Recently I was asked to help with the job of scraping company information from the Yellow Pages website using the ScreenScraper Chrome Extension. After working with this simple scraper, I decided to create a tutorial on how to use this Google Chrome Extension for scraping pages similar to this one. Hopefully, it will be useful to many of you.
Tag: business directory
On September 9th, 2019 the UNITED STATES COURT OF APPEALS 1 has affirmed the former district court’s determination that a certain [data] analytic company is lawful to scrape [perform automated gathering] LinkedIn’s public profiles info. Now the historical event has happened in which a court is protecting a data extractor’s right for mass gathering openly presented business directory information.
Recently I received this question: What are the best online resources to acquire data from?
The top sites for data scrape are data aggregators. Why are they top in data extraction?
They are top because they provide the fullest, most comprehensive data [sets]. The data in them are highly categorized. Therefore you do not need to crawl and fetch other resources and then combine multiple-resource data.
Those sites fall into 2 categories:
- Goods and services aggregators. Eg. AliExpress, Amazon, Craiglist.
- Personal data and companies data aggregators. Eg. Linkedin, Xing, YellowPages. For such aggregators another name is business directories.

The first category of sites and services is quite wide-spread. These sites and services promote their goods with the goal of being well-known online, to have as many backlinks as possible to them.
The second category, the business directories, does not tend to reveal its data to the public. These directories rather promote their brand and give scraping bots minimum opportunity for data acquiring*.
Consider the following picture where a company’s data aggregator gives to the user only 2 input fields: what and where.
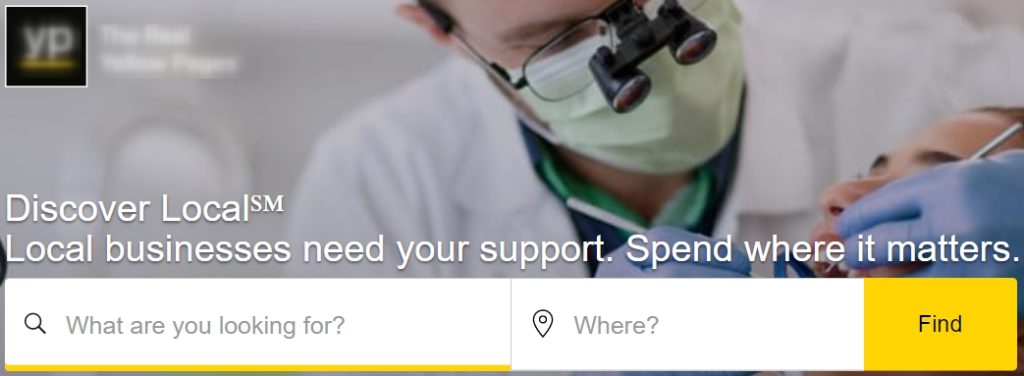
You can find more of how to scrape data aggregators in this post.
————–
*You have to adhere to the ToS of each particular website/web service when you perform its data scraping.
In this post I’d like to share my experience with scraping data aggregator/business directory using the residential proxy of the Bright Data proxy provider in conjuction with its proxy manager.
Categories
Web Scraping with Node.js
 The web scraping topic has been actively growing in popularity for dozens of years now. Freelance sites are overcrowded with orders connected with this contradictory data extracting process. Today we will combine two new and revolutionary directions in web development. So, let’s consider an elegant and modern way to scrape data from websites with Node.js!
The web scraping topic has been actively growing in popularity for dozens of years now. Freelance sites are overcrowded with orders connected with this contradictory data extracting process. Today we will combine two new and revolutionary directions in web development. So, let’s consider an elegant and modern way to scrape data from websites with Node.js!
Question
I want to extract the hotel name and the current room price of some hotels daily from https://www.expedia.ca/Hotel-
I am a small hotel owner and want those info quite often, and hope I can do it with codes automatically in someway. You are expert in this field, what is the easiest ways to get those information? Can you give me some example codes?

We’ve already written about suitable proxy servers for web scraping. Now we want to focus our readers on those for the huge/mass quantities data records scrape, particulary from the business directories. When scraping business directories, their web servers can identify repetitive requesting and put you on hold by looking at the IP address that is used for frequent http requests. Proxy rotation web service is the means for repeatedly changing IP address. Thus, target web server can only see the random IP addresses from rotating proxies pool at each request.
Categories
Make web page to auto scroll down
 Today I want to share with you how to make a web page to automatically scroll down. This is applicable in dealing with social networks pages, business directories (ex. yellow pages) and other auto-upload resources.
Today I want to share with you how to make a web page to automatically scroll down. This is applicable in dealing with social networks pages, business directories (ex. yellow pages) and other auto-upload resources.
 Recently I received a question in my mail box about scraping data aggregate sites (aka yellow pages) or business directories.
Recently I received a question in my mail box about scraping data aggregate sites (aka yellow pages) or business directories.
I replied to him directly, but our conversation on business directories was an interesting one that I thought you guys would find useful.
Here’s the question:
I am interested in scraping the database in such a website www.1881.no. My guess is that I would need a webdriver, like Selenium to do the job. I am very newbie to this field, but I believe if given some pointers, I can get some data out.
Could you please provide me with pointers on how to extract data from this website.
Sandeep
As a generic answer, I’ll provide you with some basics of scraping those business (and private life) directories.
 LinkedIn API doesn’t allow you to publish into groups if you are not their administrator. That was done in order to eliminate spamming, but if you are a member of several groups of a similar topic and you want to share some interesting information with all of those groups, you have to do it manually group by group and eventually it becomes tedious. In this post I’ll show you a simple way to automate this process in C# using Selenium WebDriver.
LinkedIn API doesn’t allow you to publish into groups if you are not their administrator. That was done in order to eliminate spamming, but if you are a member of several groups of a similar topic and you want to share some interesting information with all of those groups, you have to do it manually group by group and eventually it becomes tedious. In this post I’ll show you a simple way to automate this process in C# using Selenium WebDriver.