Is it possible to scrape an HTML page with JavaScript from inside of a web browser?
To be perfectly honest I wasn’t sure so I decided to try it out.
Full disclaimer here, I didn’t actually succeed. However, it was a great learning experience for me and I think you guys could benefit from seeing what I did and where I went wrong. Who knows, maybe you can take what I’ve done and figure it out for yourself!
You can jump to any of these methods if you like…
| CORS | No Referer header request | WordPress pages’ load |
Let’s say you’re at mysite.com (in your browser) and want to run a script to load some data from example.com. The simplest solution for requesting content via JavaScript would be to request it through an XML Http Request (XHR):
xmlhttp=new XMLHttpRequest();
xmlhttp.open("GET", "http://example.com/data/json", false);
xmlhttp.send();
var data = JSON.parse(xmlhttp.responseText);
However, this pertains to the cross-origin requests (as opposed to same-origin request), which turns out to be the unbreakable wall for requesting page content from pure JavaScript.
Same Origin Policy
Same-origin policy requires that in web requests made from the client side (mysite.com) both domain name and protocol (http, https) should be equal. So security limitations do not allow you to request another domain website (example.com) or any of its resources.
Can you bypass it? No.
You might think you can just bypass this. In order to request foreign domain resources we imitate the same domain origin. How? By obfuscating Referer header in XML Http Request, see the following:
xmlhttp.setRequestHeader("Referer","http://domain_for_scrape.com");
This is explicitly disallowed by the XHR specification. So in JavaScript XHR you can’t explicitly set up an arbitrary header.
Resources allowed to be requested from a foreign domain
Now, there are services that do allow cross-origin resource sharing. This is applicable for distributed resource sharing to diminish a server resource load. Eg. CSS stylesheets, images, and scripts might be served from foreign domain servers. Here are some examples of resources which may be embedded cross-origin:
- JavaScript with
<script src="..."></script>. Error messages for syntax errors are only available for same-origin scripts. - CSS with
<link rel="stylesheet" href="...">. - Images with
<img>. Supported image formats include PNG, JPEG, GIF, BMP, SVG. - Media files with
<video>and<audio>. - Plug-ins with
<object>,<embed>and<applet>. - Fonts with
@font-face. Some browsers allow cross-origin fonts, others require same-origin fonts. - Anything with
<frame>and<iframe>. A site can use theX-Frame-Optionsheader to prevent this form of cross-origin interaction.
One example is the jQuery code which is often served from ajax.googleapis.com domain:
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.7.1/jquery.min.js"></script>
But, to the developers’ joy the Cross-Origin Resource Sharing policy has been recently (January 2014) introduced. This allows to resolve the Same-Origin Policy restriction.
Cross-Origin Resource Sharing (CORS)
The main concept is that a target server may allow some other origins (or all of them) to request its resources. Server configured for allowing cross-origin requests is useful for the cross-domain API access of its resources.
If a server allows CORS it’ll respond with Access-Control-Allow-Origin:* header.
Access-Control-Allow-Origin: *
If a resource owner’s restricts the sharing with only a certain domain, the server will respond with:
Access-Control-Allow-Origin: http://mysite.com
You might do a preflight request to make clear if a server allows foreign domain access.
Read more of CORS here.
How to set an access control in Apach server (enabling CORS) see here.
CORS tester.
Wrap up
Eventually, site owners will allow CORS only for the API access since it’s unlikely they will make their private web data cross-origin accessable. The attempt to scrape other sites’ content with JavaScript provides a very limited scope.
No Referer form submission

We’ve mentioned before that <iframe> loading foreing data in it works by neglecting same-domain policy.
Let’s try to use the form submission with no Referer header. Most of the sites approve the request if Referer header is empty (omitted). Websites do this because they don’t want to lose sort of 1% of their traffic. So we make a simple procedure that is called for a chosen domain with requesting thru virtual form submission:
function noref_request(site_url){
var virtualForm = 'data:text/html,<form id="genform" action="http://www.' +site_url + '" method="GET"> <input type="submit" ></form> <script>genform.submit()<\/script>';
var iframe = document.createElement('iframe');
iframe.frameBorder=0;
iframe.width= window.innerWidth;
iframe.height= "350px";
iframe.seamless='seamless';
iframe.setAttribute("src", virtualForm);
document.getElementById("response").appendChild(iframe);
}
This code, when called client-side, adds new <iframe> into a web page and loads needed resource into a browser page. The whole code is here. Kind of loading.
See the following web sniffer’s shot showing the Origin header being null and no Referer header present.
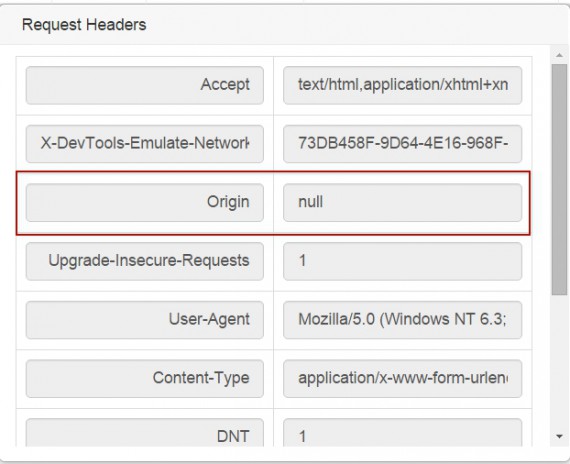
So basically you might load a foreign page into your browser page by JavaScript. But still the Same Origin Policy, applied in all major browsers, forbids access to the fetched HTML. Cross-origin contents can not be read by JavaScript. No major browser will allow that to secure against XSS attacks. Surprisingly, you can watch the cross-site request response HTML code thru browser’s web developer tools (F12, an example of using them) and manually copy/paste it:
 The loaded site will seamlessly work in an iframe, yet, you can’t have an access to its HTML. You can get the page’s screenshot as an image, but it’s not sufficient for full-scale web scraping.
The loaded site will seamlessly work in an iframe, yet, you can’t have an access to its HTML. You can get the page’s screenshot as an image, but it’s not sufficient for full-scale web scraping.
How does WordPress load foreign page shots into its admin panel
WordPress CMS can load of foreign resources with server-side call (if having access to wp-admin – just visit: <site>/wp-admin/edit-comments.php). If the user hovers a comment website link, the CMS’ JavaScript automatically invokes a request to the WordPress home server:

