Error rate is low, see a figure at the left.
Nohodo quote:
“Nohodo can integrate an anonymous proxy network into any third party application or business process, with no adjustment to operations and minimal oversight by project leads”. Nohodo posesses thousands of IPs spread all over the globe.
Their pricing plan starts from $100 per 100K queries. And price is flexible/discounting provided you want bigger monthly traffic. Free trial is avail. Read how to easy integrate it into Content Grabber and get free bonus proxied requests.
Charity Engine
With Charity Engine I’ve got the help of the support. The proxy credentials were needed to be used inside of the Agent Settings -> Proxy source (Proxy list) -> Proxy Settings.
The base 64 encoded username you’ll get at the Charity Engine account. The test result has shown the longer timing and bigger extracted records number.
Out of 19466 scraped records, only 1214 (~6%) were unique. The agent run 6 and 2/3 hours. Overall the unique records number scraped by Charity is higher (6% more) than the records number scraped by Nohodo. Yet this is due to the site specification and scraping agent characteristic.
Because of the nature of the proxy grid (over 500,000 home PCs as proxies) the timing has been significantly higher compare to the Nohodo scraper run.
Country-specific commands
Charity support has proposed us to try the country-specific proxy nodes.

For the only US nodes test, the result has been sightly better: 4 hours with 1180 unique records extracted. See the results below:
Ethical issues
As part of their contracts with the charities, they only service ethical business customers. They don’t serve individuals unless they have professional liability insurance (if any user scrapes something bad, it would damage the brand and grid). Also, the minimum spend is $1k.
Trusted Proxies
Trusted Proxies service has shown good results with 7000 trial requests that were afforded to us for the test. The error rate was low and the proxy service has completed 7000 requests within 45 mins being a good result. Trusted Proxies support boasts its service being able to processed up to 600 Queries Per Minute.
Recap
Overall the rotating proxy services has shown good performance, providing anonymity for the site aggregators’ scrape. The big players in the proxy business have done the best. The larger the service (containing thousands or even millions of IPs), the less possibility of it to be detected and IPs being banned.
11 replies on “Reliable rotating proxies for business directories scrape”
Hi Igor,
Did you tried Scrapoxy (scrapoxy.io) ?
It is an open-source proxy of proxies. It starts instances on cloud providers and routes requests throught them.
Regards,
Fabien.
I find scaproxy is very similar to a number of rotating proxy services out there. If you don’t want to set up accounts at cloud providers and spent time installing and managing the software consider hosted solutions. I personally use this one
https://botproxy.net It is quite cheap and connection speed is fast. There are a number of cloud proxies as well as many open proxies. Cool feature is that I can easyly change outgoing location by using only proxy username without any coding.
Here is an alternative provider of quality high speed private proxies… Check: http://www.captchasolutions.com/proxies/
But those are limited to 500 proxies. Is it enought to scrape tens of thousands of records?
Yes it is since our proxies are all dedicated private proxies with redundant fast network rings it could handle hundreds of thousands of requests specially for scraping…
Did you try Crawlera?. It’s more expensive for some use cases but I’ve found it outperforms CharityEngine for my needs (online retailer scraping)
Did you try hostip?
https://black-lister.com
I’ve not yet tried hostip.info
Would smartproxy.io residential addresses work out ok? Have purchased for Instagram, but wondering if those would work top-notch for scraping too.
Has anyone used Oxylabs proxies for this purpose? Have access to them from my business would be great to use them for my project.
Can I scrape the site https://printestore.com/ with proxies?