Now the CMS makes HTTP request to its own server, embedding the link to the foreign resource. Obviously the WordPress server makes request to the resource by provided link of interest and returns the content:

The only the thing is that the content returned by WordPress being an image: content-type: image/jpeg. You can program server to return HTML code, but that’s server-side data extraction.
Conclusion
The client-side (from your browser) scraping with JavaScript is not practical today. (1) The browser capabilities are far less compared to web servers (speed, memory, etc.). (2) The Same-Origin Policy safeguards sites from cross-origin requests, avoiding XSS attacks threat. CORS is limited scope applicable. (3) I’ve also tried to emulate the cross-domain HTTP request by a virtual form submission to load a result into an iframe, but this failed since the browser restrictions forbid scripts to handle raw response HTML cause of XSS attacks threat. (4) The last option is the indirect requesting thru a domain server (mysite.com, who actually extracts). Eg. WordPress loading foreign pages’ previews.
Feel free to add more to this topic (using comments).
15 replies on “Web scraping with JavaScript”
it is possible in Chrome browser when using
--disable-web-securitycommandline argument. No way currently on Firefox.GG, can you share how you have done it?
Greasemonkey can break the cross domain barrier by using GM_xmlhttpRequest(). It can also inject your scripts into the target page so that it scrapes itself.
I also build an online scraping site which just needs a little of js code, you can try it: http://www.datafiddle.net
Kind of a nice self-service server-side JavaScript web scraping tool. Make your code or borrow from any of premades to extract the web.
Nathan, how about looping and storing scraped data at datafiddle.net service?
I suppose browser extension is out of the article’s scope? Instead of using Cross-Origin XMLHttpRequest like an existing chrome extension, how about loading urls one by one in browser and scrape its content?
I think it’s possible to load urls one by one into browser for data extraction. But this might be hardly limited by a browser capabilities (number of tabs opened, JS processing speed, connection to DB for storing data, etc.).
Thanks for the reply. A bit of research shows some potential:
1) # of tabs opened: https://www.quora.com/What-is-the-maximum-number-of-tabs-you-can-open-in-Gmadaole-Chrome, so hundreds is practical and realistic. Say average page loading time is 10 sec, and 100 tabs loading page parallelly, that per page loading time 10s/100 = 100ms
2) JS performance: tested with a relative complex page (homepage of a news site) by extracting text content using htmlparser2, which should be the most expensive part and it costs ~100ms
3) DB performance: seems won’t be bottleneck according to https://nolanlawson.com/2015/09/29/indexeddb-websql-localstorage-what-blocks-the-dom/, as 1000 inserts takes < 1000ms in Chrome/Firefox.
So it should achieve 10 pages/sec speed in theory, and bottleneck seems to be the data extraction performance (#2).
Updates to estimate above:
1) # of tabs used: correct link is https://www.quora.com/What-is-the-maximum-number-of-tabs-you-can-open-in-Google-Chrome. I suppose it’ll be more expensive to load page with tab than simply open it, so I put 100 even though it says 10k tabs can be opened on average computer.
2) JS performance: as separate tabs can utilize multi-core, it can easily x4 or x8
I’ll need more tests for 1), but it seems not easy to go pass more than 100 pages/sec. IMO the solution is worthwhile to try out, considering it doesn’t need to setup a server to crawl 800k pages a day with 100 working tabs, and 8 million if 1000 tabs can be used.
Thanks, Xuan, for your research.
According to my experiment, I can only get around 3 pages/sec, no matter using 10 tabs or 80. My guess is the browser can only load so many pages simutaneously, no matter how many tabs are opened. Here’s the code: https://github.com/nobodxbodon/ChromeCrawlerWildSpider
No wonder. Browser is much more limited (stuffed with auxiliary loads) compare to server tools. Thanks for your experiments. Xuan, do you apply any proxying in JS scraping to prevent banning?
@Igor, I didn’t use any proxying in my limited experiment. I don’t think the crawling speed was high enough to trigger rate alarms. Just tried using extension to block images/flash in pages, speed goes up a bit but didn’t pass 4 pages/sec still.
Thank you, Xuan.